



 本文对比了Kotlin中的Flow和Sequence,指出Flow在非阻塞、可取消、自我扩展、多线程启动、异步组合、展平等方面优于Sequence。然而,Sequence在某些场景下仍具优势,如轻量级、可直接遍历和更多集合运算符。Flow适合需要异步和并发处理的场合,而Sequence在简单处理和低开销时更合适。
本文对比了Kotlin中的Flow和Sequence,指出Flow在非阻塞、可取消、自我扩展、多线程启动、异步组合、展平等方面优于Sequence。然而,Sequence在某些场景下仍具优势,如轻量级、可直接遍历和更多集合运算符。Flow适合需要异步和并发处理的场合,而Sequence在简单处理和低开销时更合适。
前言
这段时间,笔者在日常开发中总会对一些数据量比较大的列表进行一些操作处理,最终需要拿到一个处理后的结果,但这时候如果创建中间集合会变得非常昂贵,使用普通集合性能又不是太好,怎么办呢?作为一名_Kotlin_开发者,_Kotlin_已经给出了具体的方案,那就是使用_Sequences_惰性序列,不用处理所有数据,从而大大节省了运行时间;
就目前来说,由于_Kotlin Flow_流出现了,它的行为就像一个序列,_Sequences_能做的事情,它也能做,甚至还能做的更多,这时候有人就说了,那_Flow_岂不是_Sequence_更好的替代品了?_Sequence_要退出历史的舞台了?凡拥有相似功能的事物存在,必有这个问题,这里先不做定论,下面笔者和小伙伴们一起探讨下吧
Kotlin Flow 与 Sequence 对比
首先,在开始探究它们之间的区别前,我们来看看_Flow_和_Sequence_都是怎样处理数据的,直接上代码
(1..3).asSequence()
.map {
println("sequence map $it")
it * 2
}
.first {
it > 2
}.let {
println("sequence $it")
}
runBlocking {
(1..3).asFlow()
.map {
println("flow map $it")
it * 2
}
.first {
it > 2
}.let {
println("flow $it")
}
}
以上它们的行为都是相似的,如下图所示
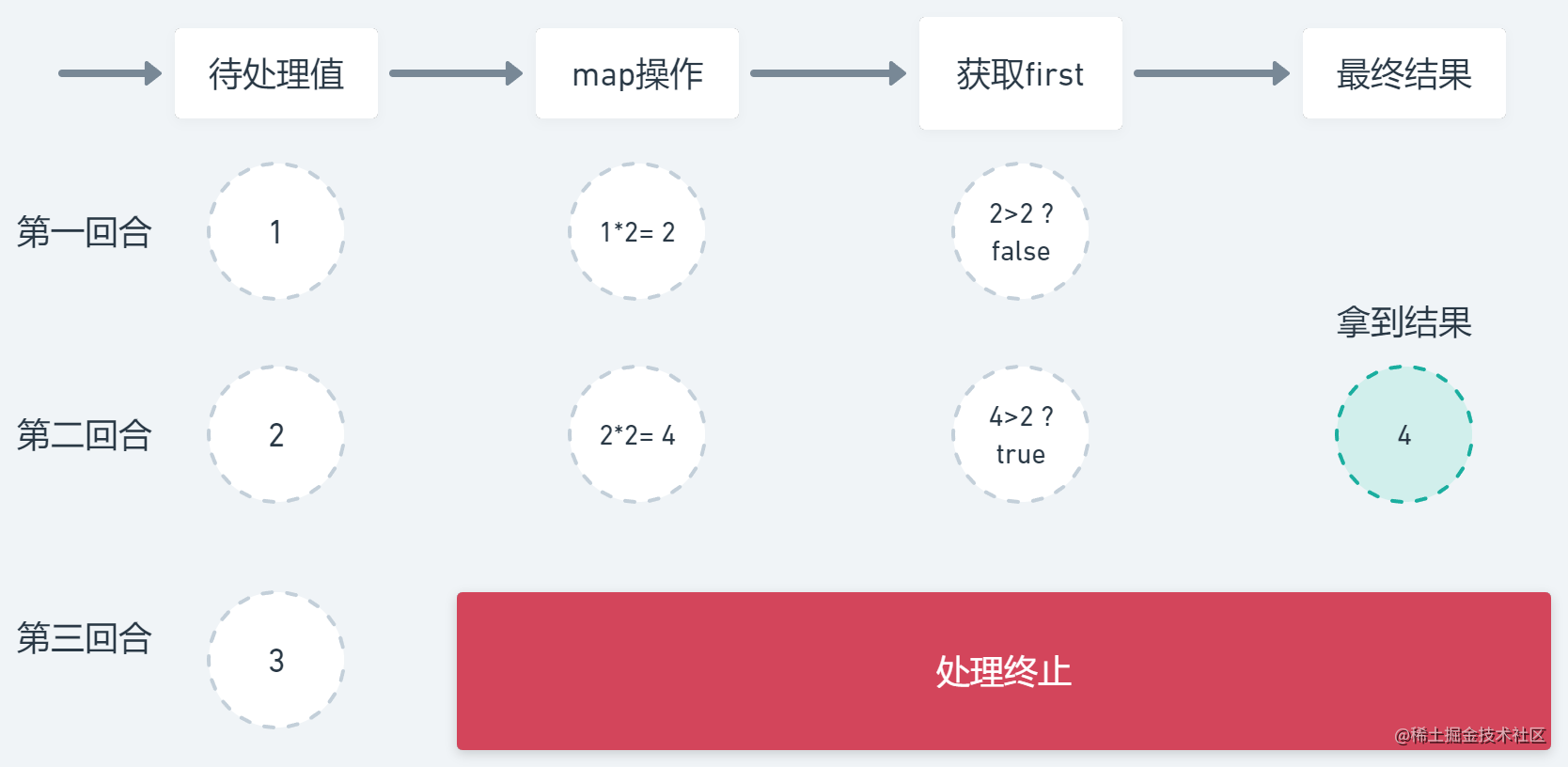
结果显而易见,两种方式的结果都是一致的,在获取结果之后立刻终止了该过程

