







0.briefly speaking
时隔9个月,我又回来继续更新Xv6内核源码相关的内容了,上次更新之后经历了3个月的秋招,之后紧接着是实验室的中期检查,之后又是遥遥无期的毕业论文写作和修改,总算到现在有了一些自己的时间来继续做一些想做的事情。好久不写文章,有些内核的细节连我本人也开始有些淡忘,但好在还有之前写下的博客帮助我回忆当时的思路。这段时间我会尽可能地熟悉之前的工作思路,继续把这个专栏更新下去,希望可以帮到更多对操作系统内核感兴趣的同学和同行。在把这个专栏更新完之后,我还想继续分享更多关于操作系统内核的知识,比如FreeRTOS内核代码、Linux内核中的一些子模块等等。
书接上文,本篇博客专门研究Xv6操作系统中进程状态的切换,和一些与进程强相关的系统调用(kill, exit, sleep, wait等)。本文将从Xv6启动时对进程的初始化开始讲起,在这个过程中尝试将所有进程状态和切换动作囊括和串联进去。
本篇博客要阅读的代码文件如下:
1.kernel/proc.c <------------------- (绝大部分代码都在这里)
2.kernel/main.c
1.Xv6中的进程组和进程
在操作系统的众多书籍中,进程都是基本性的概念,它指的是一个正在由单个或者多个线程执行的程序实例(a process is the instance of a computer program that is being executed by one or many threads, quoted from WikiPedia)。在照本宣科的应试教育中,有一个经典的问题是程序(program)和进程(process)有何区别?那时的我们往往会说:程序是存储在外部存储器中的一系列静态数据和指令的集合,它是一个静态的概念,而进程是将程序从外部存储器加载到内存之后的运行实例,是一个动态的概念。
OSTEP这本书则给出了关于二者更加深邃且简洁的说明:进程(process)就是操作系统提供的对于正在运行中的程序(program)的抽象(abstraction)(The abstraction provided by the OS of a running program is something we will call a process.)。这项定义更好地阐述了进程的本质,它是操作系统引入的一种抽象层,进程作为一种抽象层带来的好处有二:1.它记录了一个运行中的程序的信息,方便操作系统更好地刻画和管理一个“运行中的程序”。2.通过将进程分时复用到CPU物理核心上,成功实现了CPU的虚拟化(Virtualization)。
下面,简单让我们来看一下Xv6是如何抽象一个“运行中的程序”的,proc结构体(kernel/proc.h:86)的定义和相关注释如下:
// Per-process state
struct proc {
// 自旋锁,用来保护一些可能被其他进程访问的敏感属性
struct spinlock lock;
// p->lock must be held when using these:
// 译:以下属性必须在持有lock的情况下才能访问
// 进程状态
enum procstate state; // Process state
// 译:如果非0,则说明当前进程正在chan上休眠
void *chan; // If non-zero, sleeping on chan
// 译:如果非0,则说明进程已被杀死
int killed; // If non-zero, have been killed
// 译:返回给父进程wait系统调用的退出状态
int xstate; // Exit status to be returned to parent's wait
// 译:进程ID号
int pid; // Process ID
// wait_lock must be held when using this:
// 译:当使用parent变量时必须持有wait_lock,这是一个全局锁
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
// 译:以下变量对于进程来说是私有的
// (意思下面的属性是说在内核代码的实现逻辑中不会被其他进程访问,而仅会被自己使用)
// 所以在使用时无需持有p->lock
// 译:内核栈的虚拟地址
uint64 kstack; // Virtual address of kernel stack
// 译:进程内存地址空间大小(以字节计)
uint64 sz; // Size of process memory (bytes)
// 译:用户态页表
pagetable_t pagetable; // User page table
// 译:trampoline.S中要使用的数据页面的物理地址
struct trapframe *trapframe; // data page for trampoline.S
// 译:swtch函数要使用的一块内存,用于切换进程时存储上下文
// 详见xv6源码完全解析系列(10)
struct context context; // swtch() here to run process
// 译:打开文件表,在文件系统一章详议
struct file *ofile[NOFILE]; // Open files
// 译:进程的当前工作目录
struct inode *cwd; // Current directory
// 译:进程名称,用于debug
char name[16]; // Process name (debugging)
};
大体而言,Xv6中进程的特征数据可分为私有数据和共有数据两大类,私有属性的访问无需锁机制保护,而公有属性在访问之前必须先获取进程锁,以防止并发带来的错误风险。从上一节Xv6的CPU复用和调度过程可以知道,Xv6中的进程可以分为作为普通程序载体的通用进程组和负责初始化和进程调度任务的调度者进程,调度者进程的上下文直接存放在CPU结构体中。而通用进程组则以全局进程组的形式存在(kernel/proc.c:11):
// 通用进程组的定义(kernel/proc.c:11)
// Xv6内核支持的最大通用进程数量由宏NPROC给出,默认值为64
struct proc proc[NPROC];
以下的故事,就是一个普通进程的前世今生了…
2.全局进程组的初始化
在Xv6启动时,每个CPU核心均会进入main函数(kernel/main.c:10),并在此完成一些内核数据结构的初始化任务,main函数的一部分代码逻辑如下:
void
main()
{
if(cpuid() == 0){
// 以上初始化动作从略
// 初始化物理内存分配器
// 细节详见xv6源码完全解析系列(4)
kinit();
// 初始化内核页表
// 注意在这里已经为每个进程的内核栈映射了对应的物理内存页面
// 并在内核页表中建立了对应的映射关系
// 细节详见xv6源码完全解析系列(1)
kvminit();
// 启动分页机制
// 细节详见xv6源码完全解析系列(1)
kvminithart();
// 初始化进程组
procinit();
// 以下初始化动作从略
} else { // application core的初始化动作
// 从略
}
}
上述代码中kvminit函数有这样一条调用链(kvminit -> kvmmake -> proc_mapstacks),在proc_mapstacks函数(kernel/proc.c:32)中为每一个进程都分配了一个物理内存页面作为进程的内核栈,并在内核页表中建立了映射关系。这些函数的详细解释在xv6源码完全解析系列(1)中都进行了详细的解释,这里只是作为备忘,简单提及。
接下来,函数procinit(kernel/proc.c:46)来专门负责对上述的全局进程组进行初始化,它初始化了每个进程的保护锁,并将自身内核栈的地址记录到了p->kstack字段,以下是procinit函数的代码和注释:
// initialize the proc table at boot time.
