






简介
- eBPF全称为extended Berkeley Packet Filter,由BPF演化而来,目前已经完全取代BPF
- eBPF功能主要分为
追踪以及网络两大类
跟踪类 eBPF 程序主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。
网络类 eBPF 程序主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能。 - 具有强安全、高性能、持续交付的特点
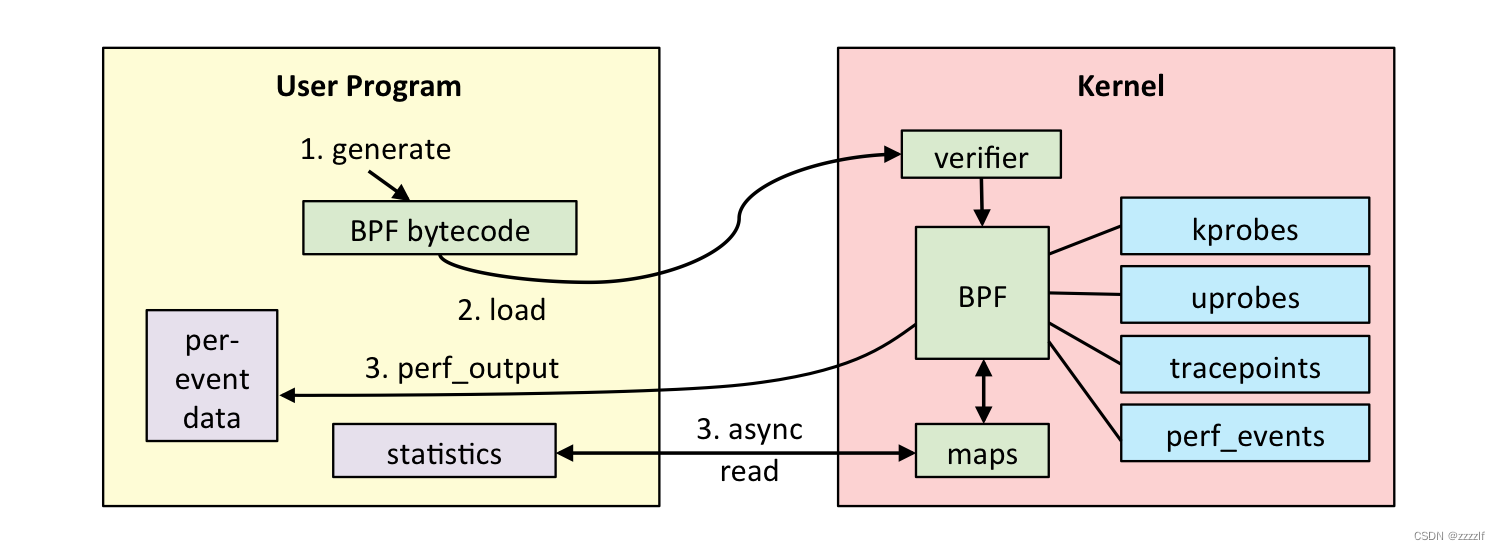
内核追踪
目前开发方式主要有以下几种,其中libbpf支持多个环境运行,bpftrace最简单。bcc依赖编译环境相对来说较为全面。
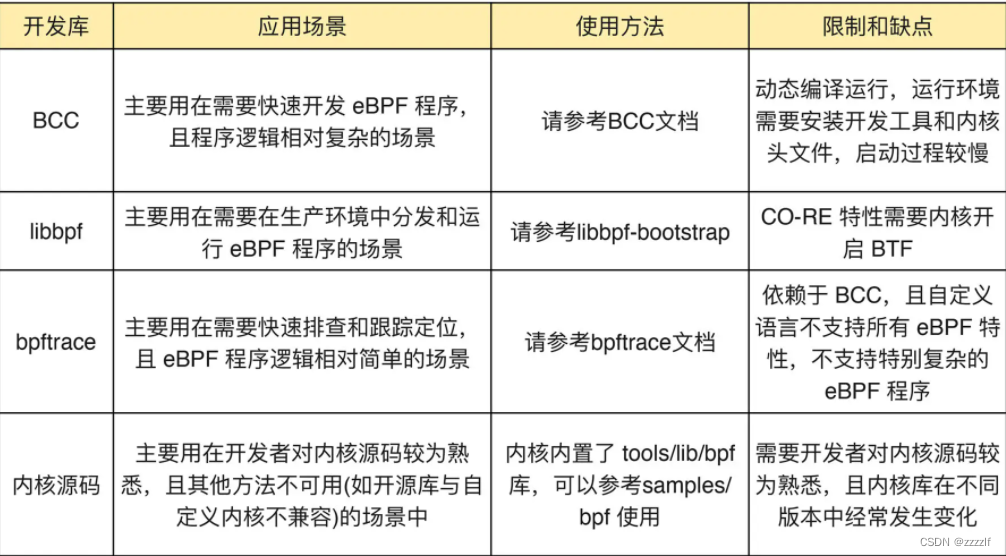
BCC 是一个 BPF 编译器集合,包含了用于构建 BPF 程序的编程框架和库,并提供了大量可以直接使用的工具。使用 BCC 的好处是,它把上述的 eBPF 执行过程通过内置框架抽象了起来,并提供了 Python、C++ 等编程语言接口。
咱们会围绕bcc工具展开介绍。
安装
在rhel 7.8以上的redhat当中,系统镜像中就带了bcc-tools工具。使用dnf install bcc-tools即可完成安装。
自带的工具会存放于/usr/share/bcc/tools目录。
开发
-
代码格式
BCC框架当中代码分为两部分,第一部分为C代码,为内核态处理逻辑,第二部分为Python,用于处理数据输出from bcc import BPF bpf_text = """ xxxxxx """ b = BPF(text=bpf_text) print "xxxxxx"知道了代码格式后,那怎么知道哪些点可以插入bpf程序呢
-
kprobes
通过cat 查看可以追踪的函数 /proc/kallsyms (不一定都可以追踪)
bpftrace -l 也可以查看
使用方式
b.attach_kprobe(event="xxx", fn_name="xxx") //event为要插桩的函数点,fn_name为触发到后需要执行的流程 -
uprobes
与kprobe类似,但是用于用户态程序插桩 -
tracepoints
tracepoints是内核定义的追踪点,内核开发者会负责维护,相对来说较为稳定。tracepoints有固定的输出内容,可以比较方便的观测。可以通过bpftrace -l命令以及cat /sys/kernel/debug/tracing/available_events来查看有哪些追踪点。