和传统_List_相比,它们确实节省了不少时间,可以不用处理所有的值,在这种处理事情的行为上面,_Flow_和_Sequence_都是相同的。就好像,现在_Flow_和_Sequence_是两名演员,都是唱歌的,但这个时候有趣的事情发生了,_Flow_说我不当当会演戏,我还会唱歌,跳舞,Rap,篮球等等
总而言之,_Flow_能做的事情比_Sequence_多得多,接下来我们来看看_Flow_和_Sequence_相比有哪些好处
1. Sequence是阻塞的,Flow是非阻塞的
为什么这么说呢,这里的阻塞是阻塞主线程,请允许我娓娓道来,我们还是分开来说吧,这样方便理解
-
关于_Sequence_
先来生成一个序列,这里我们想要模拟一个慢延迟的效果,但是在序列当中是不允许有_suspend_函数的,所以笔者使用_Thread.sleep_来代替,看下代码
fun simple() = sequence { (1..3).forEach { Thread.sleep(100); yield(it) } } fun main() = runBlocking<Unit> { launch { for (k in 1..3) { println("From main $k") delay(100) } } simple().forEach { value -> println("From sequence $value") } }此时结果展示如下

可以看到我们是先从sequence取出结果后,再去执行主线程的内容
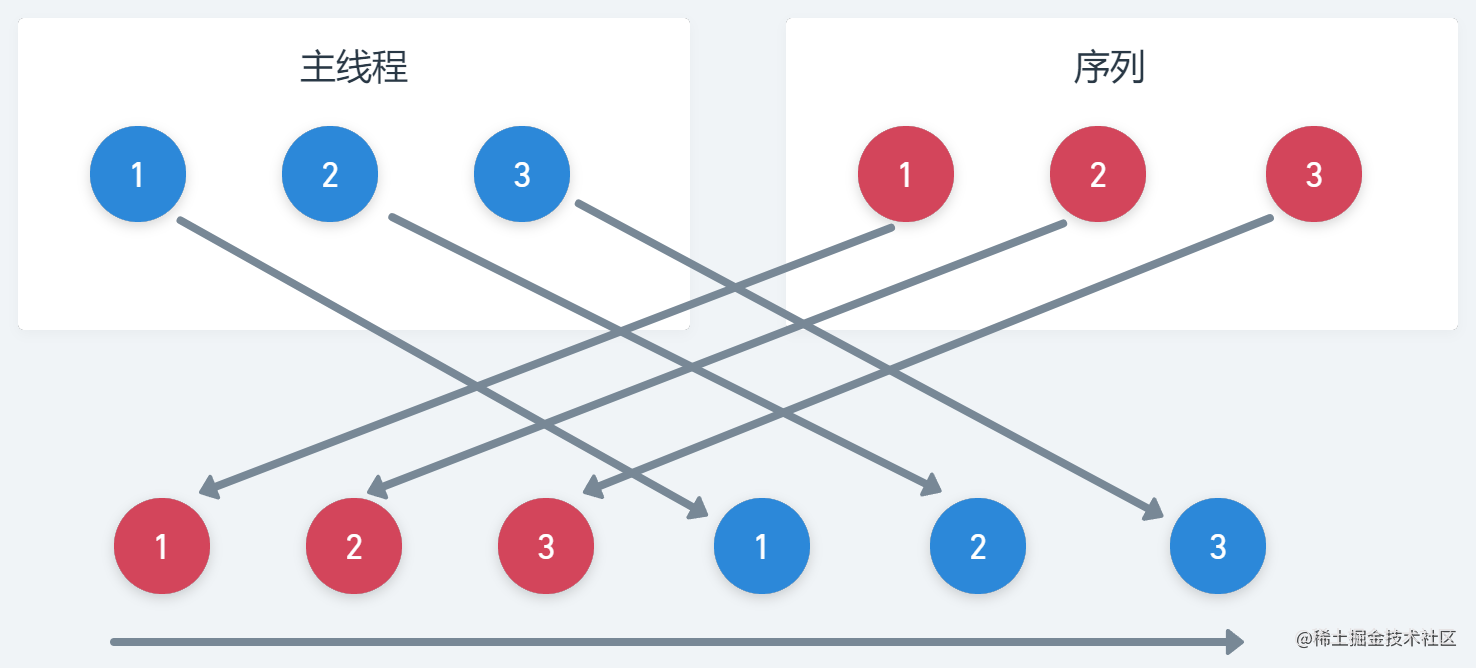
-
关于_Flow_
同样我们使用_Flow_来实现上面列表,模拟一个慢延迟的效果,在Flow中可以使用_delay_挂起函数来进行操作,如下代码所示
fun simple() = flow { (1..3).forEach { delay(100) emit(it) } } fun main() = runBlocking { launch { for (k in 1..3) { println("From main $k") delay(100) } } simple().collect { value -> println("From flow $value") } }此时结果展示如下图所示:

可以看到_Flow_流并不影响主线程的内容执行
2. Sequence不能轻易取消,Flow可以随时取消
在序列当中,即使运行过程很慢,也不能被中途取消
fun simple() = sequence {
(1..3).forEach {
Thread.sleep(100)
yield(it)
}
}
fun main() = runBlocking {
//250ms后超时
withTimeoutOrNull(250) {
simple().forEach { value -> println(value) }
}
println("Done")
}
运行结果如我们所料,一旦序列开始执行后,就算我们设置了超时时长,但也什么都没有改变,什么都改变不了…

而如果使用_Flow_的话,我们中途可以进行暂停
fun simple() = flow {
(1..3).forEach {
delay(100)
emit(it)
}
}
fun main() = runBlocking {
//250ms后超时
withTimeoutOrNull(250) {
simple().collect { value -> println(value) }
}
println("Done")
}
这样流程在250毫秒后会被取消,结果如下