// 译:在启动时初始化进程表
// procinit函数负责初始化重要的锁,并设置好进程的内核栈
void
procinit(void)
{
struct proc *p;
// 初始化pid_lock和wait_lock
// pid_lock用来保护nextpid变量
// wait_lock用来确保“唤醒执行wait调用的父进程”这个动作不丢失,具体细节请见下文
// initlock是初始化锁的动作,详见xv6源码完全解析系列(9)
initlock(&pid_lock, "nextpid");
initlock(&wait_lock, "wait_lock");
// 遍历整个进程组,初始化每个进程的锁
// 并将内核栈虚拟地址记录到进程的kstack变量中
for(p = proc; p < &proc[NPROC]; p++) {
initlock(&p->lock, "proc");
p->kstack = KSTACK((int) (p - proc));
}
}
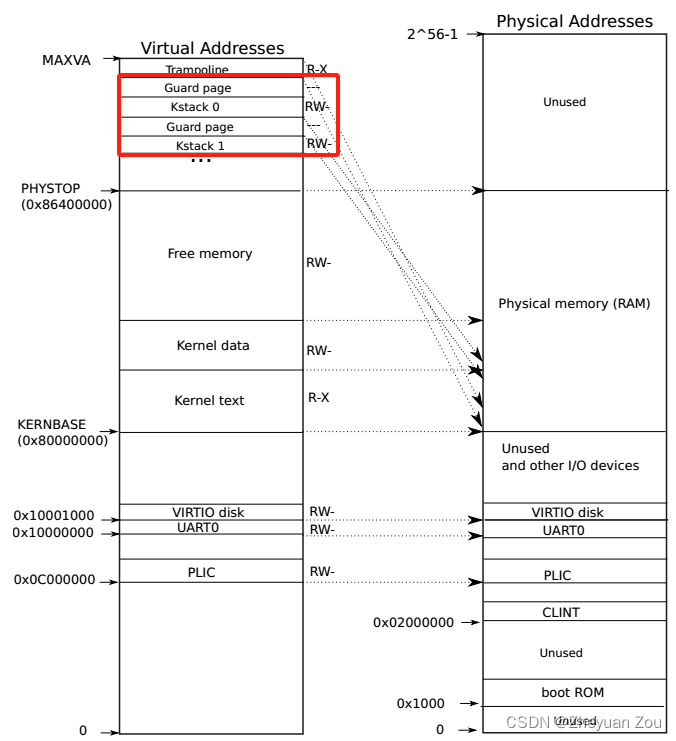
上述在初始化进程组中的每个进程的内核栈时,使用了KSTACK宏,这个宏定义如下:
// map kernel stacks beneath the trampoline,
// each surrounded by invalid guard pages.
// 译: 将内核栈映射到trampoline页面下方
// 每个页面都会被一个无效的守护页保护
#define KSTACK(p) (TRAMPOLINE - ((p)+1)* 2*PGSIZE)
这与Xv6 book中对于内核地址空间的定义是一致的,这里只当做一个简单的回顾:
由于Xv6中的进程组proc(kernel/proc.c:11)是以全局数组的形式给出的,因此结构体的各字段应当被编译器自动初始化为了0值(zero-value),所以进程的初始状态应当是0,而Xv6对于进程的6个状态的定义如下(kernel/proc.h:83),可以看到0对应于UNUSED状态:
// Xv6中对进程状态的定义
// 关于这6个状态的具体含义、它们的区别和转换关系,我会梳理在这篇博客的最后
enum procstate { UNUSED, USED, SLEEPING, RUNNABLE, RUNNING, ZOMBIE };
至此,进程组完成了初始化,可以看到现在的进程组还是一个空空的“躯壳”,里面没有实际的程序代码和数据,它在等待着程序的载入,那样才会为它注入灵魂,这个空空的躯壳对应的状态就是UNUSED。
3.新进程的产生:fork系统调用
在开始正式开始阅读fork代码之前,首先这里给出fork函数涉及到的关键函数调关系图,方便作为后续的思路梳理,请注意,为求展示上的便利性,这里没有给出错误处理代码中相关的函数调用,但在博客中会不重不漏地完整介绍每一个函数。对于图片中没有标注章节号的函数,均已在前述介绍虚拟内存时给出了详细的介绍,如有遗忘,请参照xv6源码完全解析系列(1)和xv6源码完全解析系列(2),这里只简单概括函数作用。
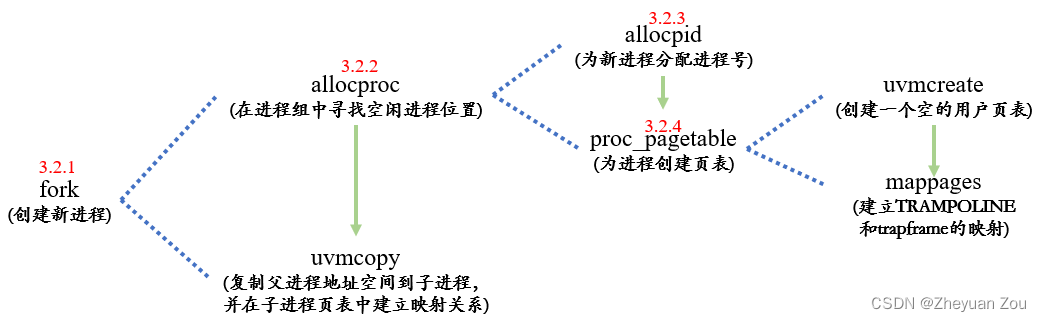
3.0 万物之始:第一个进程
老子的《道德经》说一生二、二生三、三生万物,操作系统中的进程何尝不是如此?形形色色的各类进程,它们都有一个共同祖先,这个祖先进程在系统内核启动时就会触发,并在内核运转的全程起到重要的作用。这里我本想就第一个进程做出一个系统的梳理,写了一部分后发现这部分体量有些大,还是放在Xv6内核的启动过程中进行梳理比较好。因此,这里只简单地概括一下Xv6中的祖先进程(以下称其为1号进程,因为Xv6进程编号从1开始)在启动时完成的一些事情。
Xv6中的1号进程由monitor core启动,对应代码位于函数userinit中(kernel/main.c:31),userinit会将一段二进制指令硬编码initcode(kernel/proc.c:214)复制到1号进程的虚拟地址空间中,并将指令计数器设置为0。1号进程在返回用户地址空间之后会执行这段二进制代码,它会调用init.o这个可执行文件,进而初始化命令行解释器(user/sh.c)等待用户输入命令行命令。Xv6内核解析并执行用户输入的命令时会使用fork系统调用产生新的进程,并执行(exec)命令对应的可执行程序。
3.1 sys_fork函数
在产生了第一个进程之后,新的进程就可以通过fork系统调用来创建了。关于系统调用的完整流程,请参见xv6源码完全解析系列(5),这篇文章详细介绍了Xv6系统调用的全流程。简而言之,fork系统调用在经过usertrap函数的转发之后,会进入syscall函数,进而匹配到对应的内核函数sys_fork(kernel/sys_proc.c:26),sys_fork对应的代码如下:
// sys_fork系统调用在内核的实现
// 仅仅是proc.c/fork函数的一层简单封装
uint64
sys_fork(void)
{
// 调用proc.c/fork()函数完成后续任务
return fork();
}
3.2 proc.c/fork函数
顺藤摸瓜,接下来,看看内核中的fork函数(kernel/proc.c:272)的实现,这里将首先从宏观的角度来对fork函数的作用进行说明,随后逐一地深入此函数调用的其他函数。fork函数的源码和对应的注释如下所示:
// Create a new process, copying the parent.
// Sets up child kernel stack to return as if from fork() system call.
// 译:创建一个新的进程,拷贝它的父进程
// 建立子进程内核栈来使其返回时就好像从fork系统调用返回一样
int
fork(void)
{
int i, pid;
struct proc *np;
// 取出当前进程
struct proc *p = myproc();
// Allocate process.
// 译:寻找一个(空)进程位置
// 并为其分配trapframe页面
if((np = allocproc()) == 0){
return -1;
}
// Copy user memory from parent to child.
// 译:将父进程中的用户内存拷贝到子进程
// 并建立子进程页表映射关系
// uvmcopy函数详解见xv6源码完全解析系列(2)
if(uvmcopy(p->pagetable, np->pagetable, p->sz) < 0){
freeproc(np);
release(&np->lock);
return -1;
}
// 子进程与父进程的地址空间大小一致
np->sz = p->sz;
// copy saved user registers.
// 译:拷贝保存下来的用户寄存器
// 注意fork是一个系统调用,此时trapframe中一定保存着用户态下对应的现场信息
*(np->trapframe) = *(p->trapframe);
// Cause fork to return 0 in the child.