通过cat /sys/kernel/debug/tracing///format命令来观测它输出的格式,还会有示例。拿kmalloc举例。
cat /sys/kernel/debug/tracing/events/kmem/kmalloc/format
使用方式:b.attach_tracepoint("<category>:<event>", "printarg") } -
辅助函数
bpf_trace_printk()
bcc当中自带的辅助函数,适用于debug的场景,可以快速的输出信息至终端。
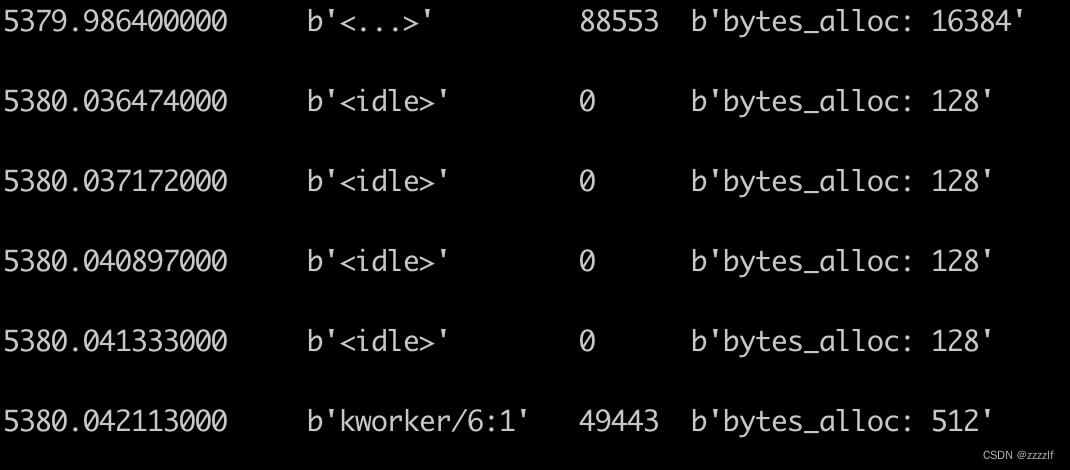
在终端界面通过tail -f /sys/kernel/debug/tracing/trace_pipe命令可以捕捉到信息。它自带了pid,时间戳,command命令。
也可以使用b.trace_fields()函数来获取trace_pipe文件当中的输出。
-
动手
有了以上这些储备知识,就可以开始动手写第一个bpf程序了。
假如系统当中有进程莫名其妙的被杀死,我们能否写一个bpf程序来检测kill是谁发起的呢?
我们来制作一个当捕捉到kill信号就会提示hello world的程序吧!步骤:1. 找到应该跟踪的插桩点或者跟踪点 2. 编写处理逻辑(输出hello world ) 3. 编写Python逻辑(需要做挂载到插桩点、输出返回两个操作)那么接下来来操作一下:
bpftrace -l | grep kill #查看插桩点,查找与kill相关的函数,可以发现__x64_sys_kill函数与我们较为相关。那么C语言部分应该如下。c语言当中给它来一个简单的print hello,world。在c当中不能直接用print,需要用刚刚提到的辅助函数bpf_trace_printk。
int hello_world(){ bpf_trace_printk("Hello, World!\\n"); return 0; }完整代码:
#!/usr/bin/python3 from bpfcc import BPF bpf_text = """ int hello_world(){ bpf_trace_printk("Hello, World!\\n"); return 0; } """ b = BPF(text=bpf_text) b.attach_kprobe(event="__x64_sys_kill", fn_name="hello_world") ##attach到挂载点 while 1: try: (task, pid, cpu, flags, ts, ret) = b.trace_fields() ##循环从bpf_trace_printk接收输出。