










HBase 架构101 –预写日志系统 (WAL)
原文:http://www.larsgeorge.com/2010/01/hbase-architecture-101-write-ahead-log.html
什么是预写日志WAL? 之前的文章我们简单介绍了HBase的存储结构。其中提到了预写日志。这里,我们要介绍它的实现细节,所有的描述都基于HBase 0.20.3.
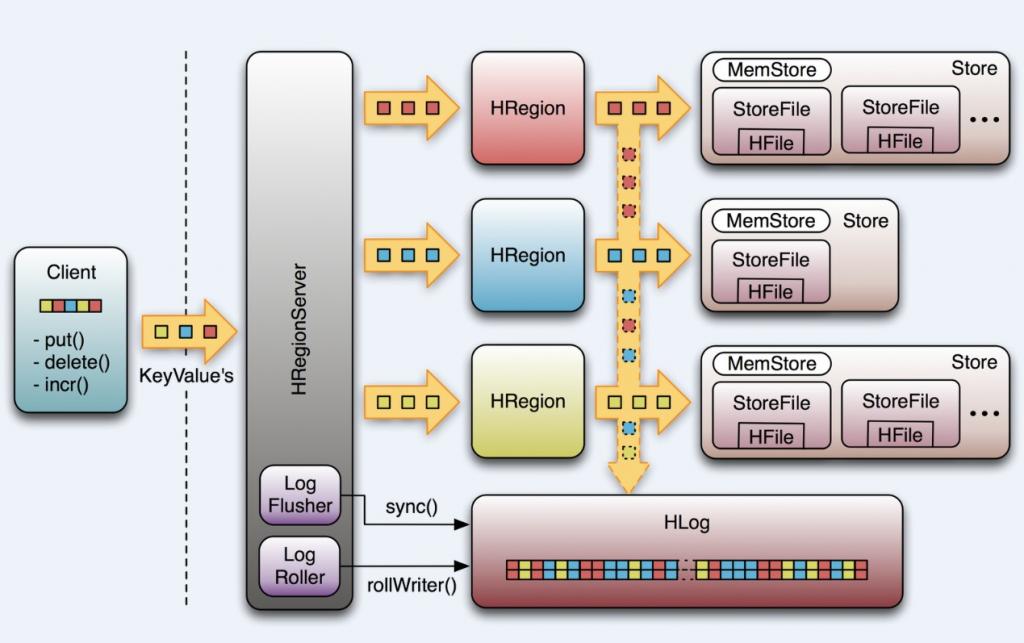
WAL最重要的作用是灾难恢复。和MySQL 的BIN log类似,它记录所有的数据改动。一旦服务器崩溃,通过重放log,我们可以恢复崩溃之前的数据。这也意味如果写入WAL失败,整个操作将认为失败。
我们先看看HBase是如何做到的。首先,客户端初始化一个可能对数据改动的操作,如put(Put),delete(Delete) 和incrementColumnValue()。这些操作都将被封装在一个KeyValue对象实例中,通过RPC 调用发送给HRegionServer(最好是批量操作)。 一旦达到一定大小,HRegionServer 将其发送给HRegion。这个过程中,数据会首先会被写入WAL,之后将被写到实际存放数据的MemStore中。
当MemStore到达一定大小,或者经过一段时间后,数据将被异步地写入文件系统中。然而,在两次写入文件系统之间的数据,是保留在内存中的。如果这个时候系统崩溃,那数据···,别急,我们有WAL!