// 译:使fork向子进程返回0
// 注意,我们编程时常使用fork函数调用的返回值来区分父进程和子进程
// 返回值为0表示子进程,返回值非0表示父进程
np->trapframe->a0 = 0;
// increment reference counts on open file descriptors.
// 译:递增打开文件表的引用计数
// 涉及文件系统的内容,敬请期待后续博客
for(i = 0; i < NOFILE; i++)
if(p->ofile[i])
np->ofile[i] = filedup(p->ofile[i]);
// 复制当前工作路径到子进程
// 递增对应索引节点的引用计数
np->cwd = idup(p->cwd);
// 拷贝父进程名到子进程
safestrcpy(np->name, p->name, sizeof(p->name));
// 获取子进程分配的新进程号
// pid将作为父进程的返回值返回
pid = np->pid;
// 释放新进程锁(此锁在allocproc函数中获取)
// 这里释放锁是为了保持先获取wait_lock再获取p->lock的
// 锁定序(lock ordering)规则
release(&np->lock);
// 在子进程中记载父进程信息
// 注意要提前获取wait_lock
// 关于wait_lock将在稍后详细解释
acquire(&wait_lock);
np->parent = p;
release(&wait_lock);
// 修改新进程的状态为RUNNABLE
// 表明当前此进程具备了被调度到物理核心上执行的一切条件
acquire(&np->lock);
np->state = RUNNABLE;
release(&np->lock);
// 返回子进程的进程号,作为父进程的返回值
return pid;
}
3.3 allocproc函数——在进程组中寻找可用的空闲进程位置
fork函数中调用了allocproc函数来寻找一个空的进程“躯壳”,allocproc函数(kernel/proc.c:104)的代码实现和注释如下。allocproc主要负责在全局进程组中寻找合适的位置来安排新的进程,一旦发现了可用的位置,则为其分配一个物理页作为trapframe页面。被选中的进程状态将会被切换为USED,表明此位置已经被抢占。
// Look in the process table for an UNUSED proc.
// If found, initialize state required to run in the kernel,
// and return with p->lock held.
// If there are no free procs, or a memory allocation fails, return 0.
// 译:查找进程表来寻找一个UNUSED状态的进程
// 如果找到了,就将其初始化为可以在内核中运行的状态,返回时依旧持有进程锁(p->lock)
// 如果没有空闲的进程,或内存分配失败,则返回0
static struct proc*
allocproc(void)
{
struct proc *p;
// 遍历进程组,寻找处于UNUSED状态的进程
for(p = proc; p < &proc[NPROC]; p++) {
// 首先获取进程锁,确保操作安全
// 如果这里不获取进程锁,那么可能会有其他进程一起抢占这个位置
acquire(&p->lock);
// 找到了一个处于UNUSED状态的进程
// 则跳转至found
if(p->state == UNUSED) {
goto found;
// 否则释放进程锁
} else {
release(&p->lock);
}
}
return 0;
// 找到UNUSED进程之后的操作
found:
// 分配一个进程ID号
p->pid = allocpid();
// 将进程状态设置为USED,表示此进程组位置已被占用
// 但实际上现在还没有载入程序的数据
p->state = USED;
// Allocate a trapframe page.
// 译:分配一页物理内存作为trapframe页面,物理地址记录在p->trapframe字段
// 关于trapframe页面,详见xv6源码完全解析系列(5)
// 若分配失败,则调用freeproc进行错误处理,并释放进程锁
if((p->trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
// 返回0表示操作失败
return 0;
}
// An empty user page table.
// 译:为进程设置准备一个新的页表
p->pagetable = proc_pagetable(p);
// 若分配失败,则调用freeproc进行错误处理,并释放进程锁
if(p->pagetable == 0){
freeproc(p);
release(&p->lock);
return 0;
}
// Set up new context to start executing at forkret,
// which returns to user space.
// 译:建立新的上下文,以在forkret开始执行
// 这回返回到用户空间
// 清空上下文context
memset(&p->context, 0, sizeof(p->context));
// 返回地址设定为forkret函数
// 当下一次该子进程被调度时,会返回到forkret函数中
p->context.ra = (uint64)forkret;
// 设置好内核栈指针的位置
// (回忆:内核栈虚拟地址在procinit函数中就已经设置好了)
p->context.sp = p->kstack + PGSIZE;
// 返回新产生的进程句柄
// 注意,此时进程锁还没有释放,回到fork函数中才释放
return p;
}
3.4 allocpid函数——为新进程分配进程号
allocproc函数中调用了allocpid函数用来为新的进程分配一个进程号,由于管理进程号的变量nextpid(kernel/proc.c:15)是一个全局变量,它记录着下一个可用的进程号,所以需要使用锁来保护。代码逻辑相对简单,在此不再赘述:
// 获取新的进程编号
int
allocpid() {
int pid;
// 首先获取pid_lock的保护锁
acquire(&pid_lock);
// 获取下一个进程号并更新next_pid
pid = nextpid;
nextpid = nextpid + 1;
release(&pid_lock);
return pid;
}
3.5 proc_pagetable函数——为给定进程创建页表
allocproc函数中调用了proc_pagetable函数来为新的进程建立新的空白页表,并在页表中建立TRAMPOLINE和trapframe的映射关系。proc_pagetable函数的代码和对应注释如下:
// Create a user page table for a given process,
// with no user memory, but with trampoline pages.
// 译:为给定的进程创建用户页表
// 不包含用户内存,但是包含trampoline页
pagetable_t
proc_pagetable(struct proc *p)
{
pagetable_t pagetable;
// An empty page table.
// 译:返回一个空的页表
// uvmcreate函数用来分配一个新的物理页并将其页面信息全部置为0
// 详解请见xv6源码完全解析系列(2)
pagetable = uvmcreate();
if(pagetable == 0)
return 0;
// map the trampoline code (for system call return)
// at the highest user virtual address.
// only the supervisor uses it, on the way
// to/from user space, so not PTE_U.
// 译:在页表中最高用户虚拟地址处映射trampoline代码(用于系统调用返回)
// 只有监视者(操作系统)在进出用户态时才会使用它,因此不要设置PTE_U标志位
// mappages函数原型如下:
// mappages(pagetable_t pagetable, uint64 va, uint64 size, uint64 pa, int perm)
// mappages会将页表pagetable中建立从va开始的size大小的虚拟内存内存与
// 从pa开始的物理内存建立映射关系,PTE中的权限位为perm,mappages会自动加上PTE_V
// 详见xv6源码完全解析系列(1)
if(mappages(pagetable, TRAMPOLINE, PGSIZE,
(uint64)trampoline, PTE_R | PTE_X) < 0){
// uvmfree函数负责释放完整的地址空间
// 包括页表页和叶级页表的所有
// 详见xv6源码完全解析系列(1)
uvmfree(pagetable, 0);
return 0;
}
// map the trapframe just below TRAMPOLINE, for trampoline.S.
// 译:将trapframe页面映射到TRAPOLINE下方
// 注意,在调用proc_pagetable函数之前
// p->trapframe已经在allocproc中分配了物理页面
if(mappages(pagetable, TRAPFRAME, PGSIZE,
(uint64)(p->trapframe), PTE_R | PTE_W) < 0){
// 失败时首先解除TRAMPOLINE页面映射关系
// 因为uvmfree中的freewalk函数要求叶级页表的映射关系全部解除
// 详见xv6源码完全解析系列(1)
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmfree(pagetable, 0);
return 0;
}
// 返回新进程的页表
return pagetable;
}
3.6 freeproc函数——重置进程状态,释放进程所有的内存
在上述两个函数中,当面临失败情况时,均会使用freeproc函数来将全局进程组中的进程重置,freeproc函数(kernel/proc.c:)的源码和注释如下:
// free a proc structure and the data hanging from it,
// including user pages.
