








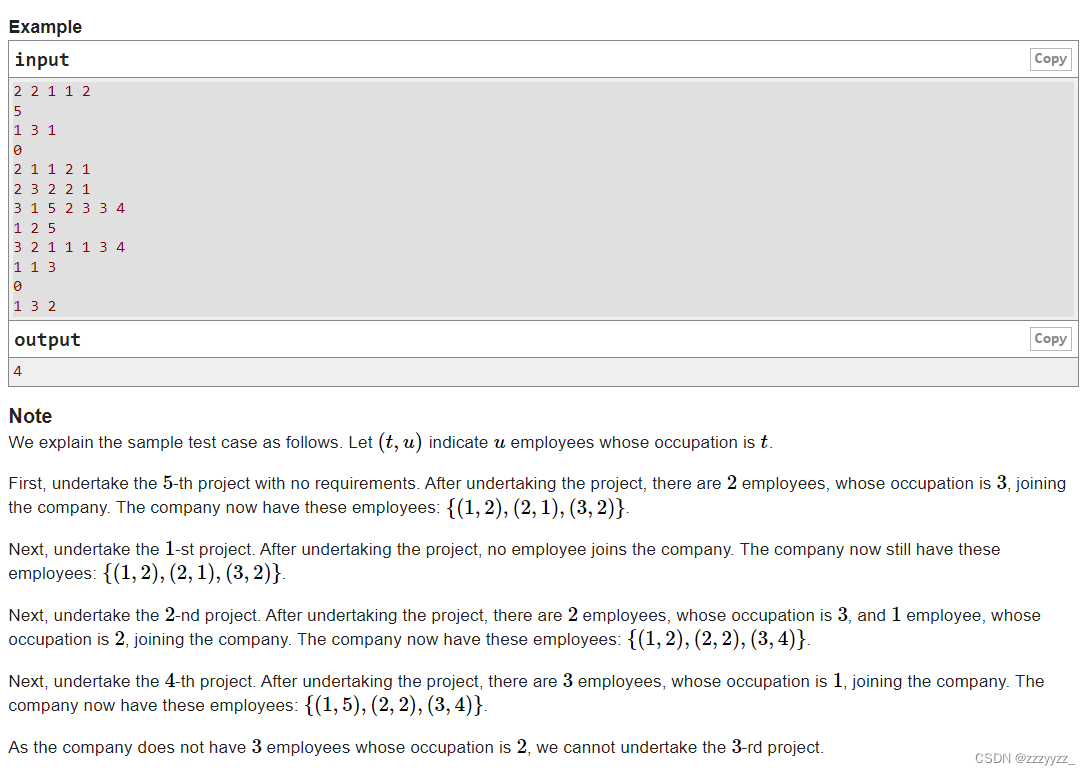
思路:我们能够发现这其实类似于操作系统的问题,其思想就是我们先把能完成的工程完成,然后加入完成工程后得到的奖励,然后再看是否会有新的工程能够完成,然后一直重复知道不会再出现新的工程能够完成,对于一个工程来说如果其中的一个需求目前已经能够满足了,那么之后是一定会满足的,所以我们就不需要再检查它是否满足了,基于这一点,我们可以考虑对所有的工种建立一个优先队列,存储哪个工程需要这个工种多少个,同时还需要标记一下当前工程还有几个需求需要满足,如果说当前工种的是数量能够满足当前需要该工种的工程的最小需求量,则将其弹出堆,同时将该工程的需求量减一,如果某个工程的需求都被满足了,那么我们就将这个工程对应的奖励添加上,同时检查一下被添加的工种再添加之后会不会满足某个工程对该工种的需求 ,直到不能够再被更新,最后只需要检查一下所有需求都被满足的工程的数量即可
// Problem: B. Building Company
// Contest: Codeforces - The 13th Shandong ICPC Provincial Collegiate Programming Contest
// URL: https://codeforces.com/gym/104417/problem/B
// Memory Limit: 1024 MB
// Time Limit: 2000 ms
#include<iostream>
#include<cstring>
#include<string>
#include<sstream>
#include<cmath>
#include<cstdio>
#include<algorithm>
#include<queue>
#include<map>
#include<stack>
#include<vector>
#include<set>
#include<unordered_map>
#include<ctime>
#include<cstdlib>
#define fi first
#define se second
#define i128 __int128
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> PII;
typedef pair<int,pair<int,int> > PIII;
const double eps=1e-7;
const int N=2e5+7 ,M=5e5+7, INF=0x3f3f3f3f,mod=1e9+7,mod1=998244353;
const long long int llINF=0x3f3f3f3f3f3f3f3f;
inline ll read() {ll x=0,f=1;char c=getchar();while(c<'0'||c>'9') {if(c=='-') f=-1;c=getchar();}
while(c>='0'&&c<='9') {x=(ll)x*10+c-'0';c=getchar();} return x*f;}
inline void write(ll x) {if(x < 0) {putchar('-'); x = -x;}if(x >= 10) write(x / 10);putchar(x % 10 + '0');}
inline void write(ll x,char ch) {write(x);putchar(ch);}
void stin() {freopen("in_put.txt","r",stdin);freopen("my_out_put.txt","w",stdout);}
bool cmp0(int a,int b) {return a>b;}
template<typename T> T gcd(T a,T b) {return b==0?a:gcd(b,a%b);}
template<typename T> T lcm(T a,T b) {return a*b/gcd(a,b);}
void hack() {printf("\n----------------------------------\n");}
int T,hackT;
int n,m,k;
int g;
ll vis[N];
vector<PII> s[N];
int po[N];
priority_queue<PII,vector<PII>,greater<PII> > q[N];
void solve() {
g=read();
int timestemp=0;
map<int,int> st;
for(int i=1;i<=g;i++) {
int a=read(),b=read();
if(st[a]==0) st[a]=++timestemp;
vis[st[a]]+=b;
}
n=read();
for(int i=1;i<=n;i++) {
int mi=read();
po[i]=mi;
for(int j=1;j<=mi;j++) {
int a=read(),b=read();
if(st[a]==0) st[a]=++timestemp;
q[st[a]].push({b,i});
}
int ki=read();
for(int j=1;j<=ki;j++) {
int a=read(),b=read();
s[i].push_back({a,b});
}
}
queue<int> sy,ti;
for(int i=1;i<=n;i++) if(po[i]==0) ti.push(i);
for(int i=1;i<=200000;i++) {
while(q[i].size()!=0&&q[i].top().fi<=vis[i]) {
po[q[i].top().se]--;
if(po[q[i].top().se]==0) ti.push(q[i].top().se);
q[i].pop();
}
}
while(sy.size()!=0||ti.size()!=0) {
while(ti.size()!=0) {
int t=ti.front();
ti.pop();
for(int j=0;j<s[t].size();j++) {
int a=s[t][j].fi,b=s[t][j].se;
if(st[a]==0) st[a]=++timestemp;
vis[st[a]]+=b;
sy.push(st[a]);
}
}
while(sy.size()!=0) {
int t=sy.front();
sy.pop();
while(q[t].size()!=0&&q[t].top().fi<=vis[t]) {
po[q[t].top().se]--;
if(po[q[t].top().se]==0) ti.push(q[t].top().se);
q[t].pop();
}
}
}
int res=0;
for(int i=1;i<=n;i++) if(po[i]==0) res++;
printf("%d\n",res);
}
int main() {
// init();
// stin();
// scanf("%d",&T);
T=1;
while(T--) hackT++,solve();
return 0;
}















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









