






 本文详细解析了HashMap在JDK1.7和1.8版本中的数据结构变化,涉及数组+链表到数组+链表+红黑树的结构,以及何时转换为红黑树。讨论了多线程环境下的插入策略,以及扩容条件和性能影响。同时,解释了equals和hashCode方法的关系,以及HashMap初始化长度的选择理由。
本文详细解析了HashMap在JDK1.7和1.8版本中的数据结构变化,涉及数组+链表到数组+链表+红黑树的结构,以及何时转换为红黑树。讨论了多线程环境下的插入策略,以及扩容条件和性能影响。同时,解释了equals和hashCode方法的关系,以及HashMap初始化长度的选择理由。
1、请你说说 HashMap 的数据结构有什么区别?
jdk1.7 采用的是数组 + 链表结构:
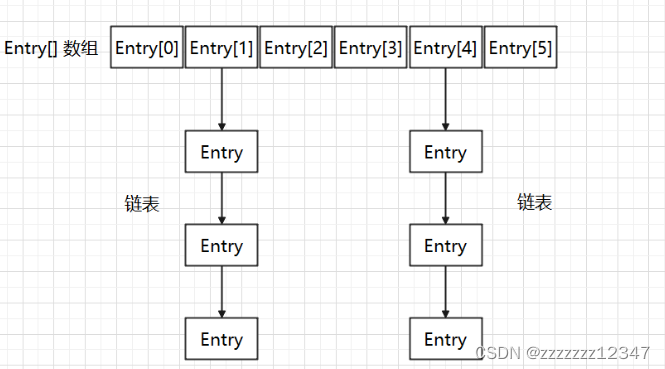
在 jdk1.8 采用数组 + 链表 + 红黑树的结构:

2、上面说到 jdk1.8 之后增加了红黑树,什么 情况下转红黑树,什么情况下又转链表的?
1、当链表的长度达到 8 ,并且数组长度是否达到 64。如果达到 64,则进行链表转红黑树的操作。否则,只是发生一次 resize,散列表扩容,还有种情况,当数组很小,但是链表过长,首先扩容数组,而不是转换树。
2、当树中的元素经过删除或者其他原因调整了大小,当小于等于 6 后,将会导致树退化成链表,中间有个过渡值 7,可以防止频繁的树化与退化。
3、为什么最开始时不直接用红黑树呢
最开始使用链表的时候,空间占用是比较少的,而且由于链表短,所以查询时间也没有太大的问题。可是当链表越来越长,需要用红黑树的形式来保证查询的效率。对于何时应该从链表转化为红黑树,需要确定一个阈值,这个阈值默认为 8,并且在源码中也对选择 8 这个数字做了说明,官方的解释如下:
In usages with well-distributed user hashCodes, tree bins
are rarely used. Ideally, under random hashCodes, the
frequency of nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because
of resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten million
![]()
这段话的意思是:如果 hashCode 分布良好,也就是 hash 计算的结果离散好的话,那么红黑树这种形式是很少会被用到的,因为各个值都均匀分布,很少出现链表很长的情况。在理想情况下,链表长度符合泊松分布,各个长度的命中概率依次递减,当长度为 8 的时候,概率仅为 0.00000006。这是一个小于千万分之一的概率,通常我们的 Map 里面是不会存储这么多的数据的,所以通常情况下,并不会发生从链表向红黑树的转换。
事实上,链表长度超过 8 就转为红黑树的设计,更多的是为了防止用户自己实现了不好的哈希算法时导致链表过长,从而导致查询效率低, 而此时转为红黑树更多的是一种保底策略,用来保证极端情况下查询的效率。
4、你知道一个值插入链表的时候,是怎么插入的?
jdk 1.8 之前是头插法,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,这是因为作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是在 jdk1.8 之后,使用了尾插法实现。
5、为什么之前使用头插法,jdk1.8 之后使用尾插法呢?
这里我们举个例子:我们定义一个容量为 2 并且 put 添加两个值,负载因子 0.75 ,在我们 put 第二个值的时候就要 resize(扩容)。
2 * 0.75 = 1,所以插入第二个就扩容。
现在我们使用不同的线程插入 a、b、c,假如我们在扩容之前打个短点,那意味着数据都插入了但是还没扩容,那扩容前可能是这样的:
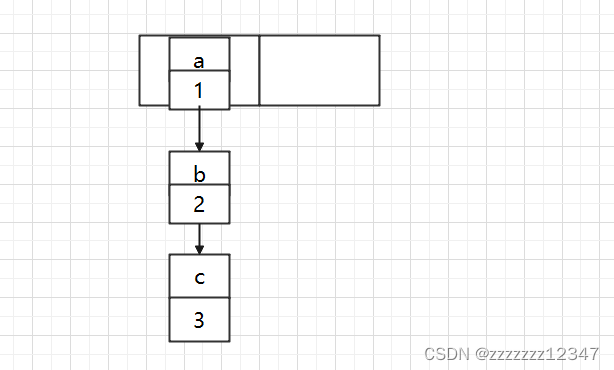
因为扩容的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条 Entry 链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
有可能会出现以下的情况:
B 的下一个指针指向了 A
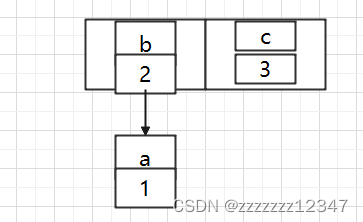
如果几个线程都调整完成,就可能出现环形链表。
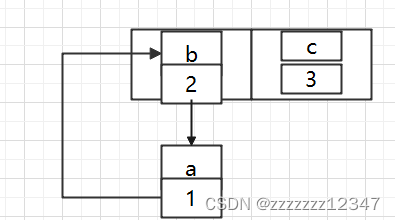
而使用头插法会改变链表的上的顺序,如果使用尾插法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了,也就是说原本是a - > b,在扩容后那个链表还是 a - > b。
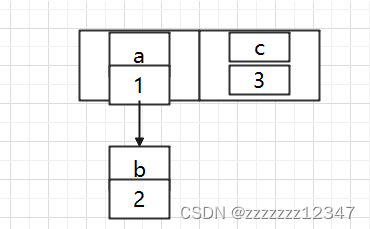
所以。在 jdk1.8 之前多线程环境下操作 HashMap 时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。在 jdk1.8之后并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
6、那是不是意味着 HashMap 在 jdk1.8之后很安全?
也不是,虽然不会出现死循环,但是在多线程的情况下,无法保证前一秒 put 的值,后一秒 get 的时候还是原来的值,我们通过源码可以看出,put 或者 get都没有加同步锁,所以线程安全问题还是无法得到保证。
7、刚才你说到了扩容,在什么条件下会进行扩容?
当 HashMap 中的元素个数超过 数组大小 * loadFactor 时),就会进行数组扩容,loadFactor(负载因子) 的默认值为 0.75,也就是说,默认情况下,数组大小为 16,那么当 HashMap 中元素个数超过 16 * 0.75=12 的时候,就把数组的大小扩展为 2 * 16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知 HashMap 中元素的个数,那么预设元素的个数能够有效的提高 HashMap 的性能。
8、说说 HashMap 的扩容机制
jdk1.7 中,扩容后,需要重新计算所有元素的 hash 值,当然也有可能不计算。因为链表元素在迁移过程中,采用头插法,因此迁移完成后,新旧链表会出现倒置现象。
jdk1.8 中,扩容后,不需要重新计算 hash 值,得益于 hash 寻址算法的优化。迁移过程中,采用尾插法,新旧链表不会倒置。
举个例子:首先 jdk1.8 中的寻址算法为:

其中 hash 是 key.hashCode() 高 16 位与低 16 位异或的结果,n 为数组长度,即使用 (n-1) 与 hash 进行按位与得到元素的位置。
扩容前:n=16