// p->lock must be held.
// 译:将进程结构体和其上悬挂的数据释放掉
// 包括用户页面
// 在调用此函数时必须持有进程锁(p->lock)
static void
freeproc(struct proc *p)
{
// 如果已经为进程分配了trapframe,则释放之
// 回忆:(在allocproc函数中为进程分配trapframe)
if(p->trapframe)
kfree((void*)p->trapframe);
p->trapframe = 0;
// 如果进程已经拥有了页表,则释放之
// 回忆:(在fork函数中uvmcopy函数为新进程分配页表)
if(p->pagetable)
proc_freepagetable(p->pagetable, p->sz);
// 将所有状态初始化,并将状态设置为UNUSED
p->pagetable = 0;
p->sz = 0;
p->pid = 0;
p->parent = 0;
p->name[0] = 0;
p->chan = 0;
p->killed = 0;
p->xstate = 0;
p->state = UNUSED;
}
3.7 proc_freepagetable——释放进程的所有内存映射关系和已分配内存
freeproc函数中调用了proc_freepagetable函数来释放进程的所有内存,proc_freepagetable函数(kernel/proc.c:204)的源码和注释如下,它调用了uvmunmap函数和uvmfree函数来释放进程页表中的映射关系和已分配内存。
// Free a process's page table, and free the
// physical memory it refers to.
// 译:释放进程的页表,并释放它所对应的物理内存
void
proc_freepagetable(pagetable_t pagetable, uint64 sz)
{
// uvmunmap函数原型如下:
// uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
// 它可以解除页表pagetable中从虚拟地址va开始连续npages个页面的映射关系(*pte=0)
// 当do_free标识为1时,它会一并释放pte对应的物理内存
// 此函数详解见xv6源码完全解析系列(2)
// 这里只需要解除TRAMPOLINE和TRAPFRAME的映射关系,因为TRAPOLINE页面不能被删除
// 而TRAPFRAME页面在此时已经被释放或者未分配成功,无需释放
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
// uvmfree函数是uvmunmap和freewalk的封装
// 专门用来解除所有映射关系
uvmfree(pagetable, sz);
}
3.8 forkret函数——新进程首次从内核中返回到用户态
在allocproc函数创建一个新的进程时,会将其上下文中的ra寄存器的值设置为forkret函数(kernel/proc.c:141),这意味着当新进程被调度时,它会从forkret函数开始执行。forkret函数(kernel/proc.c:507)的代码实现和注释如下,它是新进程上CPU执行的第一个函数:
// A fork child's very first scheduling by scheduler()
// will swtch to forkret.
// 译:fork出的子进程首次被scheduler()函数调度时
// 将会切换上下文到forkret函数
void
forkret(void)
{
// 注意,first是静态变量,生命期会持续
// first表明是否是第一次进入forkret函数
static int first = 1;
// Still holding p->lock from scheduler.
// 译:依旧持有scheduler中抢占的锁
// 这里将scheduler函数中抢占的锁释放
release(&myproc()->lock);
// 如果是首次进入此函数
// 则做一些与文件系统相关的初始化
// 这里不深入讲解,等到后续进入文件系统时再叙
if (first) {
// File system initialization must be run in the context of a
// regular process (e.g., because it calls sleep), and thus cannot
// be run from main().
// 译:文件系统的初始化必须在一个常规进程的上下文中进行(因为它调用了sleep函数)
// 因此不可以从main函数中执行
first = 0;
fsinit(ROOTDEV);
}
// 调用usertrapret函数从用户态陷阱中返回
// 此函数将会设置好重要寄存器的信息,并将内核的一些重要信息录入trapframe
// 在这里首次将新进程的stvec寄存器值设置为了uservec的地址
// 为下一次从用户态跳入内核做好准备
// 详见xv6源码完全解析系列(5)
usertrapret();
}
最终,fork系统调用创建的新进程将会返回到用户态,和创建它的父进程一样,fork出的子进程将会从系统调用指令ecall的下一条指令开始执行。至此,一个新的进程诞生并开始运转了。接下来,我们接着去看看与进程状态改变相关的其他系统调用。
4.进程的自然退出——exit系统调用
在Xv6操作系统中,必须在用户态下显式调用exit()函数才可以结束一个进程,这一点在之前完成实验一时实验指导书已经给过我们提醒,这篇StackOverflow的问答进一步地讨论了在Xv6内核中为何要使用exit代替return的原因,有兴趣可以扩展阅读一下。(简单来说,Xv6中的新进程是通过fork创建,并通过exec系统调用载入程序镜像的,并不存在更上一层的进程来调用一个新的进程,所以return是没有意义的。)
4.1 sys_exit函数
和fork函数一样,exit也是一个系统调用,它在内核中对应的实现sys_exit(kernel/sysproc.c:10),其代码和注释如下,它在代码内部进一步调用了exec函数(kernel/proc.c:339)来进一步处理传入的进程退出状态编号。
uint64
sys_exit(void)
{
int n;
// 获取exit从用户态传递而来的参数
// 解析参数过程出错则直接返回-1
if(argint(0, &n) < 0)
return -1;
// 否则调用proc.c/exit(int)来处理接下来的逻辑
exit(n);
// 这行代码永远不会到达
// 但为了能通过编译,必须加上
return 0; // not reached
}
4.2 proc.c/exit 函数——释放部分资源,过继自身子进程,将进程置为僵尸态
接下来,仔细看看exit函数完成的事情,对应的代码和注释如下,exit函数只简单地处理了一些与文件系统相关的资源释放,同时将进程p所监管的子进程全部过继给1号进程initproc,防止未来错失对子进程退出状态的监护。最后,将进程设置为僵尸态(zombie),表示此进程已经停止运行,但退出状态尚未被其父进程观察和捕获。
// Exit the current process. Does not return.
// An exited process remains in the zombie state
// until its parent calls wait().
// 译:退出当前进程,此函数不返回
// 一个已经退出的进程将进入僵尸(zombie)态
// 直到其父进程调用wait()系统调用
void
exit(int status)
{
// 获取当前进程句柄
struct proc *p = myproc();
// 如果当前进程是1号进程,则陷入panic
// 1号进程作为万物之始,在内核运转的整个过程中必须一直存在
if(p == initproc)
panic("init exiting");
// Close all open files.
// 译:关闭进程的所有打开文件
// 涉及文件系统的内容这里不过多展开
// 后续在文件系统相关博客中再进行梳理
for(int fd = 0; fd < NOFILE; fd++){
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
p->ofile[fd] = 0;
}
}
// 释放进程的当前工作路径的索引节点计数
// 这里不过多展开
begin_op();
iput(p->cwd);
end_op();
p->cwd = 0;
// 获取wait_lock
// 以防父进程错过子进程的唤醒动作
// 如果这里子进程可以成功获取wait_lock锁,可以父进程的动作同步在如下两个位置:
// 1.wait函数中的acquire(wait_lock);
// 2.sleep函数中的acquire(lk);
// 配合进程锁,可以确保wakeup操作不丢失
acquire(&wait_lock);
// Give any children to init.
// 译:将孩子过继给init进程
// 此函数将遍历进程表,将进程p的子进程交给initproc代为监管
reparent(p);
// Parent might be sleeping in wait().
