






本文主要讲解下Python加载csv文件的两种方式,如果知道如何处理的就不必往下看了!
下面来简单介绍下。
实例中的数据集是kaggle的Digit Recognizer的train.csv文件,数据格式很特别也很普遍,截图如下:

csv文件中每行数据的每个特征列都是用逗号“,”隔开。CSV文件中除了保存数值外,还有一些属性值,如第一行以及第一列的label标签。所以在处理是需要进行相应的处理。
下面介绍下两种加载这种csv文件的方法
方法一:使用Python的csv模块
csv模块中的函数
reader(csvfile, dialect='excel', **fmtparams)参数说明:
csvfile,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象,如果是文件对
象,打开时需要加”b”标志参数。
dialect,编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义,通过调用register_dialect方法来注册,下文会提到。
fmtparam,格式化参数,用来覆盖之前dialect对象指定的编码风格。
加载文件代码:
import csv
def loadCSVfile1():
list_file = []
with open('train.csv','rb') as csv_file:
all_lines=cvs.reader(csv_file)
for one_line in all_lines:
list_file.append(one_line)
list_file.remove(list_file[0])
arr_file = array(list_file)
label = arr_file[:, 0]
data = arr_file[:, 1:]
return data, label 加载csv核心部分还是
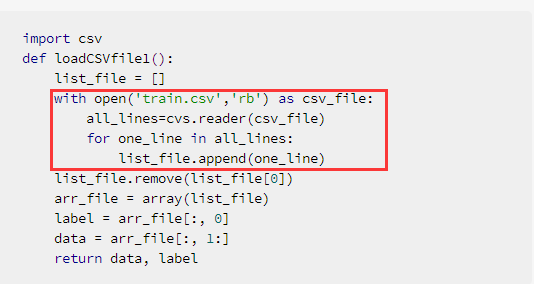
其中,‘rb’中的r表示“读”模式,因为是文件对象,所以加‘b’。open()返回了一个文件对象
myFile,reader(myFile)只传入了第一个参数,另外两个参数采用缺省值,即以excel风格读入。reader()返回一个
reader对象all_lines,all_lines是一个list,当调用它的方法lines.next()时,会返回一个string。上面程序的效果是将csv
文件中的文本按行打印,每一行的元素都是以逗号分隔符’,’分隔得来。
方法一:使用Python的numpy库
有了numpy,Python对于数据的处理可以说是如虎添翼,速度也大大提升。使用numpy首先要在前面加载numpy库,代码如下:
import numpy as np对于上面的csv文件,下面程序用来读取数据部分:
def loadCSVfile2():
tmp = np.loadtxt("train.csv", dtype=np.str, delimiter=",")
data = tmp[1:,1:].astype(np.float)#加载数据部分
label = tmp[1:,0].astype(np.float)#加载类别标签部分
return data, label #返回array类型的数据三行代码,很简便。最后的结果是array类型,type为float64

代码很简单,仅供参考!















 5046
5046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









