







一:MAP集合的遍历
1:键找值
a:获取所有键的集合
b:遍历键的集合,得到每一个键
c:根据键到集合中去找值
2:键值对对象找键和值
a:获取所有的键值对对象的集合
b:遍历键值对对象的集合,获取每一个键值对对象
c:根据键值对对象去获取键和值
代码体现:
Map<String,String> hm = new HashMap<String,String>();
hm.put("it002","hello");
hm.put("it003","world");
hm.put("it001","java");
//方式1 键找值
Set<String> set = hm.keySet();
for(String key : set) {
String value = hm.get(key);
System.out.println(key+"---"+value);
}
//方式2 键值对对象找键和值
Set<Map.Entry<String,String>> set2 = hm.entrySet();
for(Map.Entry<String,String> me : set2) {
String key = me.getKey();
String value = me.getValue();
System.out.println(key+"---"+value);
}
二: ”TreeMap、TreeSet 对比 HashMap、HashSet的优缺点?“
缺点:
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap (O(1))低:
当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能(O(logN))
当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能(O(logN))
优点:
TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。treemap,如果采用默认构造方法,就是采用自然排序。如果是学生类,那就会出现错误(不知道怎么排序).需要些一个构造器接口compare
来告诉学术类怎么排序。(String和Charactor默认实现这个接口)(因为MAP里面只能是引用类型变量)
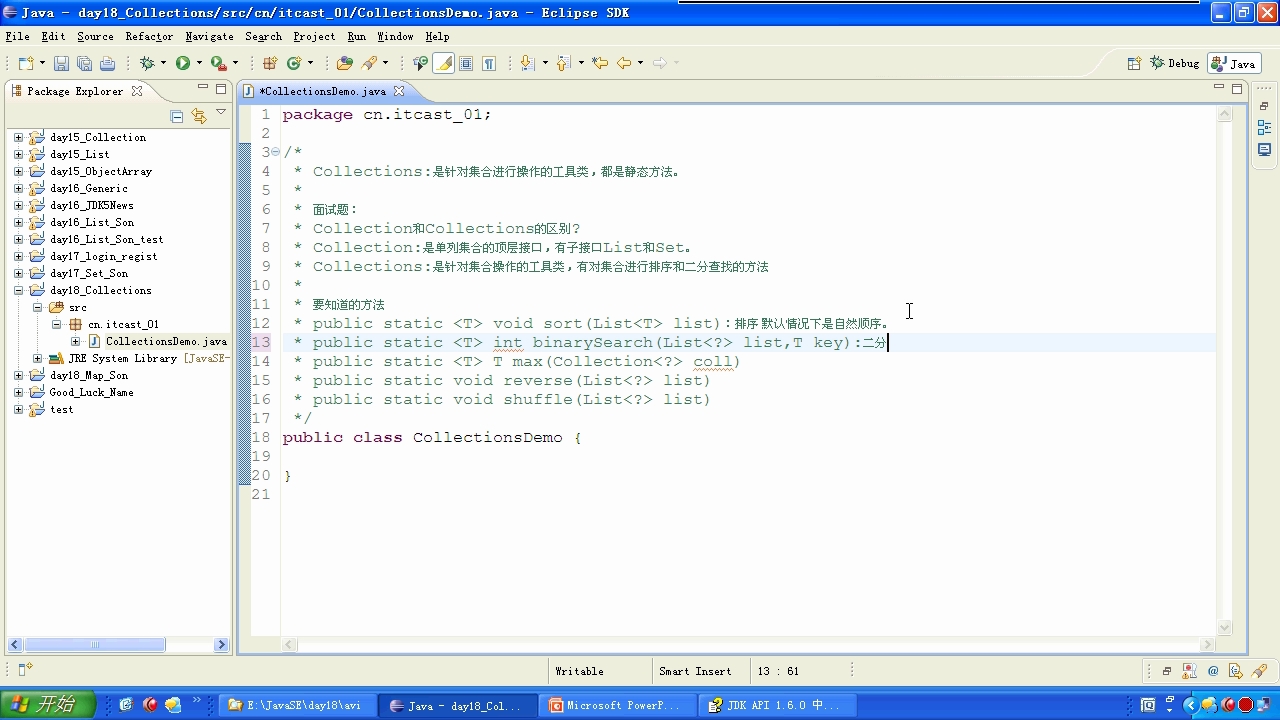
三:collection和collections的区别?
