







hosts文件修改为:
127.0.0.1 localhost
127.0.0.1 static.mediav.com
127.0.0.1 www.google-analytics.com




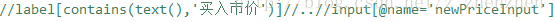
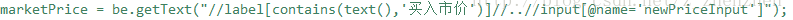


有一次利用xpath获取”登录“按钮后,点击,结果好像报错说不能点击,还是跳不过去,最后发现是好像浏览器认为我的路径部分是不能点击的,需要/..到父亲级别才可以点击。
推荐一篇文章xpath使用技巧: http://www.ibm.com/developerworks/cn/xml/x-xpath5tips/
讲的都是一些实用技巧。
5、第三方登录-iframe导致定位不到元素
最近在做UI自动化测试的时候遇到一个问题,网站支持第三方登录,如QQ,从网站进入到QQ登录页面进行的很顺利,进入之后的页面如下:
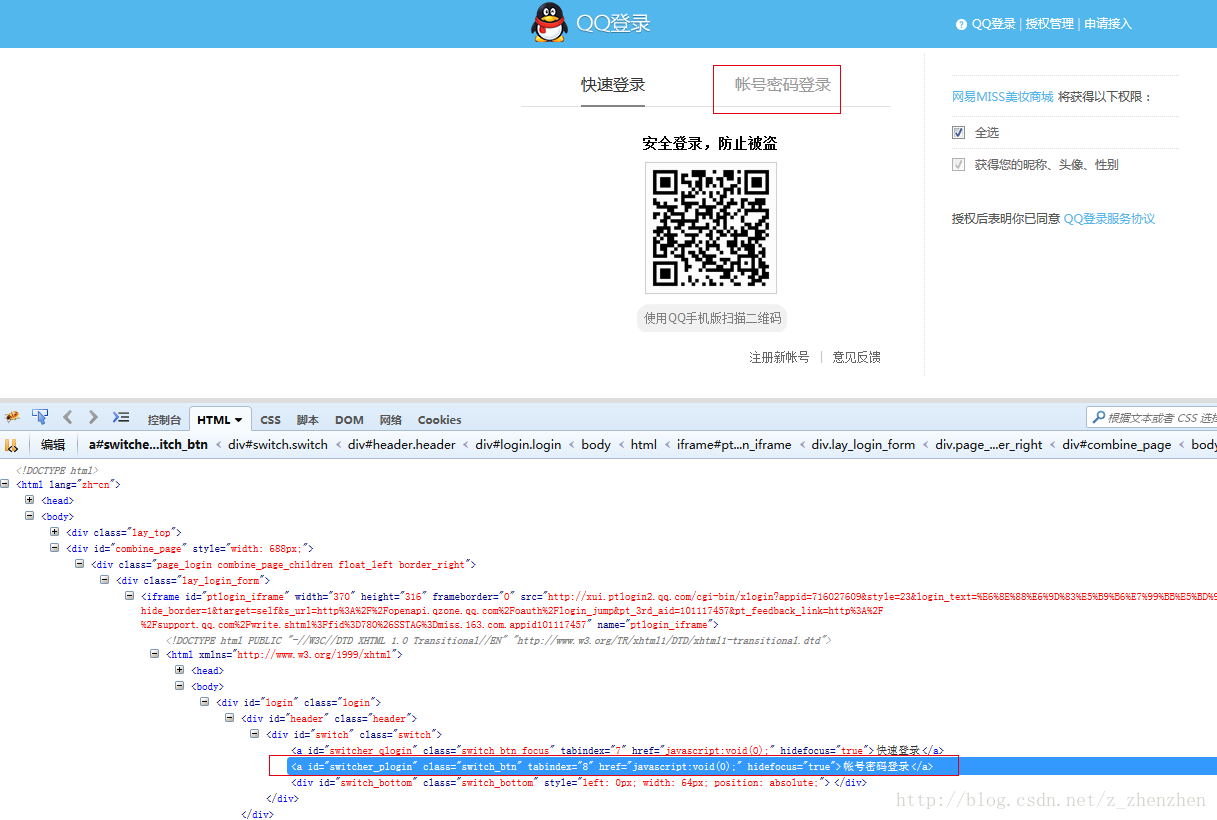
我想点击的是“账号密码”登录,firebug显示的这是一个a标签,好,直接通过xpath定位,结果,找不到。。。
想了很久不知道什么原因,问师傅,说“外面是不是有iframe”。
知道了原因就很好办了,有iframe时需要先进入iframe,才能找到想要的元素,见识太少了啊!
具体解决方法:
//先进入iframe,找到元素再点击
WebDriver driver = be.getBrowserCore();
driver.switchTo().frame("ptlogin_iframe"); //字符串为iframe的id
driver.findElement(By.id("switcher_plogin")).click();
Selenium定位不到元素的解决办法-iframe挡住了去路 http://www.blogjava.net/qileilove/archive/2014/01/02/408358.html 谢谢分享
当处理完iframe相关操作后,在进行其他后续操作前,记得移出iframe:driver.switchTo().defaultContent();
6、第三方人人登录:
具体样子是打开网站首页,点击登录,选择人人登录,会新开一个页面要求输入人人账号和密码,输入完成后点击登录会自动关闭本页面兵跳转到网站首页,流程上写完之后,运行,会看到整个流程都是按照预想的运行的,页面上也可以看到账户已登录成功,但是我没有做验证,突然加了一个验证语句,be.expectTextExistOrNot(true, "恭迎", 2000);(登录成功之后会有恭迎),但是这时候会报错,错误:org.openqa.selenium.NoSuchWindowException: no such window: target window already closed,说页面已经关闭,是啊,页面是关闭了,但是我想找的元素是在当前页面上啊。。。问题是,新开页面之后我通过 be.selectWindow(WindowTitle); 选择了新开的页面,但是当新开的页面关闭之后我并没有在程序中返回原来的页面,这样子浏览器模拟器还是在新开的页面上,所以它会说页面已经关闭了,找不到元素了,解决方法,在新开的页面关闭后返回到原来的页面。但是不能再通过选择Title的方式回去了。
这个例子介绍了可用的方法:
http://wenku.baidu.com/link?url=tRIfyv86Qv1LmT77kzXzs-Rg9X1ZyuMaIqlomXD4cqiHrsG0yHyQ885i3p6_E3n_XBw7TzioeWeYybXccpFe4bn1fcnB13kiPrj6K_pufcy
我的实现:
在页面转换到新页面前先获取当前窗口的句柄,
String currentWindow = be.getBrowserCore().getWindowHandle();
...............
处理完成后,再返回到原来的页面
be.getBrowserCore().switchTo().window(currentWindow);
总结:自动化是电脑来实现的,代码是死的,你让它干嘛它就干嘛,记住了,页面转换之后你不让它转回去它是不会自己回去的。
7、xpath 定位规律:
如果元素有id那就用id;
没有id那么可以看看class是不是唯一的;
再搞不定那就先找准一个祖先节点,然后往它的子孙找直到到达目标元素
//div[@class=' param f-cb '][1]//li[1]/a子孙,难以直接定位
8、一个输入框,显示数字,html的显示如下:
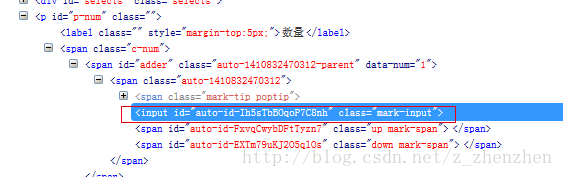
没有显示数字,现在要获取输入框中的数字,普通的直接getText()是行不通的,方法:
这个输入框的数字是通过input的value属性来显示的,所以需要获取的是input的value属性。
获取值:be.getBrowser().getValue("//input[@class='mark-input']");
现在有一个需求是要修改数字,直接be.type会在1后边添加,即如果输入5,会变成15
用js运行,be.getJavaScriptExecutor().executeScript("return document.getElementsByClassName('mark-input').value=" + numString);不会改变(不确定代码是否对)
最终解决办法:
WebElement webElement = be.getBrowserCore().findElementByXPath("//input[@class='mark-input']");
//先输入退格键,清除原来的1
webElement.sendKeys(Keys.BACK_SPACE);
webElement.sendKeys(numString);
输入新的数字前,先利用退格键删除原来的1,然后再输入。
总结:这几天其实遇到的都是一些定位获取元素及元素值的问题,看起来都是一些小问题,但是第一次遇到的时候会浪费很多时间,因为没有经验不知道如何下手,检查很久也不一定能找到问题,个人感觉UI自动化受外界影响要多一点,需要多锻炼。
通过这几天写代码,也发现了自己的缺点:
1、需要多总结一些经验;
2、前端知识不够了解,像js之类的,有空需要好好学习一下;
3、对Selenium的API不熟悉。现在写代码都是想要什么的时候去查找,并不知道Selenium到底提供了哪些方法,没有从总体上掌握,这个需要加强。
9、一个异常 org.openqa.selenium.StaleElementReferenceException: stale element reference: element is not attached to the page document
意思就是Element已经过时,没有和当前页面进行绑定,主要是页面刷新或者跳转引起的。需要重新获取一次元素。
我的代码是按照步骤来操作的,可能是由于操作过快,前一个点击了但是页面还没来得及反应,下一个执行一半的时候页面反应了,所以导致元素过期,这个只需要上一个操作完成后等待一下再运行下边的即可。
10、UI自动化中的一个坑
购物车中有很多商品,每一个后边对应一个删除按钮,现在要将购物车中的所有商品删除,开始时的做法是首先获取页面上删除按钮的个数,然后循环点击每一个删除,代码如下:

写完后,往购物车中加了两个商品,进行验证,哇~一次通过!!
今天,写测试用例的时候,购物车中的商品多了几个,然后清空购物车,哦MyGod,删除了两个商品之后就报错:

错误是元素不在页面上了,之前出现过这个问题,是因为页面刷新或者跳转导致了,那这地方就只能是页面进行了刷新,为什么还成功的删除了两个那?因为自动执行速度很快,在页面刷新的中间过程成功的删除了两个,这也是为什么我之前购物车中有两个商品的时候会成功的原因!!
好大的陷阱,不知道我的代码中还有多少个地方是侥幸成功的啊。。。。。
既然每删除一个商品之后页面都会刷新一次,那好了,每删除一个商品再重新获取一次吧:

11、第一个问题
- XPath 表达式
//Name[1]选择第一个<Name>元素,无论它位于 XML 文档中的何处。因此系统中若有多个name元素处于第一个,则都返回 //Document[1]/Name,这返回第一个<Document>元素的<Name>元素- (//Name)[1],该表达式选择所有的
<Name>元素,然后返回第一个元素
12、新开页面
写UI用例,遇到新开页面的情况,需要将对页面的定位在打开的页面上进行转换,方法如下:
- be.selectWindow(WindowTitle);
- 直接使用be.open(url);打开要去的页面















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









