







最近在开发jSqlBox过程中,想研究一下树形结构的和VO对象树的转换,突然发现一种新的树结构数据库存储方案,在网上搜索了一下,没有找到雷同的(也可能是我花的时间不够)方案,现介绍如下:
目前常见的树形结构数据库存储方案有以下四种,但是都存在一定问题:
1)Adjacency List::记录父节点。优点是简单,缺点是访问子树需要遍历,发出许多条SQL,对数据库压力大。
2)Path Enumerations:用一个字符串记录整个路径。优点是查询方便,缺点是插入新记录时要手工更改此节点以下所有路径,很容易出错。
3)Closure Table:专门一张表维护Path,缺点是占用空间大,操作不直观。
4)Nested Sets:记录左值和右值,缺点是复杂难操作。
以上方法都存在一个共同缺点:操作不直观,不能直接看到树结构,不利于开发和调试。
本文介绍的方法我暂称它为“简单粗暴多列存储法”,它与Path Enumerations有点类似,但区别是用很多的数据库列来存储一个占位符(1或空值),如下图(https://github.com/drinkjava2/Multiple-Columns-Tree/blob/master/treemapping.jpg) 左边的树结构,映射在数据库里的结构见右图表格:
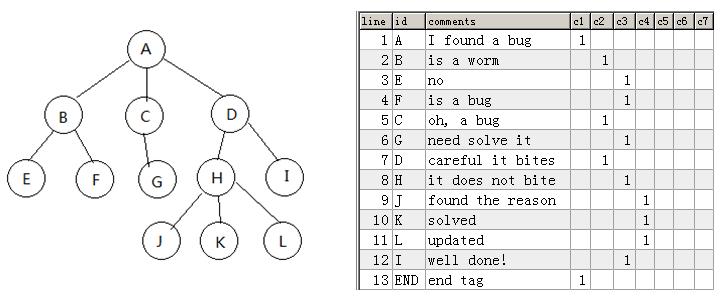
各种SQL操作如下:
1.获取(或删除)指定节点下所有子节点,已知节点的行号为"X",列名"cY":
select *(or delete) from tb where
line>=X and line<(select min(line) from tb where line>X and (cY=1 or c(Y-1)=1 or c(Y-2)=1 ... or c1=1))
例如获取D节点及其所有子节点:
select * from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
删除D节点及其所有子节点:
delete from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
仅获取D节点的次级所有子节点:
select * from tb where line>=7 and c3=1 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
2.查询指定节点的根节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<=X and c1=1)
例如查I节点的根节点:
select * from tb where line=(select max(line) from tb where line<=12 and c1=1)
3.查询指定节点的上一级父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
例如查L节点的上一级父节点:
select * from tb where line=(select max(line) from tb where line<11 and c3=1)
3.查询指定节点的所有父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
union select
目前常见的树形结构数据库存储方案有以下四种,但是都存在一定问题:
1)Adjacency List::记录父节点。优点是简单,缺点是访问子树需要遍历,发出许多条SQL,对数据库压力大。
2)Path Enumerations:用一个字符串记录整个路径。优点是查询方便,缺点是插入新记录时要手工更改此节点以下所有路径,很容易出错。
3)Closure Table:专门一张表维护Path,缺点是占用空间大,操作不直观。
4)Nested Sets:记录左值和右值,缺点是复杂难操作。
以上方法都存在一个共同缺点:操作不直观,不能直接看到树结构,不利于开发和调试。
本文介绍的方法我暂称它为“简单粗暴多列存储法”,它与Path Enumerations有点类似,但区别是用很多的数据库列来存储一个占位符(1或空值),如下图(https://github.com/drinkjava2/Multiple-Columns-Tree/blob/master/treemapping.jpg) 左边的树结构,映射在数据库里的结构见右图表格:
各种SQL操作如下:
1.获取(或删除)指定节点下所有子节点,已知节点的行号为"X",列名"cY":
select *(or delete) from tb where
line>=X and line<(select min(line) from tb where line>X and (cY=1 or c(Y-1)=1 or c(Y-2)=1 ... or c1=1))
例如获取D节点及其所有子节点:
select * from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
删除D节点及其所有子节点:
delete from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
仅获取D节点的次级所有子节点:
select * from tb where line>=7 and c3=1 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
2.查询指定节点的根节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<=X and c1=1)
例如查I节点的根节点:
select * from tb where line=(select max(line) from tb where line<=12 and c1=1)
3.查询指定节点的上一级父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
例如查L节点的上一级父节点:
select * from tb where line=(select max(line) from tb where line<11 and c3=1)
3.查询指定节点的所有父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
union select
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