我们先来看看WAL几个重要的类。
HLog
HLog是实现WAL的类。一个HRegionServer对应一个HLog实例。当HRegion初始化时,HLog将作为一个参数传给HRegion的构造函数。
HLog最核心的是调用doWrite的append() 方法,前面提到的可能对数据改动的操作都就将首先调用这个方法。出于性能的考虑,put(), delete() 和incrementColumnValue()有一个开关函数setWriteToWAL(boolean) , 设为false将禁用WAL。这是为什么上图中向下的箭头是虚线的原因。默认时候当然需要WAL,但是假如你运行一个数据导入的MapReduce Job,你可以通过关闭WAL获得性能上的提升。
另一个重要的特性是HLog将通过“sequence number”追踪数据改变。它内部使用AtomicLong保证线程安全。sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。Region打开存储文件,读取每个HFile中的最大的sequence number,如果该值大于HLog 的sequence number, 就将它作为HLog 的sequence number的值。最后,HLog将得到上次存入文件和继续记log的点。过会,我们将看到它的应用。
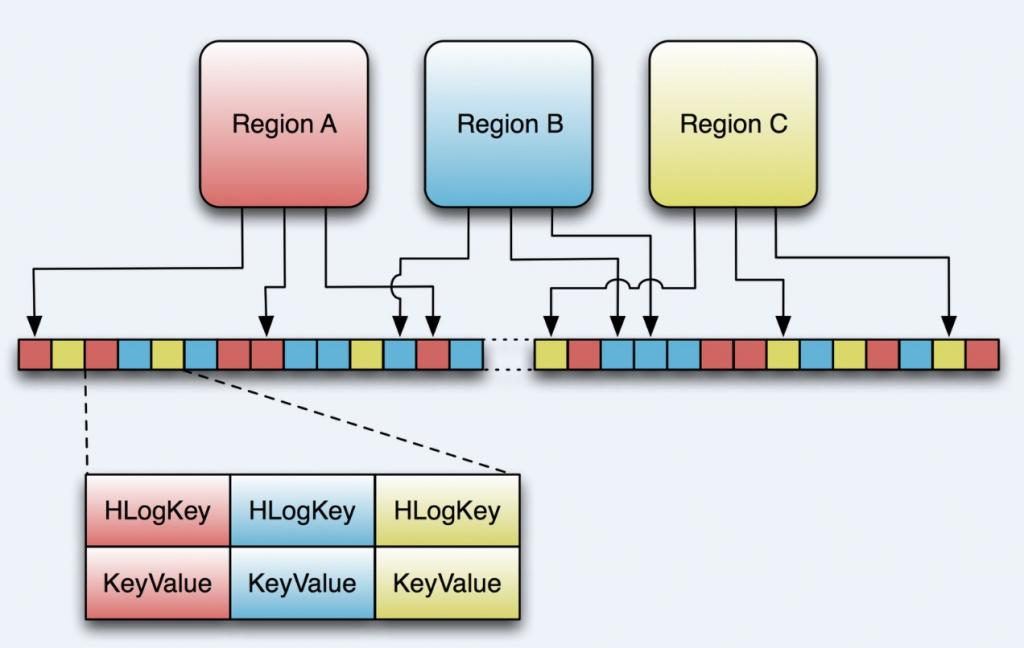
上图表示了3个不同的region,每一个负责一段rowkey的范围。这些region将共享同一个HLog实例,我们可以看出,从不同region来的数据写入WAL的顺序是不确定的。在后面我们会再详细的介绍。
最后,Hlog利用HMaster恢复和切分一个由一个崩溃的HRegionServery遗留下来的Log。之后,重新部署regions。
HLogKey
WAL使用Hadoop的SequenceFile,它将记录存储为key/values 的数据集。对于WAL,key是一个HLogKey的实例。如前一篇文章中提到的, KeyValue不仅包括row,column family, qualifier, timestamp, value, 还包括“Key Type”—派上用场啦, 这里,可以用Key Type代表一个“put”或“delete”操作。
但是,哪里去存放KeyValue的归属信息,比如region或者表名呢?这些存放在HLogKey中。同时还包括 sequence number,和“写入时间”, 是一个记录数据何时写入到log的时间戳。
LogFlusher
前面提到,数据以KeyValue形式到达HRegionServer,将写入WAL,之后,写入一个SequenceFile。看过去没问题,但是因为数据流在写入文件系统时,经常会缓存以提高性能。这样,有些本以为在日志文件中的数据实际在内存中。这里,我们提供了一个LogFlusher的类。它调用HLog.optionalSync(),后者根据“hbase.regionserver.optionallogflushinterval”(默认是10秒),定期调用Hlog.sync()。另外,HLog.doWrite()也会根据“hbase.regionserver.flushlogentries”(默认100秒)定期调用Hlog.sync()。Sync() 本身调用HLog.Writer.sync(),它由SequenceFileLogWriter实现。