则key1与key2由于hash冲突,会形成一个链表。
扩容后:n=32

数组长度变为原来的2倍,在计算上的表现,就是多出来一个高位参与按位与。
key1 位置不变,而 key2 的 hash 值倒数第五位是 1,因此按位与计算下来得到 10101 ,而 10101 = 10000 + 0101 = 原数组长度 + 原位置。
因此,我们在扩容 HashMap 的时候,不需要像 jdk1.7 的实现那样重新计算 hash ,只需要看看原来的 hash 值新增的那个 bit 是 1 还是 0 就好了,是 0 的话索引没变,是 1 的话,新索引=原数组长度+旧索引。
9、HashMap 加载因子为什么是 0.75?
- 如果加载因子比较大,扩容发生的频率比较低,浪费的空间比较小,发生 hash 冲突的几率比较大。比如,加载因子是 1 的时候,HashMap 长度为 128,实际存储元素的数量在 64 至 128 之间时间段比较多,这个时间段发生 hash 冲突比较多,造成数组中其中一条链表比较长,会影响性能。
- 如果加载因子比较小,扩容发生的频率比较高,浪费的空间比较多,发生 hash 冲突的几率比较小。比如,加载因子是 0.5 的时候,HashMap 长度为 128,当数量达到 6 5的时候会触发扩容,扩容后为原理的 256,256 里面只存储了 65 个浪费了。
综合了一下,取了一个平均数 0.75 作为加载因子。当负载因子为 0.75 时代入到泊松分布公式,计算出来长度为 8 时,概率 = 0.00000006,概率很小了,链表长度为 8 时转红黑树。
10、HashMap 初始化大小为什么是16?
如果两个元素不相同,但是 hash 函数的值相同,这两个元素就是一个碰撞。
因为把任意长度的字符串变成固定长度的字符串,所以存在一个 hash 对应多个字符串的情况,所以碰撞必然存在。
为了减少 hash 值的碰撞,需要实现一个尽量均匀分布的 hash 函数,在 HashMap 中通过利用 ke y的 HashCode 值,来进行位运算。
公式:index = HashCode(Key) & (Length - 1)
下面举个例子,以值为 “book” 的 Key 来演示整个过程:
1、计算 book 的 HashCode :
十进制 : 3029737
二进制 : 101110001110101110 1001
2、HashMap 长度是默认的 16,length - 1 的结果:
十进制 : 15
二进制 : 1111
3、把以上两个结果做与运算:
101110001110101110 1001 & 1111 = 1001
1001的十进制 : 9,所以 index=9
可以说,Hash 算法最终得到的 index 结果,完全取决于 Key 的 HashCode 值的最后几位。
这里为了推断 HashMap 的默认长度为什么是16,我们假设 HashMap 的长度是10,重复刚才的运算步骤:
HashCode : 101110001110101110 1001
length - 1 : 1001
index : 1001
再换一个 HashCode 101110001110101110 1111:
HashCode : 101110001110101110 1111
length - 1 : 1001
index : 1001
从结果可以看出,虽然 HashCode 变化了,但是运算的结果都是 1001,也就是说当 HashMap 长度为 10 的时候,有些 index 结果的出现几率会更大,而有些 index 结果永远不会出现(比如0111),这样就不符合 hash 均匀分布的原则。
反观长度 16 或者其他 2 的幂,Length-1 的值是所有二进制位全为 1,这种情况下,index 的结果等同于 HashCode 后几位的值。只要输入的 HashCode 本身分布均匀,hash 算法的结果就是均匀的。
所以 HashMap 的默认长度为 16,是为了降低 hash 碰撞的几率。
11、最后一个问题,为什么我们重写 equals 方法的时候需要重写 HashCode 方法呢?
我们知道在 java 中所有的对象都是继承于 Object 类,而 Ojbec t类中有两个方法 equals、HashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写 equals 方法时我们是继承了 Object 类的 equals 方法,那里的 equals 是比较两个对象的内存地址。
看过源码或者了解过的小伙伴都知道,HashMap 是通过 key 的 HashCode 去寻找 index 的,如果 index 的值一样就会形成链表,比如:”张三“ 和 ”李四“ 的 index 有可能都是 1,并且在一个链表上面。
这时如果我们去查询,根据 key 去 hash 最后计算出 index 为 1,那么我们怎么找到是张三还是李四呢?
重写 equals ,我们对 equals 方法进行重写,一定要对 HashCode 方法重写,这样可以保证相同的对象返回相同的 hash 值,不同的对象返回不同的 hash 值。















 7168
7168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









