







本文简单讲述了Stream原理,并以一段比较简单常见的stream操作代码为例进行讲解。
大家都知道可以将Collection类转化成流(Stream)进行操作,代码变得简约流畅,写起来一气呵成。为什么流能支持这种流水线式工作模式,用以替代for循环呢?接下来让我们来简单探究下。
下面是一段比较简单常见的stream操作代码,经过映射与过滤操作后,最后得到的endList=["ab"],下文讲解都会以此代码为例。
List<String> startlist = Lists.newArrayList("a","b","c");List<String> endList = startlist.stream().map(r->r+"b").filter(r->r.startsWith("a")).collect(Collectors.toList());
流的三大特点
当我们查阅资料时,得到了流有三大特点:
1.流并不存储元素。这些元素可能存储在底层的集合中,或者是按需生成。
2.流的操作不会修改其数据元素,而是生成一个新的流。
3.流的操作是尽可能惰性执行的。这意味着直至需要其结果时,操作才会执行。
我们可从中捕捉到若干关键词,包括“不存储元素”,“惰性执行”等,这些含义希望读者看完流的运行流程后能找到答案。
流的运行流程
一段Stream代码的运行包括以下三部分:
1.搭建流水线,定义各阶段功能。
2.从终结点反向索引,生成操作实例Sink。
3.数据源送入流水线,经过各阶段处理后,生成结果。
整体类图介绍
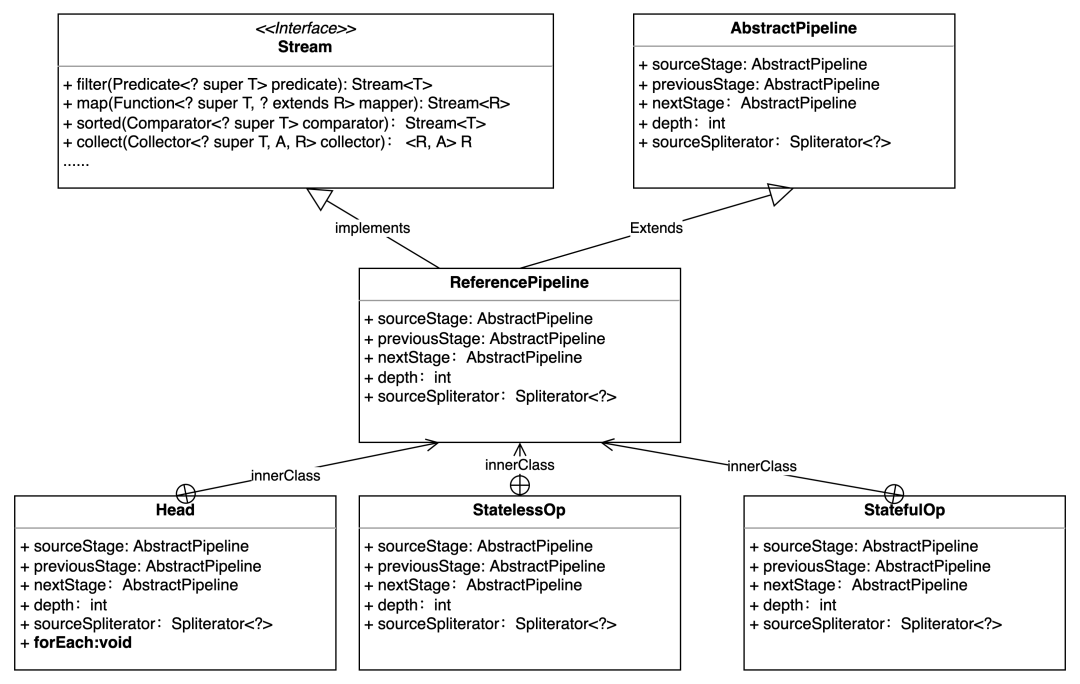
图1:Stream类图
在对原理进行介绍前,先对Stream整体类图进行介绍,帮助后续代码理解。
Stream是一个接口,它定义了对Stream的操作,主要可分为中间操作与终结操作,中间操作对流进行转化,比如对数据元素进行映射/过滤/排序等行为。终结操作启动流水线,获取结果数据。
AbstractPipline是一个抽象类,定义了流水线节点的常用属性,sourceStage指向流水线首节点,previousStage指向本节点上层节点,nextStage指向本节点下层节点,depth代表本节点处于流水线第几层(从0开始计数),sourceSpliterator指向数据源。
ReferencePipline实现Stream接口,继承AbstractPipline类,它主要对Stream中的各个操作进行实现,此外,它还定义了三个内部类Head/StatelessOp/StatefulOp。Head为流水线首节点,在集合转为流后,生成Head节点。StatelessOp为无状态操作,StatefulOp为有状态操作。无状态操作只对当前元素进行作用,比如filter操作只需判断“a”元素符不符合“startWith("a")”这个要求,无需在对“a”进行判断时关注数据源其他元素(“b”,“c”)的状态。有状态操作需要关注数据源中其他元素的状态,比如sorted操作要保留数据源其他元素,然后进行排序,生成新流。

