







Spark运行原理
spark是一个分布式,基于内存的适合迭代计算的大数据计算框架。
基于内存,在一些情况下也会基于磁盘,spark计算时会优先考虑把数据放到内存中,应为数据在内存中就具有更好的数据本地性;如果内存放不下时,也会将少量数据放到磁盘上,它的计算既可以基于内存也可以基于磁盘,它适于任何规模的数据的计算。
Spark想用一个技术堆栈解决所有的大数据计算问题。大数据计算问题主要包括:交互式查询(基于shell和sql)、流处理(数据流入后直接进行处理)和批处理(基于Spark内核进行的一个RDD级别的编程,同时还包含图计算、机器学习的内容)。
目前Spark支持的5中计算范式:流处理(Streaming)、SQL、R、图计算、机器学习等。
从三个方面去理解Spark :
1.分布式:
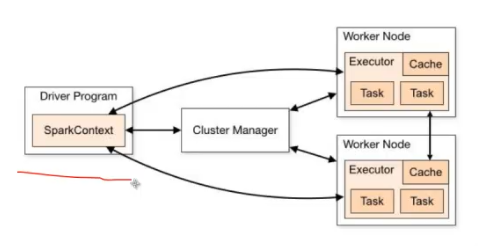
在生产环境下,是在分布式多台机器下去运行的。它会有几个特征:Spark会有一个Driver端,也就是所谓的客户端,我们自己编写的程序,要提交给集群;而在集群中有很多机器,整个作业的运行实际上是运行在分布式的节点(默认一台机器是一个节点)中的。
Spark程序提交到Spark集群上进行运行,运行时要处理一批数据,由于它是分布式的,所以运行时不同的节点会处理其中一部分数据。各个部分节点处理数据时互不干扰。所以,在做分布式时,可以并行化,即处理数据更快。
例子:图书馆有很多书架和书,单机版本是线性的第一个书架到第二个书架累计相加;分布式,图书馆长作为总控制器Cluster Manager,派1000个人,每个人负责一个书架的书的信息计算,1000个人便可以并行计算,结果再统一到馆长,馆长再对结果进行统计。
2.基于内存
Spark优先考虑使用内存,其实是是对计算机资源最大化利用的一个物理基石。如果内存不够,也可以基于磁盘,优先考虑内存。运用得当,会比hadoop快10X倍。
3.迭代式计算
放于内存中的数据,经过第一个阶段的计算后,处理的结果可以继续在其他节点上进行下一个阶段的计算。这就是迭代计算。
擅长迭代式计算是Spark的真正精髓。在实际如果要对数据进行稍有价值的挖掘或是对数据进行稍有复杂度的一些挖掘,一定是要对数据进行具有多步骤的计算。这时候就要用到迭代式的计算,而Spark天生就是适用于分布式的主要基于内存的迭代式计算。Spark基于磁盘的迭代式计算会比hadoop快10x倍,而Spark基于内存的迭代式计算要比hadoop快100x倍。这里要提一下,当作业计算完第一个阶段,然后移动另一个节点中进行计算,数据不移动,代码移动,也就是所谓为的shuffle,而且可以反复的shuffle,并形成一个链条,这就是迭代。
在读取文件时,hadoop每次都是都是读取磁盘和写入磁盘,而Spark是基于内存的,大部分中间计算结果是保存在内存中,下一次计算是基于内存的计算结果的,所以节省了读取磁盘的时间。Spark的高速运行除了基于内存,主要原因还是因为他的调度器(基于DAG之上的调度器,有高层调度器和底层调度器和容错)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3959
3959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