3. Sequence本身不能轻易扩展,Flow 可以很容易地自我扩展
想象一下,此时有一个列表2,4,6 ,我们想要将它扩展成1,2,3,4,5,6,这时候呢可以使用_transform_运算符实现这个操作,来瞥一眼代码
fun main() = runBlocking {
(2..6 step 2).asFlow().transform {
emit(it - 1)
emit(it)
}.collect { println(it) }
}
输出结果显而易见,将从原来的2, 4, 6转到1, 2, 3, 4, 5, 6

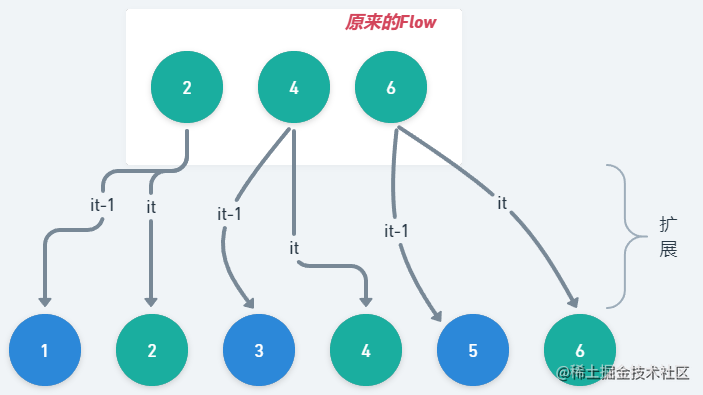
思考一下,如果是序列呢,它能这样扩展么?答案相信大家已经清楚了
4. Sequence不能单独在另一个线程中启动,Flow 可以在另一个线程中启动自己
怎么说呢?在序列当中,如果我们实在想要在另一个线程中使用序列的话,必须要依赖单独的工具(例如协程),否则单靠自己本身是无法实现的。
fun main() {
run()
//确保其他线程完成
Thread.sleep(100)
}
fun run() {
CoroutineScope(Dispatchers.IO).launch {
(1..3).asSequence()
.forEach {
println("$it ${Thread.currentThread()}")
}
}
}
这样的话,我们就在子线程中启动了我们的序列
反观_Flow_,它本身就是基于协程来执行的,所以我们可以使用_launchIn_轻松让它在另一个线程中启动,并为其提供相应的作用域_CoroutineScope_
fun main() {
run()
// 确保其他线程完成
Thread.sleep(100)
}
fun run() {
(1..3).asFlow()
.onEach {
println("$it ${Thread.currentThread()}")
}.launchIn(CoroutineScope(Dispatchers.IO))
}
就是这么简单,简洁而甜美,直接在它本身上进行操作就完成了
5. Sequence不能在两个线程中发送接收操作,Flow则可以在另一个线程中运行
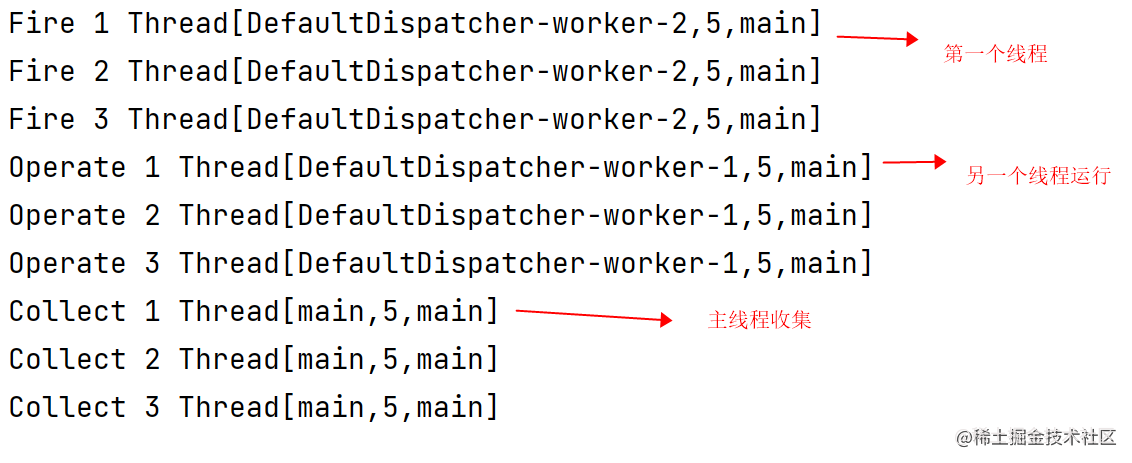
什么意思呢?假设我们想在一个线程中触发程序并在另一个线程中运行,最后在另一个线程中收集数据,这样的话,序列_Sequence_并不能满足,我们需要使用_Flow_进行完成,_Kotlin_有提供_flowOn_函数
fun main() = runBlocking {
flow {
(1..3).forEach {
println("Fire $it ${Thread.currentThread()}")
emit(it)
}
}
.flowOn(Dispatchers.IO)
.transform {
println("Operate $it ${Thread.currentThread()}")
emit(it)
}
.flowOn(Dispatchers.Default)
.collect {
println("Collect $it ${Thread.currentThread()}")
}
}
结果如下图所示