// 译:父进程可能正在wait调用中睡眠
// 这里唤醒父进程使其来收集子进程的退出状态
wakeup(p->parent);
// 获取进程锁
// 注意,获取锁的顺序是先wait_lock,再p->lock
// 如果这里获取锁成功,会保证父进程卡在:
// wait函数中的acquire(&np->lock)
// 等待子进程安全地进入ZOMBIE状态后父进程才会解锁
// 父进程到那时才可以扫描全局进程表
acquire(&p->lock);
// 将进程的退出状态记录在进程的xstate字段
// 并将进程状态设置为僵尸态(zombie)
p->xstate = status;
p->state = ZOMBIE;
// 释放wait_lock
release(&wait_lock);
// Jump into the scheduler, never to return.
// 译:跳入调度者进程,该调用将永不返回
// sched函数详解请见xv6源码完全解析系列(10)
// 注意:此时进程锁(p->lock)还没有被释放,进程锁将在scheduler()函数中释放!
sched();
panic("zombie exit");
}
4.3 reparent函数——将自身所监管的子进程过继给1号进程
exit函数的实现中调用了reparent函数(kernel/proc.c:323),这个函数的代码和相关注释如下,简而言之,它将进程p的子进程全部过继给了1号进程,以防这些子进程失去父进程的监管(因为父进程将被置为僵尸态(zombie),见上述对exit函数的解释)。
// Pass p's abandoned children to init.
// Caller must hold wait_lock.
// 译:将进程p所抛弃的孩子交给init进程
// 调用者必须已经持有wait_lock
void
reparent(struct proc *p)
{
struct proc *pp;
// 遍历全局进程组
for(pp = proc; pp < &proc[NPROC]; pp++){
// 如果发现进程p的子进程,则将其父进程置为initproc
// 并唤醒init进程
if(pp->parent == p){
pp->parent = initproc;
wakeup(initproc);
}
}
}
5. 结束其他进程——kill系统调用
如果说exit系统调用是一个进程用来结束自身运行的,kill系统调用则用来结束其他正在运行的进程,它传入的参数是要杀死进程的ID号。接下来简单对其进行分析:
5.1 sys_kill函数
和上述的系统调用一样,kill系统调用在内核对应的函数实现是sys_kill(kernel/sysproc.c:76),它首先从用户态将用户传入的参数解析,这个参数对应着要杀死的进程ID号/mark>,随后调用proc.c/kill函数进行后续的处理。源代码和对应的注释如下:
uint64
sys_kill(void)
{
int pid;
// 解析传入的进程ID号
if(argint(0, &pid) < 0)
return -1;
// 调用proc.c/kill(int)函数,杀死进程号为pid的进程
return kill(pid);
}
5.2 proc.c/kill函数——置位p->killed标志,并确保进程可以被调度
proc.c/kill函数(kernel/proc.c:578)负责kill系统调用具体的功能实现,但是和预想的不一样,kill函数其实做的事情非常有限,它简单地将进程中的killed字段设置为1,并在进程组中查找对应ID号的进程,若此进程实体确实存在可释放的内容(即不为UNUSED, USED),则确保其状态为可调度的(RUNNABLE),这样要被杀死的进程才有机会上CPU执行,进而真正完成退出动作。
被杀死的进程真正的退出动作,将在其下次进入或退出内核时在usertrap函数调用exit完成(详见xv6源码完全解析系列(5)中的usertrap函数)。这本质上是出于内核安全和简化内核代码实现逻辑的一种让步,让被杀死的进程安稳地完成自身正在执行的敏感代码逻辑而到达安全地带后,再体面地“自行了结”。所以,请注意:
1.在Xv6内核中,杀死一个进程之后,进程真正退出的时机是延后且自主的,而非立即停止运行。
2.在Xv6内核中,kill系统调用不仅不是来剥夺进程资源的,甚至还要帮助进程有机会上CPU执行,这样进程才会在后续真正自我了结,killed标记才是起到决定作用的标识。
// Kill the process with the given pid.
// The victim won't exit until it tries to return
// to user space (see usertrap() in trap.c).
// 译:杀死给定进程号所对应的进程
// 被杀死的进程在尝试返回到用户空间之前不会退出
// (见trap.c函数中的usertrap())
int
kill(int pid)
{
struct proc *p;
// 遍历全局进程组
for(p = proc; p < &proc[NPROC]; p++){
acquire(&p->lock);
// 找到了对应id号的进程
if(p->pid == pid){
// 仅将其被杀死的标志(p->killed)置为1
// 没有其他额外动作,这本质上是担心强行杀死其他进程
// 而导致的不可预测的内核数据结构崩溃
// 因此是一种延迟杀死进程的绥靖策略
p->killed = 1;
// 如果进程正在休眠
// 立即打断其休眠,使其进入可以被调度的RUNNABLE状态
// 这样做是使得被杀死的进程可以被调度,进而在退出或再次进入
// 内核(usertrap函数)时完成进程的最终回收(借助于exit函数自行了结)
if(p->state == SLEEPING){
// Wake process from sleep().
// 译:将进程从sleep()中唤醒
// 将进程状态设置为RUNNABLE
// 注意,这里可能会有潜在风险,即wakeup的条件还未满足就被强制唤醒
// 关于应对措施,详细请参阅Xv6 book 7.8节:
// [对sleep的调用总是包裹在while循环中,并有对killed标志位的检测]
p->state = RUNNABLE;
}
// 成功找到了要杀死的进程,并将其killed标志设置为1
// 释放进程锁,返回0表示成功
release(&p->lock);
return 0;
}
release(&p->lock);
}
// 返回-1,表示没有找到对应ID的进程
return -1;
}
6.等待进程退出并收集信息——wait系统调用
上面我们讲解了exit系统调用和kill系统调用(其实本质都是exit系统调用),这两个系统调用都会使得进程正常退出,且自身状态被设置为zombie。zombie态表示此进程已经失去了被调度和执行的能力,但是其退出状态尚未被其父进程捕获和处理。wait系统调用就是用来等待子进程退出并捕获其退出状态的,父进程会按照子进程的退出状态不同,来判断子进程任务的执行情况,进而方便处理接下来的代码逻辑。Xv6中exit系统调用的函数原型是int wait(int *status),函数的退出状态将被放入status参数对应的地址中,同时返回进程的ID号。
6.1 sys_wait函数
wait系统调用在内核中对应的实现sys_wait(kernel/sysproc.c:32)如下,它所做的事情就是将用户态传入的指针类型的参数解析出来,送入wait(uint64)函数中做进一步处理。
uint64
sys_wait(void)
{
uint64 p;
// 将传入的参数解析为指针类型
// 如果解析失败,则返回-1
if(argaddr(0, &p) < 0)
return -1;
// 解析成功,则调用proc.c/wait函数进行接下来的处理
return wait(p);
}
6.2 proc.c/wait函数——扫描进程表并收集子进程的退出状态
wait函数在内核中的实现逻辑较为直白,它首先会扫描一遍全局进程组,首先确认全局进程组中是否存在自己的子进程。如果不存在自己的子进程(即havekids标志位为0),则直接返回-1。当发现了待收集的子进程时,则去检查子进程的状态是否为ZOMBIE。若子进程状态为ZOMBIE则表明此进程已经正常退出,退出状态已经可以收集,这时会将进程退出状态记录下来传递给用户态,并直接调用freeproc函数释放进程体。反之,则父进程调用sleep函数陷入睡眠状态等待子进程退出。
请注意,上述流程被封装在一个死循环内,因此父进程会持续保持对子进程状态的监视,除非父进程发现没有自己的子进程而直接退出。
wait函数的流程图如下所示:
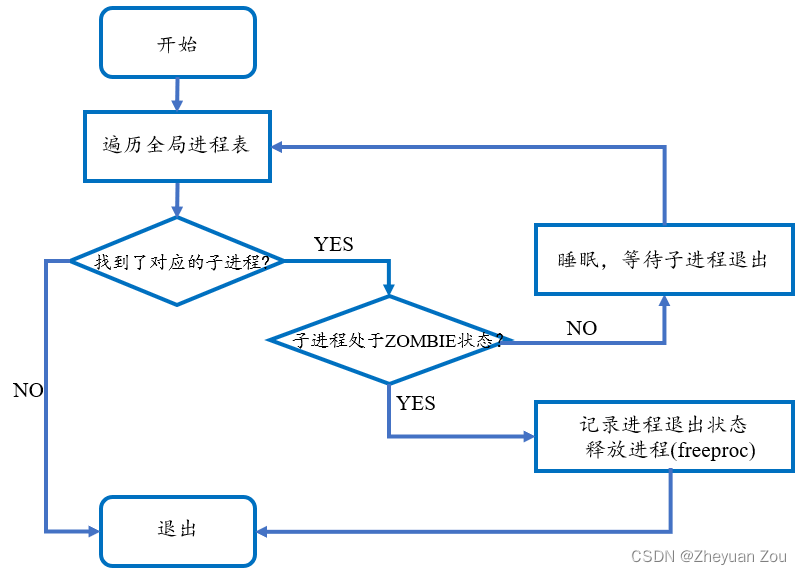
以下是对应代码及其详细注释:
// Wait for a child process to exit and return its pid.