表1:Stream操作分类
搭建流水线
首先需要区分一个概念,Stream(流)并不是一个容器,不存储数据,它更像是一个个具有不同功能的流水线节点,可相互串联,容许数据源挨个通过,最后随着终结操作生成结果。Stream流水线搭建包括三个阶段:
1.创建一个流,如通过stream()产生Head,Head就是初始流,数据存储在Spliterator。
2.将初始流转换成其他流的中间操作,可能包含多个步骤,比如上面map与filter操作。
3.终止操作,用于产生结果,终结操作后,流也就走到了终点。
定义输入源HEAD
只有实现了Collection接口的类才能创建流,所以Map并不能创建流,List与Set这种单列集合才可创建流。上述代码使用stream()方法创建流,也可使用Stream.of()创建任何数量引元的流,或是Array.stream(array,from,to)从数组中from到to的位置创建输入源。
stream()运行结果
示例代码中使用stream()方法生成流,让我们看看生成的流中有哪些内容:
Stream<String> headStream =startlist.stream();
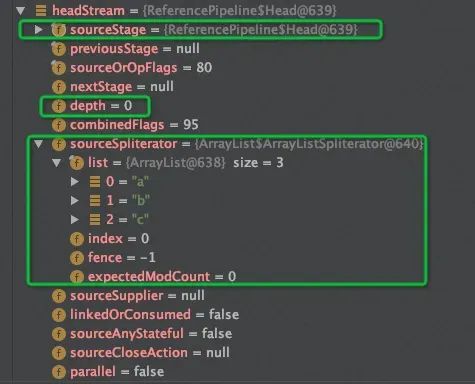
从运行结果来看,stream()方法生成了ReferencPipeline$Head类,ReferencPipeline是Stream的实现类,Head是ReferencePipline的内部类。其中sourceStage指向实例本身,depth=0代表Head是流水线首层,sourceSpliterator指向底层存储数据的集合,其中list即初始数据源。
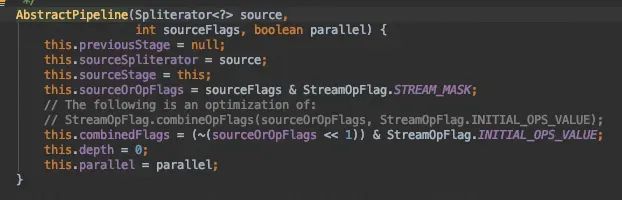
stream()源码分析

spliterator()将“调用stream()方法的对象本身startlist”传入构造函数,生成Spliterator类,传入StreamSupport.stream()方法。

StreamSupport.stream()返回了ReferencPipeline$Head类。

一路追溯至AbstractPipline中,可看到使用sourceSpliterator指向数据源,sourceStage为Head实例本身,深度depth=0。
定义流水线中间节点
Map
map()运行结果
对数据进行映射,对每个元素后接"b"。
Stream<String> mapStream =startlist.stream().map(r->r+"b");
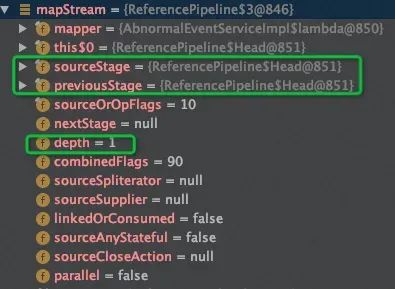
此时sourceStage与previousStage皆指向Head节点,depth变为1,表示为流水线第二节点,由于代码后续没接其他操作,所以nextStage为null。其中mapper代表函数式接口,指向lambda代码块,即“r->r+"b"”这个操作。
map()源码分析
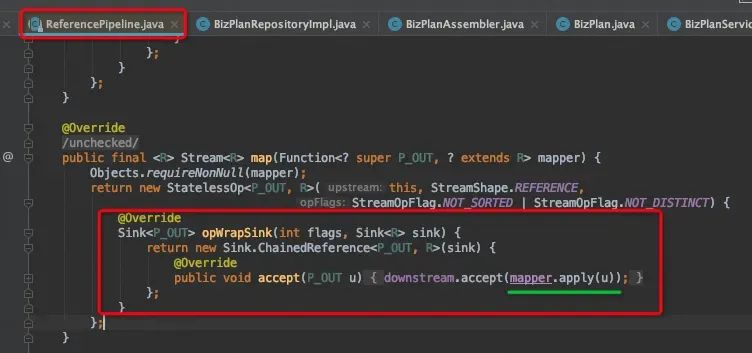
map()方法是在ReferencePipline中被实现的,返回一个无状态操作StatelessOp,定义opWrapSink方法,运行时会将lambda代码块的内容替换apply方法,对数据元素u进行操作。opWrapSink方法将返回Sink对象,其用处将在下文讲解。downstream为opWrapSink的入参sink。
Filter
filter()运行结果
filter对元素进行过滤,只留存以“a”开头的数据元素。
Stream<String> filterStream =startlist.stream().map(r->r+"b").filter(r->r.startsWith("a"));