LogRoller
Log的大小通过$HBASE_HOME/conf/hbase-site.xml 的“hbase.regionserver.logroll.period”限制,默认是一个小时。所以每60分钟,会打开一个新的log文件。久而久之,会有一大堆的文件需要维护。首先,LogRoller调用HLog.rollWriter(),定时滚动日志,之后,利用HLog.cleanOldLogs()可以清除旧的日志。它首先取得存储文件中的最大的sequence number,之后检查是否存在一个log所有的条目的“sequence number”均低于这个值,如果存在,将删除这个log。
这里解释下你可能在log中看到的令人费解的内容:
2009-12-15 01:45:48,427 INFO org.apache.hadoop.hbase.regionserver.HLog: Too
many hlogs: logs=130, maxlogs=96; forcing flush of region with oldest edits:
foobar,1b2dc5f3b5d4,1260083783909
这里,我们看到,log file的数目超过了log files的最大值。这时,会强制调用flush out 以减少log的数目。
“hbase.regionserver.hlog.blocksize”和“hbase.regionserver.logroll.multiplier”两个参数默认将在log大小为SequenceFile(默认为64MB)的95%时回滚。所以,log的大小和log使用的时间都会导致回滚,以先到达哪个限定为准。
Replay
当HRegionServer启动,打开所管辖的region,它将检查是否存在剩余的log文件,如果存在,将调用Store.doReconstructionLog()。重放一个日志只是简单地读入一个日志,将日志中的条目加入到Memstore中。最后,flush操作将Memstore中数据flush到硬盘中。
旧日志往往由region server 崩溃所产生。当HMaster启动或者检测到region server 崩溃,它将日志文件拆分为多份文件,将其存储在region所属的文件夹。之后,根据上面提到的方法,将日志重放。需要指出的是,崩溃的服务器中的region只有在日志被拆分和拷贝之后才能被重新分配。拆分日志利用HLog.splitLog()。旧日志被读入主线程内存中,之后,利用线程池将其写入所有的region文件夹中,一个线程对应于一个region。
问题
1. 为什么要一个RegionServer 对应于一个HLog。为什么不是一个region对应于一个log file?
