







1、安装配置JDK
1.1检查系统是否有JDK环境
[root@node jdk1.8]# rpm -qa | grep jdk
1.2卸载之前的JDK环境
[root@node jdk1.8]# rpm -e --nodeps +jdk环境
1.3 解压、重命名、配置环境变量
[hadoop@node ~]$ sudo tar -zxvf jdk-8u241-linux-x64.tar.gz -C /usr/lib/jvm
[root@node hadoop]# cd /usr/lib/jvm
重命名:
[root@node local]# sudo mv jdk1.8.0_241/ jdk1.8
vim ~/.bashrc
配置内容:
export JAVA_HOME=/usr/jdk1.8.0_241 # 配置Java的安装目录
export PATH=$PATH:$JAVA_HOME/bin # 在原PATH的基础上加入JDK的bin目录
使文件生效: source ~/.bashrc

2. Hadoop安装配置
2.1创建Hadoop用户(终端里)
[root@node hadoop]# useradd -m hadoop -G root -s /bin/bash

[root@node hadoop]# passwd hadoop
[root@node hadoop]# visudo
如下图,找到 root ALL=(ALL) ALL 这行(应该在第98行,可以先按一下键盘上的 ESC 键,然后输入 :98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行 ),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL (当中的间隔为tab),如下图所示:

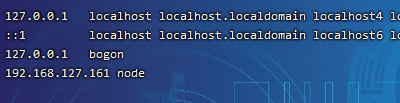
2.2修改hosts文件(重点)
该文件配置非常重要,可以在本机或者主机通过域名进行访问,同时可以在配置文件中使用使用该域名。
[root@node ~]# vi /etc/hosts
[root@node ~]# vi /etc/hostname
[root@node ~]# reboot
修改后要进行测试,如不行注销或者重启reboot
2.3安装SSH、配置SSH无密码登陆
(1)下载并启动查看:
/usr/sbin/sshd
netstat -tnulp

(2)生成密钥对: ssh-keygen ## (一直回车即可)
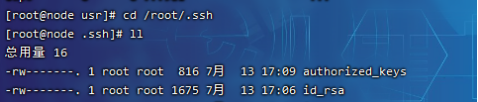
(3)将公钥放置到授权列表文件 authorized_keys中,使用命令:
cp id_rsa.pub authorized_keys
(4)修改授权列表文件 authorized_keys 的权限,使用命令:
chmod 600 authorized_keys
(5)验证免密登录是否配置成功,使用如下命令:
ssh localhost ##
(6)退出:exit
2.4 hadoop上传、解压、改名
1 进入hadoop上传文档处:
cd /home/hadoop
解压:
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local
改名:(进入解压后的文档中:eg: cd /usr/local
sudo mv hadoop-2.7.7/ hadoop
2.5环境配置
2.5.1.配置Hadoop系统变量
(1) 首先打开/etc/profile文件(系统环境变量:对所有用户有效):
vim ~/.bashrc
(2) 在文件底部添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 在原PATH的基础上加入Hadoop的bin和sbin目录
(3)生效环境变量:
source ~/.bashrc
验证:
[hadoop@node hadoop]$ ./bin/hadoop version

2.5.2.配置HDFS
1.配置hadoop-env.sh,修改JAVA_HOME参数位置;
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
(找到JAVA_HOME参数位置,修改为本机安装的JDK的实际位置:)

2.配置核心组件core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml
配置内容:(注意主机名)
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 用于指定NameNode的地址 -->
<value>hdfs://node:9000</value>
</property>
<!-- Hadoop运行时产生文件的临时存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoopData/temp</value>
</property>
</configuration>
3.配置文件系统hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
配置内容:
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoopData/name</value>
</property>
<!-- DataNode在本地文件系统中存放块的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoopData/data</value> </property>
<!-- 数据块副本的数量,默认为3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
2.5.3配置yarn
1. 配置环境变量yarn-env.sh
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh

2.配置计算框架mapred-site.xml
进入hadoop所在文件下:
cd /usr/local/hadoop/etc/hadoop
在$HADOOP_HOME/etc/hadoop/目录中默认无该文件,先将文件复制并重命名为“mapred-site.xml”:
cp mapred-site.xml.template mapred-site.xml
打开“mapred-site.xml”文件进行修改:
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
配置内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.配置YARN系统yarn-site.xml
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
配置内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
4.格式化文件系统
hdfs namenode -format
5.脚本一键启动集群
start-dfs.sh(hdfs)
start-yarn.sh(yarn)
start-all.sh(全部)
问题解析:
(1)格式化时 输入# bin/hdfs namenode -format后,整个日志的最后会出现

BUT

所以没有问题
(2)缺少datanode
原因:每次namenode format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空tmp一下的所有目录。
![]()
重新格式化,再启动:
![]()















 2366
2366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