Filter阶段的depth再次+1,sourceStage指向Head,predict指向代码块:
“r->r.startsWith("a")”,previousStage指向前序Map节点,同时可见到Map节点中的nextStage开始指向Filter,形成双向链表。
filter()源码分析

filter()也是在ReferencePipline中被实现,返回一个无状态操作StatelessOp,实现opWrapSink方法,也是返回一个Sink,其中accept方法中的predicate.test="r->r.startsWith("a")",用以过滤符合要求的元素。downstream等于opWrapSink入参Sink。
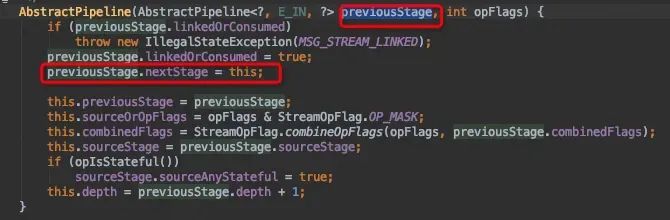
StatelessOp的基类AbstractPipline中有个构造方法帮助构造了双向链表。
定义终结操作
collect()运行结果
List<String> endList = startlist.stream().map(r->r+"b").filter(r->r.startsWith("a")).collect(Collectors.toList());
![]()
经过终结操作后,生成最终结果[“ab”]。
collect()源码分析
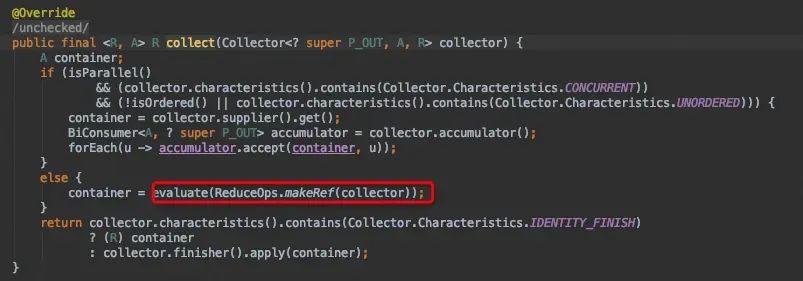
同样的,collect终结操作也在ReferencePipline中被实现。由于不是并行操作,只要关注evaluate()方法即可。
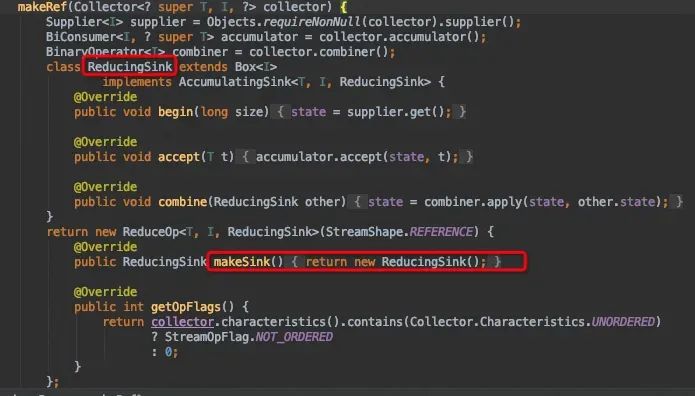
makeRef()方法中也有个类似opWrapSink一样返回Sink的方法,不过没有以其他Sink为输入,而是直接new一个ReducingSInk对象。
至此,我们可以根据源码绘出下图,使用双向链表连接各个流水线节点,并将每个阶段的lambda代码块存入Sink类中。数据源使用sourceSpliterator引用。
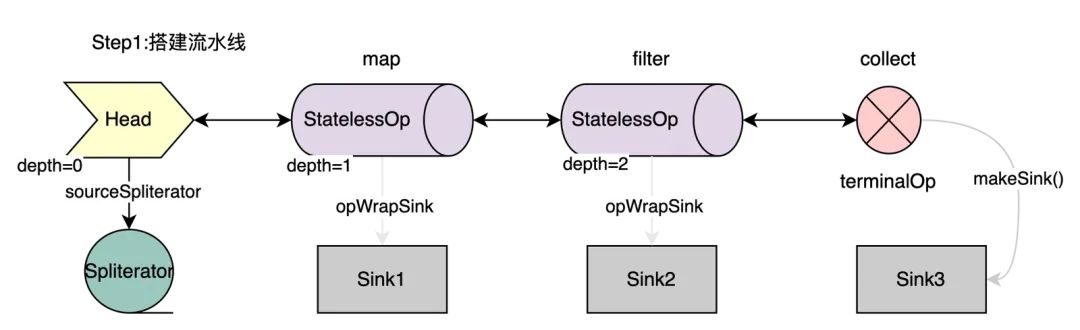
图2:流水线搭建
灰色表示还未生成Sink实例。
反向回溯生成操作实例
还记得前面说的“惰性执行”么,在一层一层搭建中间节点时,并未有任何结果产生,而在终结操作collect之后,生成最终结果endList,终结节点到底有什么魔力,让我们探究一下collect()方法中的evaluate方法。
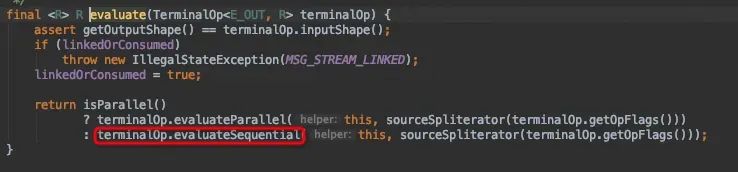