四:
TreeSet和TreeMap的关系
与HashSet完全类似,TreeSet里面绝大部分方法都市直接调用TreeMap方法来实现的。
相同点:
TreeMap和TreeSet都是有序的集合,也就是说他们存储的值都是排好序的。
TreeMap和TreeSet都是非同步集合,因此他们不能在多线程之间共享,不过可以使用方法Collections.synchroinzedMap()来实现同步
运行速度都要比Hash集合慢,他们内部对元素的操作时间复杂度为O(logN),而HashMap/HashSet则为O(1)。
不同点:
最主要的区别就是TreeSet和TreeMap分别实现Set和Map接口
TreeSet只存储一个对象,而TreeMap存储两个对象Key和Value(仅仅key对象有序)
TreeSet中不能有重复对象,而TreeMap中可以存在
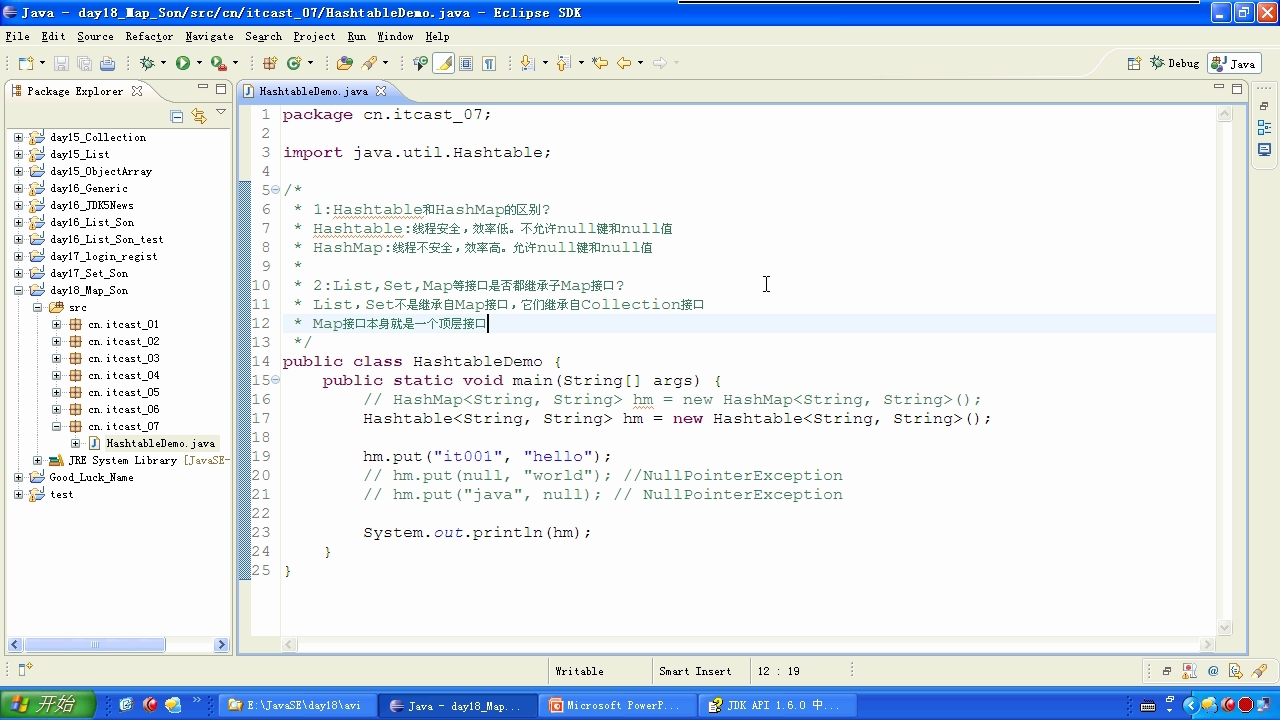
五:hashmap和hashtable(现在很少用)的区别?















 1336
1336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