6. Sequence不可以并行处理,Flow可以并行处理
在序列中,执行元素是按照列表顺序执行的,只有上一个元素执行完毕后才会执行下一个元素,它无法进行并行处理的;还是用一个例子来说明吧,如果每个元素的生成需要 100ms,每个元素的处理过程又需要 300ms,下面每一轮大约需要400ms,来撇一下代码
fun simple() = sequence {
(1..3).forEach {
Thread.sleep(100)
yield(it)
}
}
fun main() = runBlocking {
val time = measureTimeMillis {
simple().forEach {
delay(300)
}
}
println("Collected in $time ms")
}
显而易见,因为具有3个元素,这段程序耗时大约需要 3 x 400ms = 1200ms,而实际结果也确实如我们所料,实际耗时在1257ms,差不多
而在_Flow_中,我们可以使用_buffer_要求发射器继续其工作而无需等待处理完成,也就是说_Flow_可以进行数据的并行处理,还是按照上述要求写一段代码
fun simple(): Flow<Int> = flow {
for (i in 1..3) {
delay(100)
emit(i)
}
}
fun main() = runBlocking {
val time = measureTimeMillis {
simple().buffer().collect {
delay(300)
}
}
println("Collected in $time ms")
}
这段程序的处理耗时是1083ms
这样的话也就是说,只有第一个元素将花费大约 100ms + 300 ms,列表元素收集只需要 300ms,因为 100ms 的触发时间是与处理并行完成的。
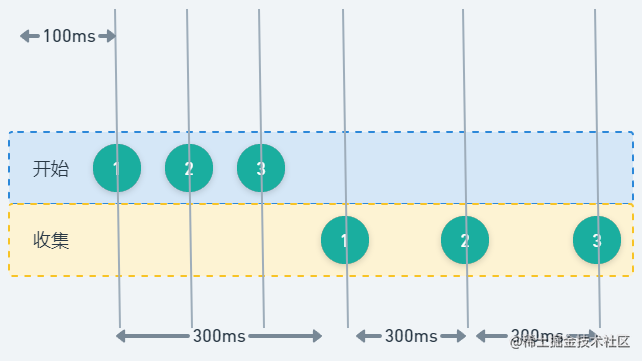
7. Sequence无法剔除快慢元素,Flow可以消除快慢元素
结合上一个观点,序列_Sequence_无法进行并行处理,无论元素处理快慢与否,都得按照先后顺序来,_Flow_可以并行处理,基于此,我们可以在收集元素之前做一些操作,可以剔除发射快的元素,也可以剔除比较慢的元素,通过这些来提高程序的运行效率。
在_Flow_中,一般我们可以通过_Conflate_函数和_CollectLatest_函数实现
-
Conflate
使用_Conflate_函数,我们可以选择通过仅收集最新元素来消除快速发出的元素,如下代码所示
fun simple(): Flow<Int> = flow { for (i in 1..3) { delay(100); emit(i) } } fun main() = runBlocking<Unit> { val time = measureTimeMillis { simple().conflate().collect { delay(300) println(it) } } println("Collected in $time ms") }元素 2 被合并,因为元素 3 在元素 1 完全处理之前就已准备就绪。结合下图会更好地理解这个流程。
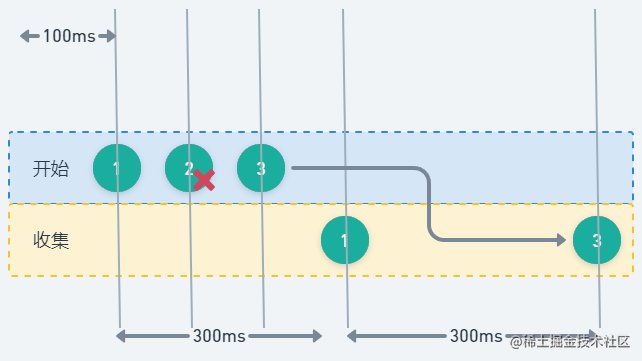
(在这种情况下,元素 2 将被合并,因为元素 3 在元素 1 完成处理之前发出)
CollectLatest
同样的,我们使用_CollectLatest_函数,如果有最新的元素发出,这时候我们就可以选择消除掉之前缓慢的元素,最后接收的元素就是最新的元素,如下代码所示
fun simple(): Flow<Int> = flow {
for (i in 1..3) { delay(100); emit(i) }
}
fun main() = runBlocking {
val time = measureTimeMillis {
simple().collectLatest {
println("get $it")
delay(300)
println("done $it")
}
}
println("Collected in $time ms")
}
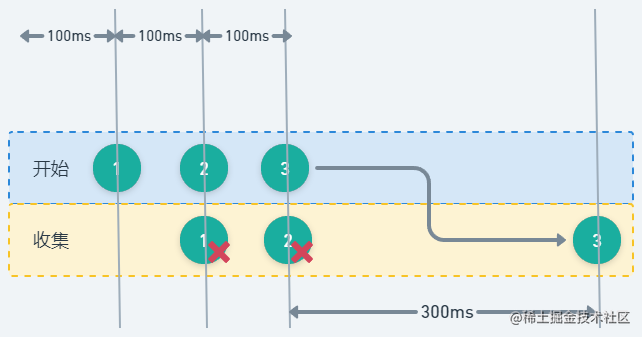
收集了所有元素 1、2 和 3。但元素 1 和 2 被消除,因为下一个元素在完全处理之前就到达了,结合下图会更好地理解这个流程。
8. Sequence只能同步组合,Flow可以异步组合
这是什么意思呢,平常开发我们都会碰到两个以上的序列或者流需要同时执行的情况,这个时候就需要用到组合运算符了,当然序列和流都有相应的组合的运算符,但它们之间亦有不同,无论是序列还是流,都有_zip_运算符来进行组合,当然流还有另外的运算符,这个之后会说,我们先来看看_zip_运算符
-
_zip_运算符(序列和流)
对于序列,即便元素是以不同的速度进行生成,但最终的结果也是同步的,即逐个按元素排序,来先上代码
fun firstSeq() = sequence { (1..3).forEach { Thread.sleep(100) yield(it) } } fun secondSeq() = sequence { (4..6).forEach { Thread.sleep(300) yield(it) } } fun main() = runBlocking { val time = measureTimeMillis { firstSeq().zip(secondSeq()).forEach { println(it) } } println("Collected in $time ms") }接着我们使用_Flow_,同样实现上面这个流程
fun firstFlow() = flow { (1..3).forEach { delay(100) emit(it) } } fun secondFlow() = flow { (4..6).forEach { delay(300) emit(it) } } fun main() = runBlocking { val time = measureTimeMillis { firstFlow().zip(secondFlow()) { first, second -> Pair(first, second) }.collect { println(it) } } println("Collected in $time ms") }代码有点多,现在我们来看下两者的结果