这里调用了Collect中定义的makeSink()方法,输入终结节点生成的sink与数据源spliterator。

先来看wrapSink方法,在这个方法里,中间节点的opWrapSink方法将发挥大作用,它利用previousStage反向索引,后一个节点的sink送入前序节点的opWrapSink方法中做入参,也就是downstream,生成当前sink,再索引向前,生成套娃Sink。
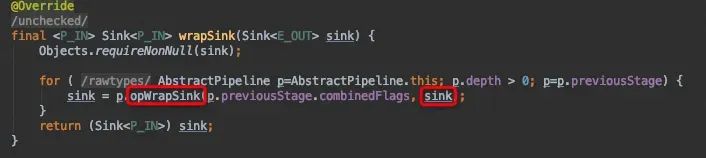
最后索引到depth=1的Map节点,生成的结果Sink包含了depth2节点Filter与终结节点Collect的Sink。
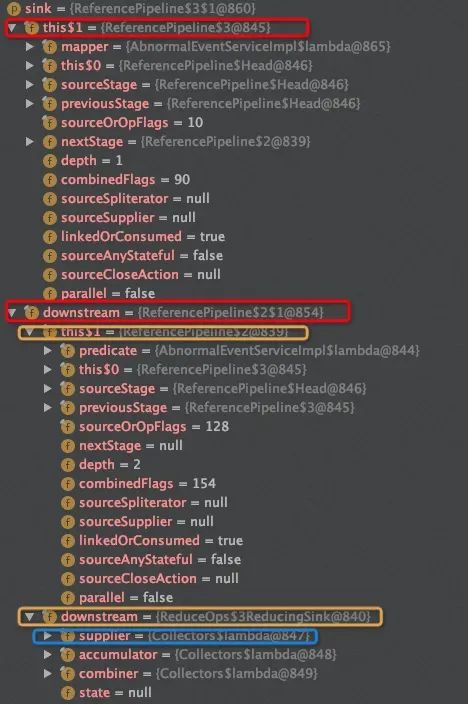
红色框图表示Map节点的Sink,包含当前Stream与downstream(Filter节点Sink),黄色代表Filter节点Sink,downstream指向Collect节点。
Sink被反向套娃实例化,一步步索引到Map节点,可以对图2进行完善。
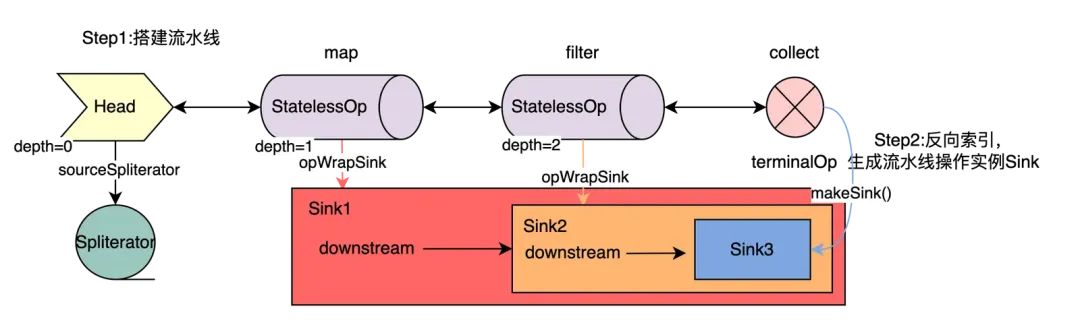
图3:反向索引生成Sink
启动流水线
一切准备就绪,就差把数据源冲入流水线。卷起来!在wrapSink方法套娃生成Sink之后,copyInto方法将数据源送入了流水线。