前面task,pid,cpu,flags,ts为它固定的格式,最后的ret是上面我们指定的Hello,World!输出 except KeyboardInterrupt: ## 检测ctrl C ,退出程序 print("Detaching...") exit() print("%-18.9f %-16s %-6d %s \n" % (ts, task, pid, ret)) ## 打印我们需要的输出当然,bcctool当中已经自带了killsnoop工具,此处仅为示例。bcc工具默认位于/usr/share/bcc/tools目录下
有了以上这个简单的bpf程序后,我们来写一个更实用的程序 。设想一个场景,当系统当中一直有进程在吃内存,如何发现有什么进程在申请内存呢?
bpf提供了一个tracepoint来供我们追踪,我们用最简单的几行代码来完成它。
还是一样,先找追踪点。可以看到有许多内存相关的追踪点,明显kmalloc是我们比较想要的。如果不明确也可以百度一下相关函数。
通过cat /sys/kernel/debug/tracing/events/kmem/kmalloc/format来查看有哪些可以获取的数据,然后就可以开始开发了。

可以看到相关字段有bytes_alloc,让我们来捕捉一下它吧。#!/usr/bin/python3 from bpfcc import BPF # load BPF program bpf_text = """ TRACEPOINT_PROBE(kmem,kmalloc){ if( (size_t)args->bytes_alloc >= 128){ //把申请内存大于128bytes的打印出来 bpf_trace_printk("bytes_alloc: %d \\n", args->bytes_alloc); } return 0; } """ b = BPF(text=bpf_text) print("start......") while 1: try: #b.perf_buffer_poll() #b.trace_print() (task, pid, cpu, flags, ts, ret) = b.trace_fields() except KeyboardInterrupt: print("Detaching...") exit() print("%-18.9f %-16s %-6d %s \n" % (ts, task, pid, ret))当然,还可以捕捉page_alloc,方法也与此类似。
-
进阶用法
如果想获取某一个kernel函数传入参数的值或者函数返回的值呢?
