







第一次注意这个算法的时候是在一次刷题的过程中,看见别人的解答中提到了这个算法,然后花了一下午时间去了解了这个算法,看的懵懵懂懂,了解了个大概,然后就没有再去关注。然而前段时间面试的时候又被问了一次这个算法,距离我第一次看这个算法已经隔了好几个月了,一点都想不起来,回答的一团糟,唉,心疼自己的算法能力,现在花些时间再去理解一下这个经典的模式匹配算法----KMP算法。
第一推荐这篇阮神的博客:https://news.cnblogs.com/n/176771/
阮神的博客正如他自己所说,他真的把KMP算法以非常容易理解的方式讲述了出来,尤其图文并茂,这里选取他的关于原理的讲解部分,以便自己以后查看。以下关于KMP原理这块内容,引用自阮神。
一. KMP算法原理
有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.

一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP 算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.

已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动 4 位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移 2 位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动 4 位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动 7 位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.

"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
-"A"的前缀和后缀都为空集,共有元素的长度为0;
-"AB"的前缀为[A],后缀为[B],共有元素的长度为0;
-"ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
-"ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
-"ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
-"ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
-"ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.

"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动 4 位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
二. KMP算法的覆盖函数的理解
关于这块内容的理解,参考的是JULY大神的这篇博客:http://blog.csdn.net/v_JULY_v/article/details/6111565
这篇博客里面关于覆盖函数,也就是next数组的内容非常详细,不过看这篇博客的时候一定要注意下标是从0开始,还是从1开始。
覆盖函数(overlay_function)
覆盖函数所表征的是pattern本身的性质,可以让为其表征的是pattern从左开始的所有连续子串的自我覆盖程度。
比如如下的字串,abaabcaba
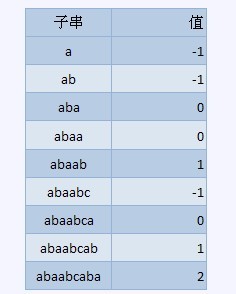
由于计数是从0始的,因此覆盖函数的值为0说明有1个匹配,对于从0还是从来开始计数是偏好问题,
具体请自行调整,其中-1表示没有覆盖,那么何为覆盖呢,下面比较数学的来看一下定义,比如对于序列
a0a1...aj-1 aj
要找到一个k,使它满足
a0a1...ak-1ak=aj-kaj-k+1...aj-1aj (也就是前子串和后子串相同)
而没有更大的k满足这个条件,就是说要找到尽可能大k,使pattern前k字符与后k字符相匹配,k要尽可能的大,
原因是如果有比较大的k存在,而我们选择较小的满足条件的k,
那么当失配时,我们就会使pattern向右移动的位置变大,而较少的移动位置是存在匹配的,这样我们就会把可能匹配的结果丢失。
比如下面的序列,
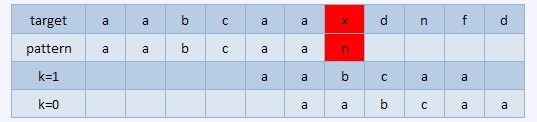
在红色部分失配,正确的结果是k=1的情况,把pattern右移4位,如果选择k=0,右移5位则会产生错误。
计算这个overlay函数的方法可以采用递推,可以想象如果对于pattern的前j个字符,如果覆盖函数值为k
a0a1...ak-1ak=aj-kaj-k+1...aj-1aj
则对于pattern的前j+1序列字符,则有如下可能
⑴ pattern[k+1]==pattern[j+1] 此时overlay(j+1)=k+1=overlay(j)+1
⑵ pattern[k+1]≠pattern[j+1] 此时只能在pattern前k+1个子符组所的子串中找到相应的overlay函数,h=overlay(k),如果此时pattern[h+1]==pattern[j+1],则overlay(j+1)=h+1否则重复(2)过程。
三. KMP算法的Java实现
public class KMP {
String pattern = null;
String target = null;
int[] nextArr = null;
public KMP(String target, String pattern){
this.pattern = pattern;
this.target = target;
this.setNextArr();
}
<span style="white-space:pre"> </span>/**<span style="white-space:pre"> </span> *实现获取第一个满足条件的下标,也就是在tIndex中的下标<span style="white-space:pre"> </span> **/
private int getFirstIndex(){
int pIndex = 0;
int tIndex = 0;
while(pIndex < pattern.length()){
if(pattern.charAt(pIndex) == target.charAt(tIndex)){
pIndex++;
tIndex++;
}else{
if(pIndex == 0){ //如果第一个字符就不相等,直接tIndex向下移动一位
tIndex++;
}else{
int tmp = nextArr[pIndex-1];
pIndex = 0;
tIndex = (tIndex-pIndex) + ((pIndex-1+1)-tmp);//(pIndex-1+1)表示的是在pIndex这个位置不相等时候,前面0~pIndex-1的子串长度
}
}
}
return tIndex-pIndex;
}
/**
* 实现获得next数组
* 关于下标:代码中是以0开始
* */
private void setNextArr() {
nextArr = new int[pattern.length()];
for(int i=0; i<nextArr.length; i++){
if(i == 0){
nextArr[i] = 0;
}else if(i == 1){
if(pattern.charAt(0) == pattern.charAt(1)){
nextArr[i] = 1;
}else{
nextArr[i] = 0;
}
}else{
for(int j=i-1; j>=0; j--){ //由子串的最大前序和最大后序开始比较
String subPre = pattern.substring(0,j+1);
String subLast = pattern.substring(i-j,i+1);
if(subPre.equals(subLast)){
nextArr[i] = j+1;
break;
}
nextArr[i] = 0;
}
}
}
}
private void printNextArr(){
System.out.println("next数组为:");
for(int tmp : nextArr){
System.out.print(tmp + " ");
}
}
public static void main(String[] args) {
KMP kmp = new KMP("ABCABCDABCABCF","ABCABCF");
kmp.printNextArr();
System.out.println("所求第一个满足条件的下标是:");
System.out.println(kmp.getFirstIndex());
}
}
这些坑,以后再补吧, ̄へ ̄















 3839
3839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









