







缓存分为L1,L2和L3缓存。L1和L2缓存通过在每个核的片上,L3缓存通常是共享的。通过缓存也称作SRAM,两者可以不加区分。缓存的读取延时一般是2ns.
缓存的结构:
首先,分为不同的集合(Set),每个集合中有若干缓存行(Cache Line)(1或者多个)。
如图(来源:http://wdxtub.com/2016/04/16/thin-csapp-3/):
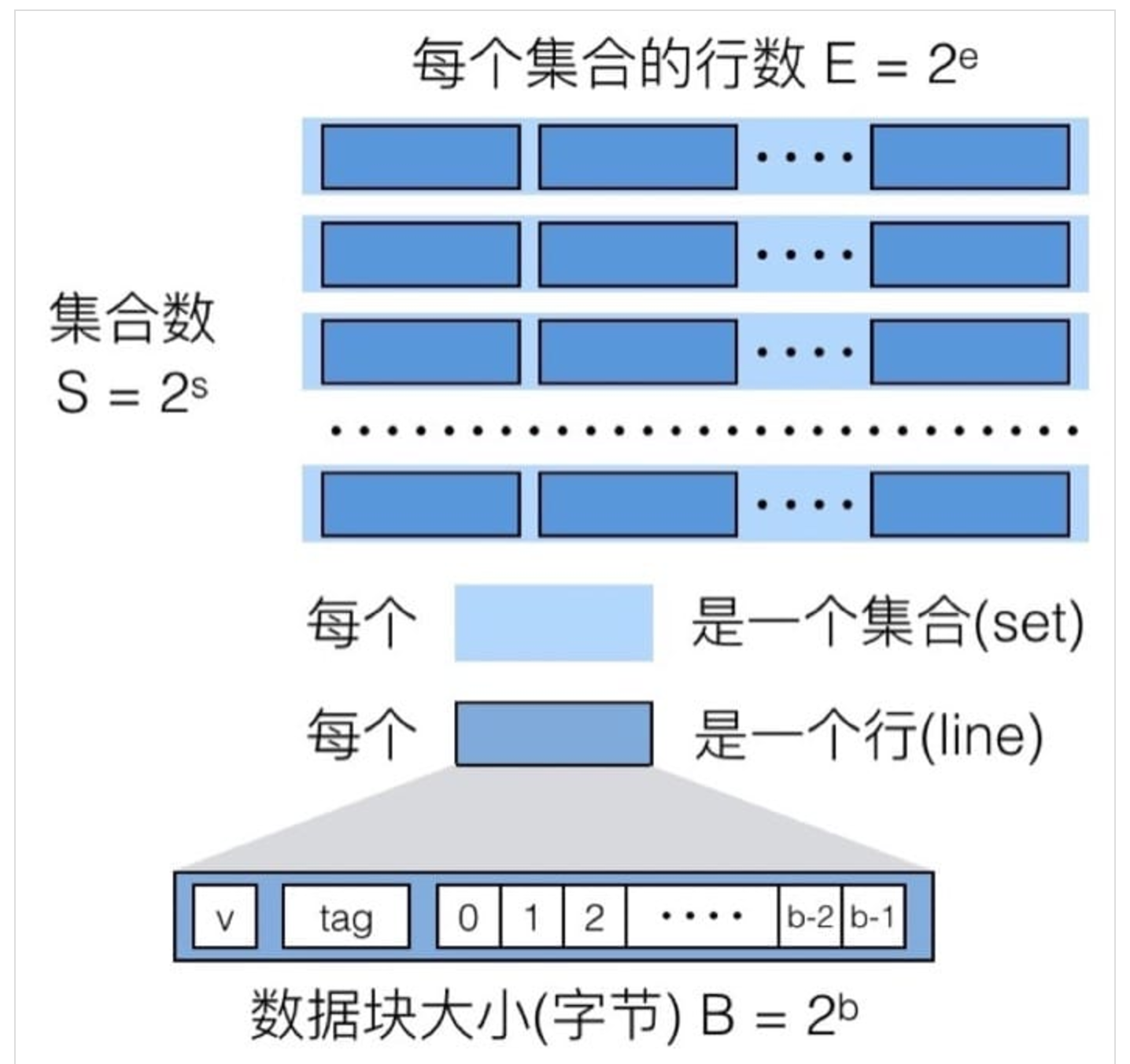
缓存的数据定位也是每一个地址对应一个byte的。通常而言,每个缓存行的大小使64Bytes. 其中,每个缓存行除了数据外,还有tag(用来match地址中的tag)以及valid位告诉查询者当前内容是否有效(是否过期)。
当我们收到要读取的内容地址后,我们对该内容地址进行如下的分割解读:

根据内存地址的分割,我们用set(s bits)的内容定位一个集合。用tag (t bits)来定位是该集合的某一行。用bias (b bits)来定位是该行的数据的定位。
缓存与程序加速:
Spatial Locality:
因为缓存和主存的读取数据时间是2ns和10ns,所以,如果我们能把并行计算所采用的数据都一次读进来主存,让每个线程都同时从缓存中读取数据的话,将会大大提高并行的效率。这种把相邻线程的数据放在相邻的缓存空间成为spatial locality. 或者,如果在串行运算中解释的话,将来可能会用到的信息,在当前的数据读进来的时候顺便也读了进来(因为都是一个字一个字地读),这样在下一步要读这个信息的时候,就不需要再从主存读了。
Time Locality:
而另一种加速的方向则是,多次重复利用已经写入缓存的数据。如矩阵乘法当中,使用分块的方法,让分块的内容可以放进缓存并在计算中多次利用。这叫time locality.
缓存与伪共享:
当两个变量在缓存中属于一个缓存行的时候,不同核的线程(这里指的是系统级线程,因为只有系统级线程才会用到不同的核)因为使用不同的缓存,所以如果两个线程想同时分别更新这两个变量的时候,因为他们都属于同一个缓存行,所以必须串行更新。伪共享会极大损害并行的效率。需要分析工具分析两个变量是否存在伪共享。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