虽然输出结果是一样的,但很明显Flow要快上一些,原因就在于序列执行的元素是串联排列的,第一个和第二个元素被压缩在一起,所消耗的时间也是两者相加,而Flow是两者并列执行的,所消耗的时间是双方较长耗时的一方;简单来说,前者是串行的,后者是并行的,结合下图会更好的理解 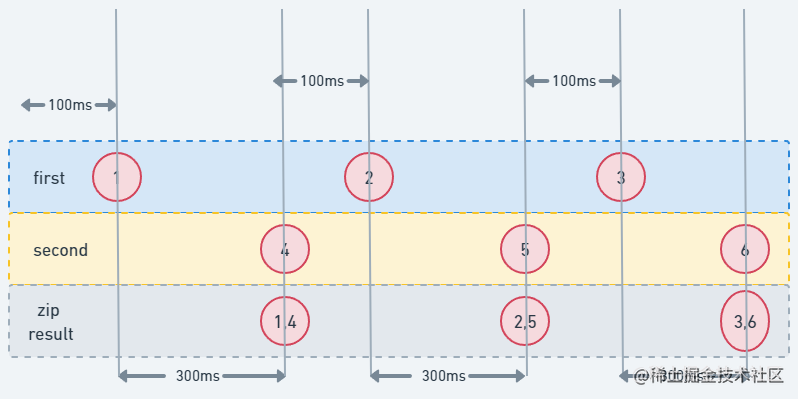
-
_combine_运算符(仅支持流)
在_Flow_中,我们还可以使用_combine_运算符来组合两个具有不同速率的流,但它仅仅只能用在_Flow_中,同样它不会阻塞其中任何一个,这就是Flow为什么可以异步组合的原因了,老规矩,先上代码
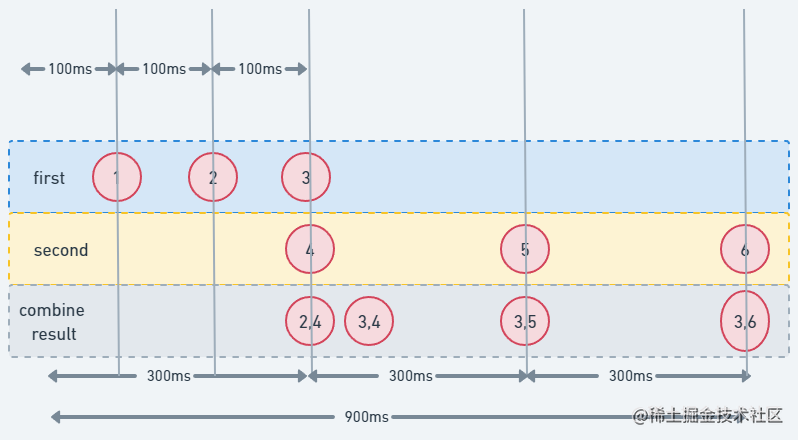
fun main() = runBlocking { val time = measureTimeMillis { firstFlow().combine(secondFlow()) { first, second -> Pair(first, second) }.collect { println(it) } } println("Collected in $time ms") }这里我们将上文的_zip_运算符换成_combine_运算符,此时结果会不会有所不同呢?一起来看下

如上图结果所示,第一个流继续发出元素,当第二个流出现时,它会采取任何可用的元素(在这种情况下
2并与4它所拥有的结合起来),这点和_zip_运算符是不同的,由于篇幅原因,就不细说它们之间的区别了,我们只要知道_zip_运算符会等待所有流返回新的元素才会进行组合,而_combine_不会等待流中是否有新的元素,它会立刻调用转换函数;简单一点,_zip_要等待新元素才进行组合,_combine_不等待,只要有元素就组合,具体想要了解的同学可以看_Kotlin_的官方文档如同上面的例子中, 在元素
2和4之间发出的3,因此它会产生(2, 4)和(3, 4)
9. Sequence只做同步展平,Flow可以进行异步展平
所谓展平呢,简单来说,就是序列/流在接收元素的时候,可能需要另一个序列/流的元素,这两者进行交互的操作。对此它们都有提供相应的运算符_FlatMap_,而Flow流展平一般有三种模式,连接模式_FlatMapConcat_,合并模式_FlatMapMerge_,最新展平模式_flatMapLatest_,我们就不作过多讨论了,这里只是简单将序列和流的展平做一个比较,想要了解流展平的同学,可以看一下这篇文章:
Flow 流展平 ( 连接模式 flatMapConcat | 合并模式 flatMapMerge | 最新展平模式 flatMapLatest )
-
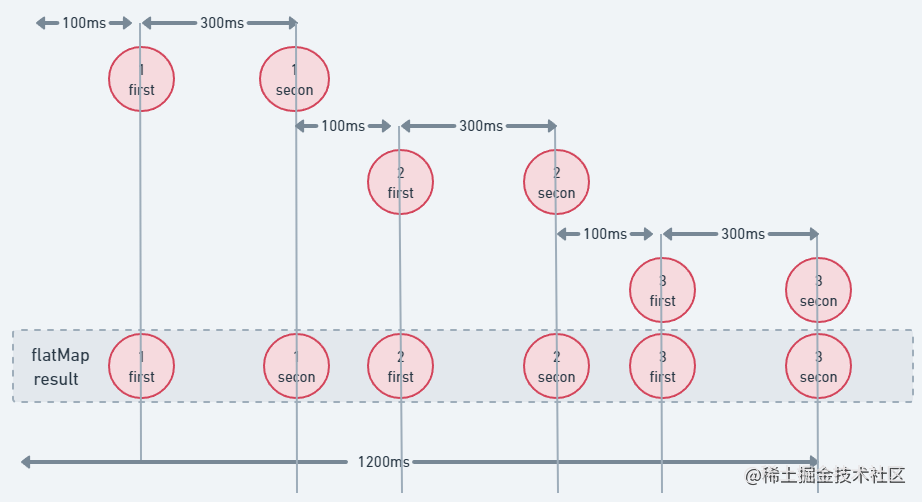
回归主题,先来看看序列的展平,使用_FlatMap_,我们来看下代码
fun requestSequence(i: Int): Sequence<String> = sequence { yield("$i: First") Thread.sleep(300) yield("$i: Second") } fun main() = runBlocking { val startTime = System.currentTimeMillis() (1..3).asSequence().onEach { Thread.sleep(100) }.flatMap { requestSequence(it) }.forEach { println("$it at ${System.currentTimeMillis() - startTime} ms from start") } }运行结果如下图所示:

在序列中,全部元素都是串行完成的,所以必须按顺序处理,很明显我们已经知道了最终的结果,但相对来说所需要的时间是最长的,因为每个_序列_都是按照提供的顺序连续处理的。结合下图会更好的理解该流程
-
接着简单看下Flow中的展平,这里就以合并模式_FlatMapMerge_,最新展平模式_flatMapLatest_为例,它们都是并行处理数据的,前者是如果任何一个元素完成处理,可以先展平为结果,无需等待,后者顾名思义,当发射了新值之后,上个 flow 就会被取消,如果只想要最新的值,并且消除前面比它慢的元素,可以使用_FlatMapLatest_
-
合并模式_FlatMapMerge_
还是老规矩,用一个例子来辅助说明
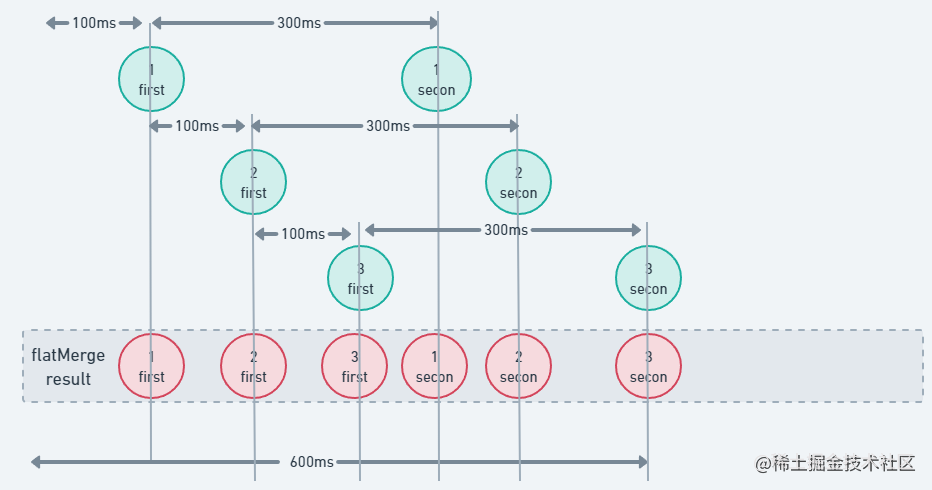
fun otherFlow(i: Int): Flow<String> = flow { emit("$i:First") delay(300) emit("$i:Second") } @OptIn(FlowPreview::class) fun main() = runBlocking { val startTime = System.currentTimeMillis() (1..3).asFlow().onEach { delay(100) } .flatMapMerge { otherFlow(it) } .collect { value -> println("$value 从开始耗时 ${System.currentTimeMillis() - startTime} ms ") } }不置可否,结果如我们预期一样,它是并行处理的,即在一个流处理完成之前,另一个流也可以开始,所以它所消耗的时间基本是由其中耗时最长的那个流决定的,这样也能更快的产生结果,提高效率
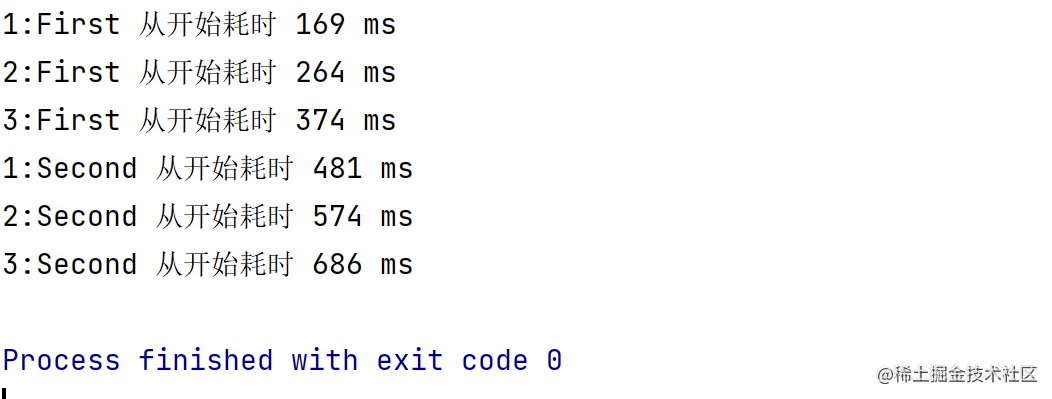
再结合下图进行理解该流程
-
最新展平模式_FlatMapLatest_
还是同样使用上面的流程,这里我们将运算符改为_FlatMapLatest_,看看结果会有什么不同,先瞄一眼代码
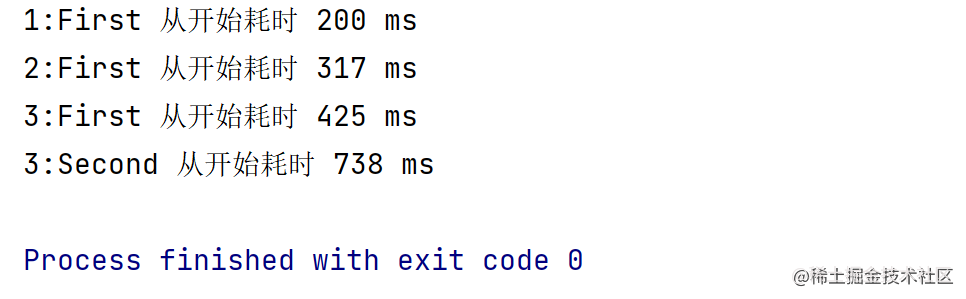
fun otherFlow(i: Int): Flow<String> = flow { emit("$i:First") delay(300) emit("$i:Second") } @OptIn(ExperimentalCoroutinesApi::class) fun main() = runBlocking { val startTime = System.currentTimeMillis() (1..3).asFlow().onEach { delay(300) } .flatMapLatest { otherFlow(it) } .collect { value -> println("$value 从开始耗时 ${System.currentTimeMillis() - startTime} ms ") } }结果如下所示:
-
这时候相信各位小伙伴都已经发现了,第二个flow中第一个和第二个值都不见了,只展平了第三个值,这就是_FlatMapLatest_的独特所在了,它和我们这里没有提到的_FlatMapConcat_类似,都是后面发射的值会取消之前正在处理的值,这里就不展开了,可以结合下图进行尝试理解该流程
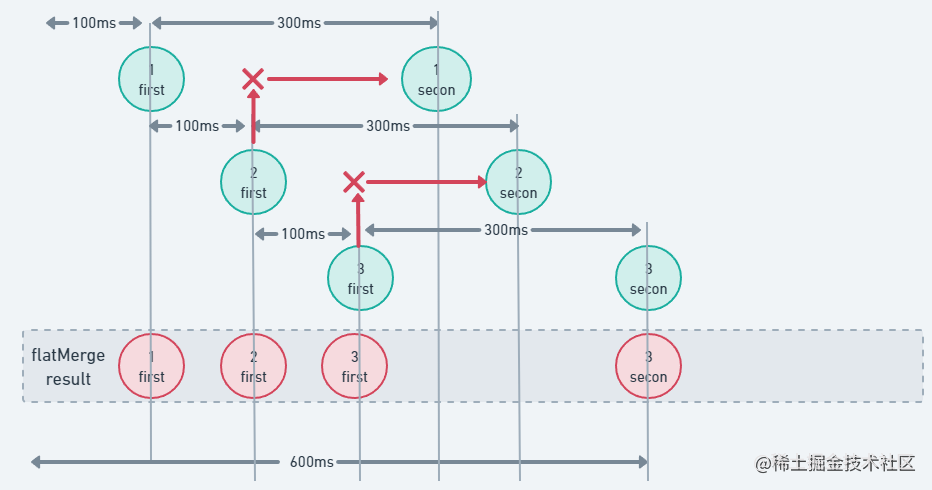
10. Sequence异常处理使用Try-Catch,Flow有封装好的异常运算符
无论是_Sequence_还是_Flow_,对于异常的处理都可以使用_try-catch_
fun simple(): Sequence<Int> = sequence {
for (i in 1..3) {
println("Generating $i")