// Return -1 if this process has no children.
// 译:等待一个子进程退出,并返回它的进程ID
// 返回-1时表示此进程没有子进程
int
wait(uint64 addr)
{
struct proc *np;
int havekids, pid;
struct proc *p = myproc();
// 获取wait_lock之后,才可以保证没有lost wakeup问题
// 如果父进程成功在此获取了wait_lock锁,会一直到父进程进入sleep函数才放弃
// 子进程的动作将被同步在:
// exit操作中的acquire(&wait_lock);
acquire(&wait_lock);
// 死循环,持续对全局进程组进行扫描
for(;;){
// Scan through table looking for exited children.
// 译:扫描整个表寻找已经退出的子进程
// 记录当前进程是否拥有孩子的标记
havekids = 0;
// 遍历整个进程表
for(np = proc; np < &proc[NPROC]; np++){
// 如果找到了当前进程的子进程
if(np->parent == p){
// make sure the child isn't still in exit() or swtch().
// 译:保证子进程并非处于exit()或swtch()函数中
// 这里父进程会被子进程的acquire(&p->lock)强制同步
// 直到子进程安全进入ZOMBIE状态才会解锁
// 详细分析请见7.3节
acquire(&np->lock);
// havekids是反映当前进程是否有子进程的标志
havekids = 1;
if(np->state == ZOMBIE){
// Found one.
// 译:找到了一个要回收的子进程
// 如果当前进程np的父进程是p(由上述np->parent == p确保)
// 且np的状态为ZOMBIE,表示找到了一个等待当前父进程p回收的子进程
pid = np->pid;
// 将进程的退出状态复制到addr指定的地址中
// 这个地址对应着在用户态下传入的int *status
// 关于copyout函数的详解请见xv6源码完全解析系列(3)
if(addr != 0 && copyout(p->pagetable, addr, (char *)&np->xstate,
sizeof(np->xstate)) < 0) {
// 若不成功,按获取锁的逆序依次释放之前已经持有的锁
release(&np->lock);
release(&wait_lock);
return -1;
}
// 程序执行至此,准备开始释放子进程
// freeproc会重置进程状态并释放所有进程资源
// freeproc解析详见本文上述3.6节
freeproc(np);
// 释放已经持有的锁
release(&np->lock);
release(&wait_lock);
return pid;
} // end of if(np->state == ZOMBIE)
// 如果当前进程状态不是ZOMBIE,则释放当前的进程锁p->lock
// 遍历下一个进程组中的进程
release(&np->lock);
}
}
// No point waiting if we don't have any children.
// 译:如果当前进程没有任何子进程,或进程被杀死,则直接退出,不再等待
if(!havekids || p->killed){
release(&wait_lock);
return -1;
}
// Wait for a child to exit.
// 译:等待子进程退出,在wait_lock这个全局锁上休眠
// 这对应于父进程找到了其对应的子进程,但子进程尚未进入ZOMBIE态的场景
// 注意,wait_lock这个条件锁将在sleep函数内部被释放
// 这种锁机制的设计思路可参见Xv6 book 7.5节
sleep(p, &wait_lock); //DOC: wait-sleep
}
}
7.进程的条件同步机制构成要素——sleep与wakeup系统调用(※)
在xv6源码完全解析系列(9)这篇博客中,我们曾仔细分析过Xv6内核中自旋锁的实现,简单回顾一下:自旋锁使用了原子化(atomic)的Test&Set指令和内存屏障指令(Memory Fence)构建了一个朴素的锁机制(kernel/spinlock.c)。自旋锁会在条件不满足时在原地盲目等待,因此虽然实现简单,但是却效率很低。
为了避免浪费宝贵的CPU资源,在条件不满足时让等待的进程主动让出CPU给其他进程使用,而在条件满足时主动唤醒对应的进程,是一种更加合理且高效的做法。这种同步机制在Xv6 book中也被描述为条件同步机制(Conditional Synchronization Mechanism, CSM),以下我们将采用条件同步机制来泛指Xv6内核中sleep和wakeup之间的交互动作形成的同步机制。
在条件同步机制中,条件一般指某个事件是否发生(例如写进程是否向管道中写入了数据、进程是否退出等)。为了确保内核可以按照正确的顺序来处理条件的响应过程,必须使用同步机制来对进程动作加以约束。对于有着共享数据结构的条件同步场景(例如管道pipe,文件系统中的日志log),Xv6内核中往往直接借用保护这些数据结构的锁来实现条件同步,而对于父进程等待子进程退出这样不涉及共享数据结构的场景,内核就必须抽象出一把锁来完成条件同步,在等待子进程退出的场景中,这把锁就是wait_lock。
在条件同步机制中与条件相关的、负责对条件同步过程中进程动作进行定序的锁称为条件锁(conditional lock)(例如上面的wait_lock)。但请注意,在Xv6内核中,仅有条件锁无法实现条件同步机制,它需要和进程锁联合使用,才可以共同保证内核条件同步操作的正确性和完备性。下面,我们首先简要分析proc.c/sleep(kernel/proc.c:528)和proc.c/wakeup(kernel/proc.c:559)的代码实现,随后以父进程等待子进程退出这样一个简单的场景为例,对条件同步机制中条件锁+进程锁的共同作用过程进行详细分析。
7.1 proc.c/sleep函数——使进程休眠并让出CPU,释放条件锁
sleep函数完成的事情非常简单,它会首先获取进程锁,在获取到进程锁之后放弃条件锁(lk),将自身的进程状态设置为SLEEPING,并调用sched函数最终让出CPU,实现了进程的休眠。
// Atomically release lock and sleep on chan.
// Reacquires lock when awakened.
