







 本文介绍了从文本中抽取特征的过程,包括词袋模型的概念、停止词过滤、词干提取和词形还原,以及TF-IDF的重要性。在机器学习任务中,特征工程对模型性能至关重要,而文本特征抽取是其中的关键步骤。
本文介绍了从文本中抽取特征的过程,包括词袋模型的概念、停止词过滤、词干提取和词形还原,以及TF-IDF的重要性。在机器学习任务中,特征工程对模型性能至关重要,而文本特征抽取是其中的关键步骤。
从文本抽取特征
Extracting features from text
最近在做SIGHAN的task 2情感分类任务,在这样的二分类/三分类问题中,最重要的就是文本特征的提取和选择,也就是:
特征工程决定了最终的算法上限,而模型的选择和调参决定了分类和预测和该上限的距离
简单介绍一下利用sklearn抽取文本特征的过程
词带模型
* The Bag-of-words representation*
Bag-of-words可以看成是one-hot encoding的扩展,为文本每一个(所关注的)词构建一个特征,因而一个文本对应了一个特征向量。该模型基于:
包含了较多类似的(similar)词的文档,表达的内容也往往相似
- corpus 语料库,是文档的集合
- vocabulary 在corpus中的unique的词的集合
- dimension doc对应的特征向量的维度,一个语料库在处理过程中dimension是一致的,因为是由vocabulary的维度确定的
- dictionary 特征向量每个元素对应的词需要一个dictionary来map
例如我们这里的迷你corpus:
corpus = {
'UNC played Duke in basketball',
'Duke lost the basketball game'
}由8个不同的词组成了vocabulary:
['UNC','played','Duke','in','baskball','lost','the','game']在这个例子中dimension因此就是8. 上面这个list也就代表了dictionary,第一个词UNC映射到了向量的第一个元素。
词袋模型一般选择binary value来表示每个词,1表示该次在文本中出现,0则反之。例如上个例子的corpus中的两个文档对应的向量为:
[1, 1, 1, 1, 1, 0, 0, 0]
[0, 0, 1, 0, 1, 1, 1, 1]sklearn中的CountVectorizer 类可以将一个string或是file处理成bag-of-words representation。需要说明的是CountVectorizer 类默认会做两件事:
- lowercase
- tokenize
Tokenization是将字符串分割为一个个独立的token或是有意义的词串(邮箱)的过程。Tokens通常是一个个词,也可能是短语,可能会带有标点或是前缀。CountVectorizer 类使用正则表达式利用空格来分割字符串。
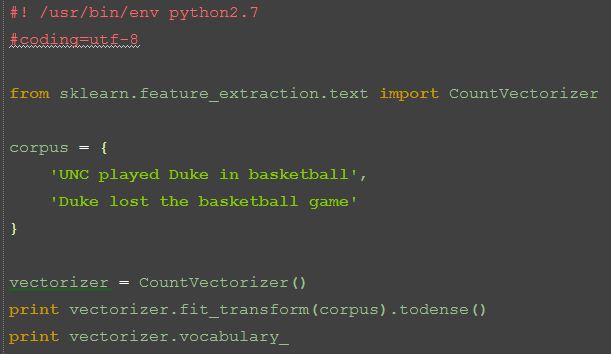
上述代码结果:

CountVectorizer().
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