yield(i)
}
}
fun main() = runBlocking {
try {
simple().forEach { value ->
check(value <= 1) { "Crash on $value" }
println("Got $value")
}
} catch (e: Throwable) {
println("Caught $e")
} finally {
println("Done")
}
}
以上是_Sequence_的异常处理,结果如下所示
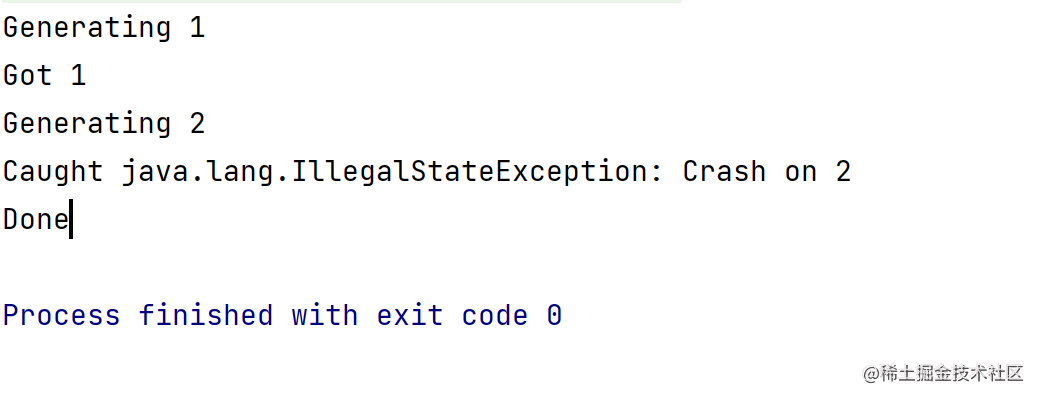
Flow_有封装好的操作符_Catch_和_OnCompletion,可以直接在链上执行,以此可以简化代码,如下代码所示
fun simple(): Flow<Int> = flow {
for (i in 1..3) { println("Generating $i"); emit(i) }
}
fun main() = runBlocking {
simple().onEach { value ->
check(value <= 1) { "Crash on $value" }
println("Got $value")
}.catch { e ->
println("Caught $e")
}.onCompletion {
println("Done")
}.collect()
}
结果和上面完全一致的,但是代码看起来简洁了些,优雅了些
小结
通过以上观点来看的话,大家是不是觉得,显然_Flow_比_Sequence_好太多了,Flow_就是像是加强版的序列_Sequence Plus,可以做更多的事情,例如线程切换、取消、异步和并行处理等等。
那么这个时候就有人会说了,那你的意思就是意味着我们只使用_Flow_就可以满足日常开发需求咯,那还要_Sequence_有什么用呢?这时候_Sequence_听到两眼一黑,说罢便准备退出表演的舞台,一边喃喃自语,算了,我不拍了,是金子总会发光的…
这时候_Kotlin_制片人老大哥大喊一声,不是这样的,我知道你很急,但你先别急,_Sequence_依旧有自己的简单性和优势,它在有些情况仍然比_Flow_好,这部电影你的角色依旧不可或缺,即便是小角色,这时候_Sequence_停下了脚步,急忙跑到_Kotlin_身边,展颜欢笑,"不如说说我都能胜任什么角色吧”
话都说到这个份上了,接下来让我们一起来看看吧
什么情况下使用_Sequence_而不是_Kotlin Flow_?
上面我们说了_Flow_很多好处,但也不是所有场景都适用于_Flow_的,有些特定的场景反而使用_Sqeuence_效果会更佳,_Sequence_此时搬过来一个小板凳做到了旁边,用力的撇撇嘴,大声说道:“虽然我只会演戏,即便只是一个小角色,但我也要做到最好”
减少开销,Sequence比Flow更轻量
如同前面所说,_Flow_承载了太多太多东西了,它围绕协程进行开发的,具有异步执行事物、线程、并行处理等的能力等等,这无疑将带来额外的开销。我们来做个对比吧,用事实来说话
-
使用序列来加载一亿个数据,我们来看看耗时
val sequence = (1..100000000).asSequence() val startTime = System.currentTimeMillis() fun main() = runBlocking { val result = sequence .map { it * 3 } .filter { it % 2 == 0 } println("Start") result.reduce { ac, it -> ac + it }.run { println(this) } println("Done in ${System.currentTimeMillis() - startTime}ms") }
结果如下,大概需要1秒左右