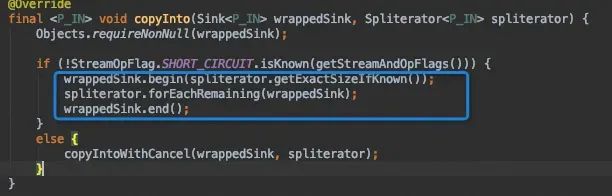
先是调用Sink中已定义好的begin方法,做些前序处理,Sink中的begin方法会不断调用下一个Sink的begin方法。
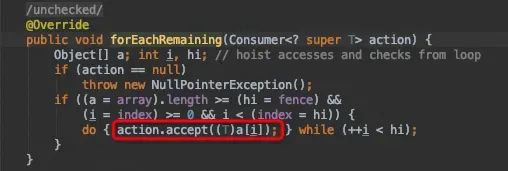
随后对数据源中各个元素进行遍历,调用Sink中定义好的accept方法处理数据元素。accept执行的就是咱在每一节点定义的lambda代码块。
随后调用end方法做后序扫尾工作。
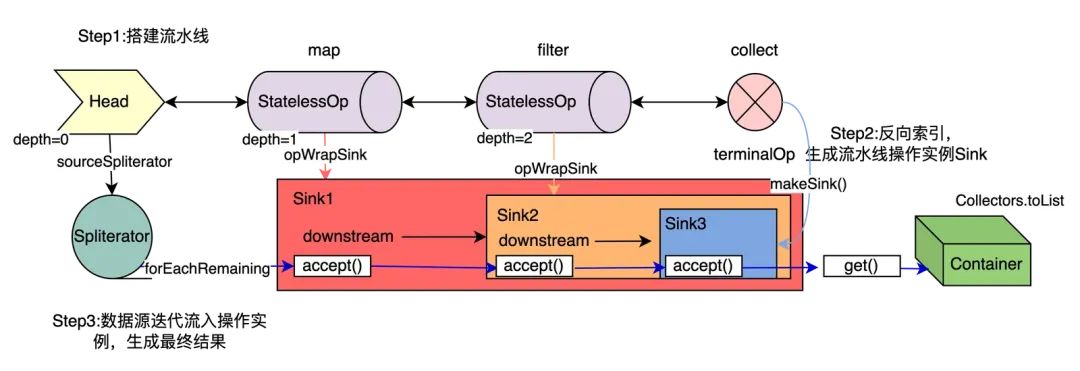
图4:数据源冲入操作实例,生成最终结果
一个简单Stream整体关联图如上所示,最后调用get()方法生成结果。
总结
本文简单讲述了Stream原理,可以看到Stream流水线就是使用双向链表将各个节点串联而成,当最终节点不为终结操作,则不会产生任何数据结果,只有遇到终结操作,才会产生数据,这就是“惰性执行”。每跟随一个节点,则会产生一个新的Stream对象,这就是“流的操作不会改变原容器中的数据元素,而是产生新流”。
参考链接:
1.书籍:《Java核心技术卷II》
2.原来你是这样的Stream:https://zhuanlan.zhihu.com/p/47478339















 199
199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