// 译:自动释放锁lock并在chan上睡眠
// 当被唤醒时重新获取锁
// 请注意,关于sleep函数的接口为什么这样设计(即为什么要在sleep中释放条件锁)
// 请参阅Xv6 book 7.5节
// 简单而言,这样设计sleep的接口可以避免lost wakeup和死锁问题
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
// 译:必须获取进程锁p->lock,这是为了可以改变进程的状态p->state
// 并在之后调用sched函数
// 一旦获取了进程锁p->lock, 我们就可以保证不会丢失任何唤醒操作
// (因为wakeup函数会对进程锁p->lock上锁)
// (所以只要获取了进程锁,就可以保证卡住wakeup操作,这将在7.3节详述)
// 因此释放lk是没问题的
// 注意:一定先获取进程锁p->lock,才可以释放条件锁lk
// 一旦这里获取p->lock成功,则会将子进程同步在:
// wakeup函数的acquire(&p->lock);
// 等到父进程进入SLEEPING状态后才会解锁
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
// 将进程置为休眠状态,并设置休眠的频道(channel)
p->chan = chan;
p->state = SLEEPING;
// 调用sched函数,之后该进程将让出CPU
// 由于处于SLEEPING状态,因此在被唤醒前此进程不会被调度
sched();
// Tidy up.
// 进程被唤醒之后在此处继续执行
// 首先它会清空之前休眠所在的频道(channel)
p->chan = 0;
// Reacquire original lock.
// 译:重新获取原始锁lock
release(&p->lock);
// 这里重新获取条件锁lk一定发生在子进程wakeup操作之后
// 这里父进程会被子进程的acquire(&wait_lock)强制同步
// 直到子进程释放wait_lock,详见7.3节
acquire(lk);
}
7.2 proc.c/wakeup函数——扫描进程表并唤醒对应频道上休眠的进程
wakeup函数完成的工作非常简单,它仅仅是一个扫描全局进程表的循环,它会检查全局进程表中休眠在特定频道chan上的进程,并将其状态设置为RUNNABLE。这样一来,被置为RUNNABLE状态的进程在下一次进程切换时就有机会被调度执行,从而达到了唤醒的作用。
// Wake up all processes sleeping on chan.
// Must be called without any p->lock.
// 译:唤醒chan上的所有进程
// 在被调用时一定不能持有进程锁(否则会有死锁风险)
// [这里指的意思是wakeup函数的调用者千万不能持有某一个其他进程的锁,
// 否则在执行下面的wakeup函数时会死锁,因为wakeup需要获取进程的锁]
void
wakeup(void *chan)
{
struct proc *p;
// 遍历全局进程组
for(p = proc; p < &proc[NPROC]; p++) {
if(p != myproc()){
// 首先获取进程锁
// 这里子进程会被父进程sleep函数中的acquire(&p->lock)强制同步
// 直到父进程安全进入SLEEPING状态才会解锁
acquire(&p->lock);
// 判断当前进程p是否在给定的频道chan上休眠
// 如果是,则将其状态置为RUNNABLE,这样该进程就拥有了被再次调度的机会
if(p->state == SLEEPING && p->chan == chan) {
p->state = RUNNABLE;
}
// 释放进程锁
release(&p->lock);
}
}
}
7.3 case study:系统调用之间的锁机制约束
相信在阅读上述的代码时,大家一定都注意到了进程相关的系统调用中复杂的锁机制。事实上,理解和品味Xv6内核中的锁机制是阅读内核源码时相当重要的任务,深刻理解内核中的锁机制带来的同步约束是能够写出安全内核代码的重要基础。事实上,上述有关进程的系统调用代码实现逻辑并不复杂,更多的注意力应当放在理解它们之间的同步机制上。
我仔细梳理了上述系统调用之间的锁约束,并将存在约束关系的地方绘制了出来,请注意有些约束关系是双向的(以双向箭头展示),而有些约束关系是单向的(以单向箭头展示)。下面是它们之间的具体约束关系:
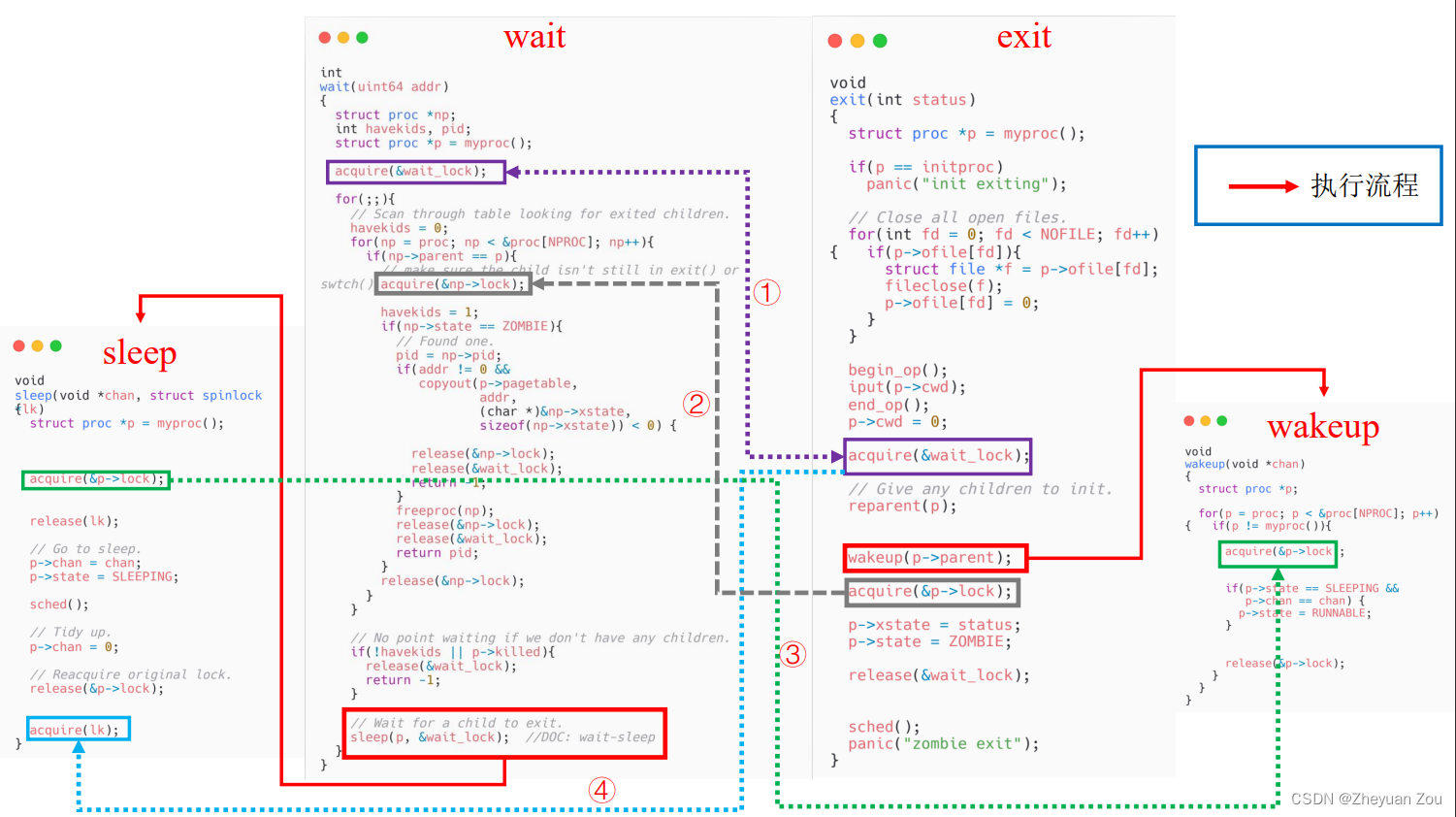
在阅读下面的内容之前,请考虑如下的两个问题,文章最后将给出解答:
Q1:是否可以去掉wait_lock?如果不能,那么wait_lock到底起到了什么作用?
Q2:在sleep函数的实现中,是否可以将acquire(&p->lock)和release(lk)两行代码顺序对调?