引用BigTable中的一段话,
如果我们每一个“tablet”(对应于HBase的region)都提交一个日志文件,会需要并发写入大量的文件到GFS,这样,根据每个GFS server所依赖的文件系统,写入不同的日志文件会造成大量的磁盘操作。
HBase依照这样的原则。在日志被回滚和安全删除之前,将会有大量的文件。如果改成一个region对应于一个文件,将会不好扩展,迟早会引发问题。
2. 潜在问题
1) 当server崩溃,HBase需要将其log切分成合适的片。然而,由于所有的条目混杂在日志中,HMaster只有在将log完全分配到每一个server后,才能将崩溃server中的region重新分配。这个时间可能很长。
2) 数据安全。你希望能保存你所有的数据,虽然你能将flush的时间调到尽可能的低,你依然依赖于上面提到的文件系统。那些用于存储数据依旧有可能没写到磁盘而发生数据丢失。
很明显,需要log来保证数据安全。最好是能让一个日志保持1个小时(或长)的打开状态。当数据来时,将新的key/value对写入SequenceFile中,并定期flush数据到磁盘中。但是Hadoop不是这样工作的。他提供了一个API,允许打开一个文件,写入大量的数据,然后马上关闭文件,成为一个对其他人只读的文件。只有当文件关闭时才是对其他人可读的。那么,如果一个进程在写入文件时僵死,那么,数据很可能会丢失。因此,我们需要一个功能,能取到一个离崩溃服务器写入数据尽可能近的点。
插曲: HDFS append,hflush,hsync,sync···
这些都起源于HADOOP-1700。Hadoop 0.19没有能解决这个问题。这个问题后来又成为HADOOP-4379或HDFS-200,并实现了syncFS(),后者可以同步文件的改变。同时,HBase-1470中,将这个API开放,但是依然没有解决这个问题。
之后是HDFS-265,重新提出append的方案,并引入Syncable的接口,开放hsync()和hflush()。
SequenceFile.Writer.sync()和上面的并不相同。 它只是将一个同步标记写入文件,以方便数据恢复。
虽然append对于HDFS很有用,但并没有用在HBase中。HBase用了hflush,它可以在log写完成后将所有数据写入磁盘。当服务器崩溃,我们可以安全地将“脏”文件读到最后一次改动。Hadoop 0.19.0中,利用Hadoop fsck /可以根据HBase打开的日志文件数目报告DFS的破损程度。
结论是,在Hadoop 0.21.0之前,你非常容易遇到数据丢失。在Hadoop 0.21.0之后,你将得到顶尖的系统(有点吹牛啦,译者注)。
改善计划
在HBase0.21.0中,WAL构架会有相当大的改进,这里强调几点
1. 替换SequenceFile
WAL的核心之一就是存储格式。SequenceFile有不少问题,最大的性能问题就是所有的写入都是同步的(HBase-2105)。
在HBase 0.20.0中,HFile替换了MapFile,所以,可以考虑一个完全的替换。首先要做的是HBase独立于底层的文件系统。HBase-2059使log的实现方式可配。
另一个想法是完全换一种序列化方式。HBase-2055提出利用Hadoop的Avro作为底层系统。Avro也可能成为Hadoop新的RPC格式,希望有越来越多的人熟悉它。
2. Append/Sync
频繁的调用hflush()会导致系统变慢。之前的测试发现,如果每一个记录都调用旧的syncFs(),将大大降低系统的性能。HBase-1939提出一种“组提交”的方法,可以批量flush数据。另外,HBase-1944中提出将“延时flush log”最为一个Column Family 的参数。设为“true”,将同步改动到log的工作交给新的LogSyncer类和线程。最后,在HBASE-2041中,将flushlogentries 设置为1, optinallogflushinterval 设为1000毫秒。.META.每次改变都会被同步,用户表可以根据需要类配置。
3.分布式日志切分
之前谈过,当region需要被重新分配时,切分日志将成为一个问题。一个方法就是在zookeeper中维护一个regions的列表。这个方法至少能保证所有“干净”的region能被快速地分配。剩下那些需要等待日志被切分的条目。
剩下的问题就是如何更快地切分日志。这里,BigTable有如下的描述:
一种方案是对于每一个新的tablet server(类似regionserver),需要读取整个日志文件,然后,分配那些需要被修复的条目。然而,在这种情况下,如果将一个失败的tablet server重新分配到100台机器,那么每个日志文件需要读100次。
改进方案
我们根据key对log条目进行排序。之后,所有对一个特定tablet的改动都将是连续的,顺序读可以有效地提高磁盘检索的效率。为了并行地排序,我们将日志切分为64MB的分片。每个排序进程都将有Master协调管理,并在tablet server给出它将从那些日志文件中恢复时初始化。
这就是他的原理。在HMaster rewrite (HBASE-1816)中,也提到了日志拆分。HBASE-1364中,将日志拆分打包成一个问题。但我觉得会引入更多的需要讨论的细节。















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