以近期碰到的一个问题来举例b.attach_kprobe(event="blk_insert_cloned_request", fn_name="get_segments")可以看到我在blk_insert_cloned_request函数当中插了桩,当触发了此函数时,会执行get_segments的逻辑。
在C的代码当中,可以直接通过位置参数来获取它的传入参数值
查看源代码,如下图

在bpf代码当中可以直接在调用的函数当中增加两个参数,来获取传入参数的值。第一个参数必需为struct pt_regs *ctx。如下面代码所示。
int get_segments(struct pt_regs *ctx, struct request_queue *q, struct request *rq,bool no_sg_merge) { }当想获取返回值时,可以直接使用
b.attach_kretprobe(event="blk_insert_cloned_request", fn_name="get_segments_res") int get_segments_res(struct pt_regs *ctx, struct request_queue *q, struct request *rq) { int ret = PT_REGS_RC(ctx); ........................... }
网络
服务器收包流程
服务器在收到数据包后,会先放入ring buffer当中,再由kernel循环的去拉取数据。
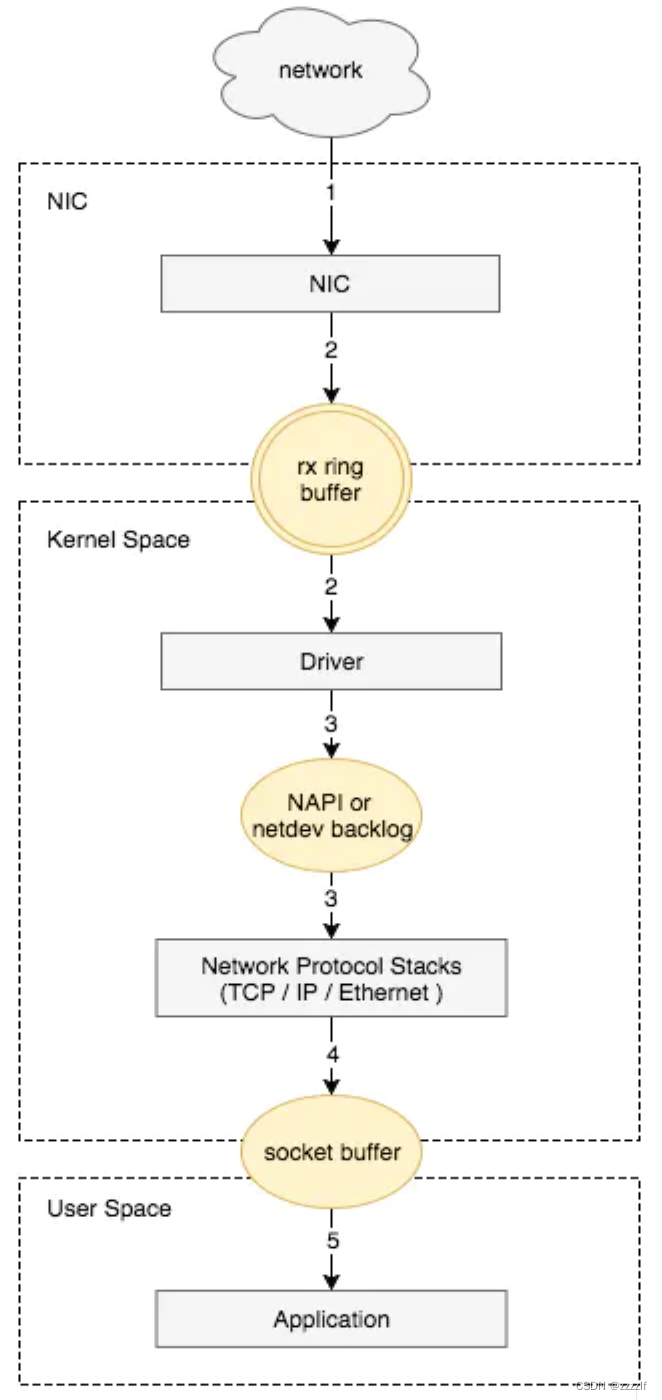
BPF可以挂载在xdp hook点,tc hook点上,下图简单描述了他们在数据传输当中的位置。

从上图当中可以很明显的看到,xdp介入点比iptables会早很多。越早处理,消耗的系统资源会越少,相对来说性能就会越高。
xdp与tc
XDP 程序的类型定义为 BPF_PROG_TYPE_XDP,它在网络驱动程序刚刚收到数据包时触发执行。由于无需通过繁杂的内核网络协议栈,XDP 程序可用来实现高性能的网络处理方案,常用于 DDoS 防御、防火墙、4 层负载均衡等场景。
TC 程序的类型定义为 BPF_PROG_TYPE_SCHED_CLS 和 BPF_PROG_TYPE_SCHED_ACT,分别作为 Linux 流量控制 的分类器和执行器。Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器等,实现了对网络流量的整形调度和带宽控制。
同 XDP 程序相比,TC 程序可以直接获取内核解析后的网络报文数据结构sk_buff(XDP 则是 xdp_buff),并且可在网卡的接收和发送两个方向上执行(XDP 则只能用于接收)
实例
通过一个简单的实例来看怎么使用ebpf控制网络
#include <linux/bpf.h>
#include <linux/if_ether.h>
#include <linux/pkt_cls.h>