下面,我们按照上图中的编号,对进程系统调用中的锁进行逐一讨论:
①号约束关系(紫色框,双向约束):在父进程等待子进程退出的场景中,这把锁的作用在于避免出现lost wakeup问题,即避免父进程的sleep动作发生在了子进程的wakeup操作之后。我们来仔细分析一下为什么这个约束关系可以避免lost wakeup:
情况1:如果父进程率先获取了这把锁,则子进程会被卡在exit函数中的acquire(&wait_lock); ,这也进而会卡住子进程中位于之后的wakeup操作,断绝了子进程wakeup操作的可能。之后,父进程直到进入sleep函数之后才会释放wait_lock。但是请注意,在释放wait_lock锁之前父进程会率先获取自身的进程锁(sleep函数中的acquire(&p->lock))。这同样会导致wakeup操作被卡住(因为wakeup函数中会涉及到获取进程所的操作,如图中③绿色箭头所示),直到父进程安全地进入SLEEPING状态并释放进程锁之后,子进程的wakeup操作才会解锁并唤醒父进程。
情况2:如果子进程率先获取了这把锁,则父进程会卡在wait函数中的acquire(&wait_lock);,这进而也会卡住之后的sleep操作,断绝了父进程睡眠的可能。之后,子进程将自身状态设置为ZOMBIE之后会让出wait_lock。但是,和上面父进程在sleep函数中做的事情类似,子进程也会率先获取进程锁之后才会释放wait_lock,这会卡住父进程wait函数中的扫描全局进程表的循环体(因为扫描循环体需要获取进程锁,如图中②灰色箭头所示)。直到子进程安全地进入ZOMBIE状态并释放进程锁之后,父进程才可以解锁并顺利地扫描进程表,最终安全地找到处于ZOMBIE态的子进程。
综上所述,一旦获取了wait_lock,就一定也会获取之后的进程锁,进而完全卡住另一方的操作。这意味着将sleep和wakeup操作有效地同步了起来,要么父进程先安全休眠然后被子进程唤醒,要么父进程无需休眠直接收集已安全退出的子进程信息,别无其它可能。
②号约束关系(灰色框,单向约束):这个约束关系作用只会出现在子进程率先获取了wait_lock的情况。它规避了子进程在让出wait_lock之后但在自身安全进入ZOMBIE状态之前父进程收集子进程信息的风险,这把锁会单向地卡住父进程在循环体中获取进程锁的操作。
③号约束关系(绿色框,单向约束):这个约束关系作用只会出现在父进程率先获取了wait_lock的情况。它规避了父进程在让出wait_lock之后但在自身安全进入SLEEPING状态之前子进程就唤醒父进程的风险,这把锁会单向地卡住子进程的wakeup操作。(请原谅我是懒狗,复制上面这段话直接改的,笑:))
④号约束关系(蓝色框,单向约束):这个约束关系只会出现在父进程先休眠,随后被子进程唤醒的情况,此约束关系和①号约束关系的情况2有些类似,都是为了防止父进程进入休眠状态。子进程执行wakeup操作之前一定已经获取过wait_lock,随后在获取了子进程的进程锁之后才会释放wait_lock,而进程锁将会卡住父进程唤醒之后下一轮对全局进程表的扫描操作,直到子进程安全地进入ZOMBIE态。因此,这把锁本质上是为了防止父进程在被子进程唤醒后再次进入睡眠状态。
好啦,让我们看看开头的两个问题吧!
Q1:是否可以去掉wait_lock?如果不能,那么wait_lock到底起到了什么作用?
A1:不可以去掉wait_lock,否则只靠进程锁无法确保sleep和wakeup两个动作的有序性,会出现lost wakeup问题。要想充分理解wait_lock的作用,不妨假设去掉wait_lock锁,这时会出现以下两种错误的情况:
1.父进程扫描进程表,但是没有发现ZOMBIE态的子进程,准备进入休眠。但是在安全进入SLEEPING状态之前,子进程就执行了wakeup操作,父进程在此wakeup操作发生之后才进入了SLEEPING状态,导致错过了wakeup动作。
2.父进程扫描进程表,但是没有发现ZOMBIE态的进程,且已经安全进入了SLEEPING状态。此时子进程唤醒了父进程,由于缺乏wait_lock锁的保护,醒来的父进程即刻开始扫描进程表,而此时子进程还没有安全进入ZOMBIE状态,导致父进程再一次进入SLEEPING状态,此后将不再会有wakeup操作来唤醒父进程了。
从上面提及的两种错误情况来看,wait_lock本质上规避了lost wakeup问题,因此不可以去掉wait_lock。除此之外,wait_lock还是进程结构体种parent字段的保护锁,每当涉及到修改进程的父进程信息时,都需要先持有wait_lock才可以修改parent字段,例如fork函数以及reparent函数中的相应代码片段。所以,wait_lock既是用来保证同步的条件锁,又是某些数据结构的保护锁,请仔细品味。
Q2:在sleep函数的实现中,是否可以将acquire(&p->lock)和release(lk)两行代码顺序对调?
A2:这就是Xv6内核锁机制中相当巧妙的一点:也就是wait_lock和进程锁(p->lock)之间的交织使用。也即:要先获取进程锁,才可以释放wait_lock,进程至少持有这两把锁中的一个,这样才可以保证进程状态与具体动作顺序之间的正确性,具体而言进程锁保证了以下顺序:
1.父进程先安全进入SLEEPING状态,才会被wakeup动作唤醒。
2.子进程先安全进入ZOMBIE状态,才会被父进程收集状态。
这里简单解释一下第一种情况,如果将这两行代码对调,则在父进程释放wait_lock之后,存在子进程快速抢占wait_lock并立即进入wakeup函数的可能。此时,父进程还没有进入SLEEPING状态,因此也会出现lost wakeup的情况。而在释放wait_lock锁之前率先获取进程锁的做法则会卡住子进程的wakeup操作,进而实现了正确的同步顺序。
8.总结——进程的状态定义与转换
好了,我们终于可以总结一下进程的各个状态,以及它们的具体含义和转换方式啦,这就当作一个完美的收官吧,Xv6内核中进程相关的状态及其转换关系如下图所示:
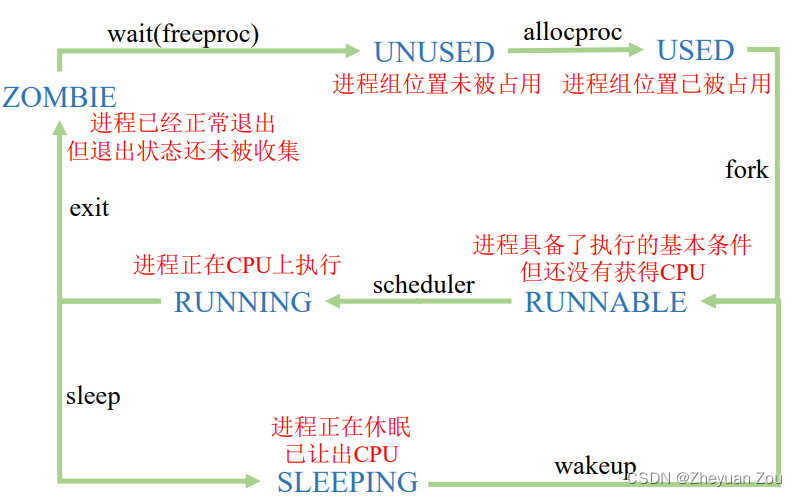
哎呀,从没想过这篇博客会写这么长,不过这篇文章算是将Xv6中与进程有关的内容彻底收了个尾,也算是可以安心地进入Xv6中最复杂和体量庞大的文件系统了!















 1263
1263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