- 同样使用Flow,来执行相似的操作,我们再来看看耗时
val flows = (1..100000000).asFlow()
val startTime = System.currentTimeMillis()
fun main() = runBlocking {
val result = flows.map { it * 3 }
.filter { it % 2 == 0 }
println("Start")
result.reduce { ac, value ->
ac + value
}.run { println(this) }
println("Done in ${System.currentTimeMillis() - startTime}ms")
}
结果如下所示,可以看到耗时比序列慢了差不多1.5秒

换句话说,如果我们不需要Flow带来的这些功能,可以选择序列,这样也能提高程序的效率
Sequence可以遍历每个元素,Flow不能直接循环遍历
如果我们由于某种原因想控制每个元素来执行某种算法,但又不想用操作运算符,只想通过_for-loop_来实现它,那么序列是支持这种做法
for (i in (1..3).asSequence()) {
println(i)
}
但是_Flow_并不能做到这一点,它只能通过操作符_onEach_并且要_collect_收集它才能实现上面操作,不支持_for-loop_操作,如果我们想这么操作的话,那么使用序列才能实现
序列相比Flow拥有更多可用的运算符
目前来说,有大量的_Kotlin_集合运算符适用于序列,但有些可能不适用于_Flow_,比如_chunk_ ,windowed, zipWithNext,toIterator,ifEmpty_等等。如果你需要它们,容器要么是一个_list,要么是一个_sequence_,这里笔者就不详细展开了,之后会专门整理出一篇文章说明这些操作符用法和运用场景。
值得一提的是,_Flow_和_Sequence_可以轻松相互转换,真正做到你中有我,我中有你
-
从_Flow_转换到_Sequence_
sequenceOf((1..3).asFlow()) -
从_Sequence_转换到_Flow_
(1..3).asSequence().asFlow()
序列可以直接执行,Flow必须依赖协程
对于_Flow_,它是在协程的环境中运行的:
-
在协程范围内
runBlocking { (1..3).asFlow().collect() } -
在挂起函数中
suspend fun main() { (1..3).asFlow().collect() } -
使用_launchIn_设置协程范围
(1..3).asFlow().launchIn(CoroutineScope(Dispatchers.IO))而对于_Sequence_,它可以自行运行,无论你在哪里设置…
小结
听君一席话,如听一席话,_Sequence_此时握紧_Kotlin_制片人的手,还是您懂我啊,我只想做一个纯粹的演员啊…
好的,回顾一下,如果我们遇到以下情况的话,就可以使用序列_Sequence_了
-
不需要任何_Flow_流提供的强大的功能
-
需要自己手动For循环遍历元素的时候
-
需要访问更多可用的集合操作符
-
不想在协程的环境中
-
不需要去异步请求数据的时候
…
最后想说的话
综上所述,_Sequence_实际上并不是_Flow_的替代品,物尽善其美,任何事物的存在都有它的价值,文章关于它们之间的讨论就到这里吧,但是它们之间的故事仍然在继续…
转自 https://juejin.cn/post/7253673249158234169
作者:RainyJiang
最后
如果想要成为架构师或想突破20~30K薪资范畴,那就不要局限在编码,业务,要会选型、扩展,提升编程思维。此外,良好的职业规划也很重要,学习的习惯很重要,但是最重要的还是要能持之以恒,任何不能坚持落实的计划都是空谈。
如果你没有方向,这里给大家分享一套由阿里高级架构师编写的《Android八大模块进阶笔记》,帮大家将杂乱、零散、碎片化的知识进行体系化的整理,让大家系统而高效地掌握Android开发的各个知识点。

相对于我们平时看的碎片化内容,这份笔记的知识点更系统化,更容易理解和记忆,是严格按照知识体系编排的。
全套视频资料:
一、面试合集

二、源码解析合集

三、开源框架合集

欢迎大家一键三连支持,若需要文中资料,直接点击文末CSDN官方认证微信卡片免费领取↓↓↓


















 6525
6525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