#include <linux/swab.h>
#define SEC(NAME) __attribute__((section(NAME), used))
SEC("test") //表示一个代码段
int classifier(struct __sk_buff *skb)
{
void *data_end = (void *)(unsigned long long)skb->data_end;
void *data = (void *)(unsigned long long)skb->data;
struct ethhdr *eth = data; //用于安全检测,如果不加上这些代码,则无法通过bpf验证器。
if (data + sizeof(struct ethhdr) > data_end)
return TC_ACT_SHOT;
if (eth->h_proto == ___constant_swab16(ETH_P_IP)) //判断是否为ip包
return process_packet(skb);
else
return TC_ACT_OK;
}
// 数据包处理流程
int process_packet(struct __sk_buff *skb){
unsigned int len = 500;
if (skb->len >= len) //内核协议栈
return TC_ACT_SHOT;
else
return TC_ACT_OK;
}
char _license[] SEC("license") = "GPL"; //必需要有
写完后怎么挂在系统上呢?
需要安装必要的包
yum install -y make clang llvm elfutils-libelf-devel bpftool
编译
clang -O2 -emit-llvm -c foo.c -o - | llc -march=bpf -mcpu=probe -filetype=obj -o foo.o
加载到系统上,使用tc工具
tc qdisc add dev ens3 clsact
tc filter add dev ens3 ingress bpf direct-action obj foo.o sec test
使用ping -s 500测试发现无法连通,不加参数发现可以ping通。
清除
tc qdisc del dev ens3 clsact
参考
- 极客时间《eBPF 核心技术与实战》
- http://arthurchiao.art/blog/cilium-life-of-a-packet-pod-to-service-zh/
- https://arthurchiao.art/blog/understanding-tc-da-mode-zh/
水平有限,如有错误,欢迎指正















 1425
1425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









