






上一篇文章简单学习了 AlphaGo Zero 的特点:
AlphaGo Zero 初探
http://www.jianshu.com/u/7b67af2e61b3
算法采用自对弈强化学习,不再需要学习人类棋谱数据。
模型由原来的两个模型变成只使用一个神经网络。
今天来学习一下细节。
论文:
Mastering the game of Go without human knowledge
先将围棋问题转化为强化学习过程:

一个棋盘上有 19×19=361 个交叉点可以落子。
每个点有三种状态,白,黑,无子,分别用 1,-1,0表示。
这样一个棋盘的状态是一个长为 361 的向量 S。
下一步的落子行动用 a 表示,也是长为 361 的向量,例如第几个位置为 1 就表示在棋盘上换算后相应的第几行第几列下白子。
这样围棋问题就转化为:任意给定一个状态 S,寻找最优的应对策略 a,使得能够获得棋盘上的最大地盘。
AlphaGo Zero 的网络结构:
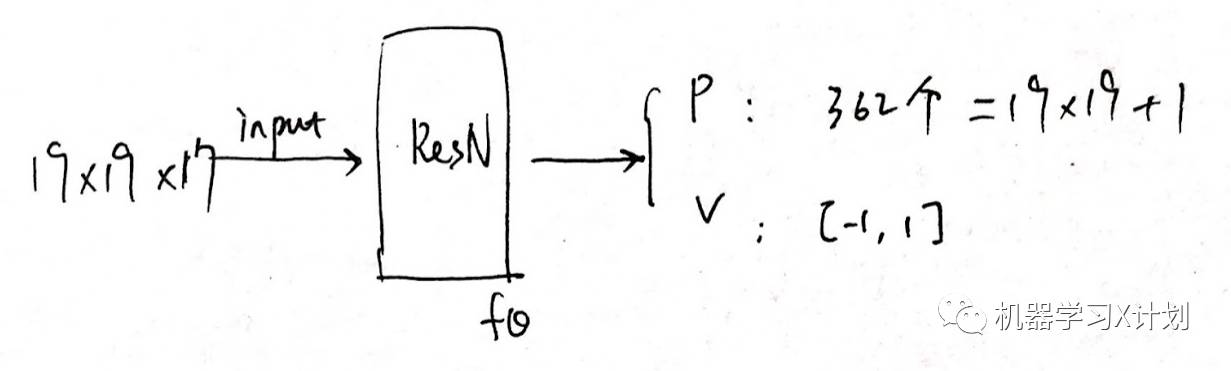
是基于 ResNet 的卷积网络,包含 20 或 40 个 Residual Block,加入批量归一化和非线性整流器模块。
输入为 19×19×17 的 0/1 值:包括17个二元特征平面的图像堆栈。
(The input to the neural network is a 19 × 19 × 17 image stack comprising 17 binary feature planes.)
输出为 落子概率 p 和一个评估值 v。P 即下一步在每一个可能位置落子的概率,v 表示当前选手在输入的历史局面下的胜率。
(A fully connected linear layer that outputs a vector of size 19×19 + 1 = 362, corresponding to logit probabilities for all intersections and the pass move)
自对弈强化学习算法:
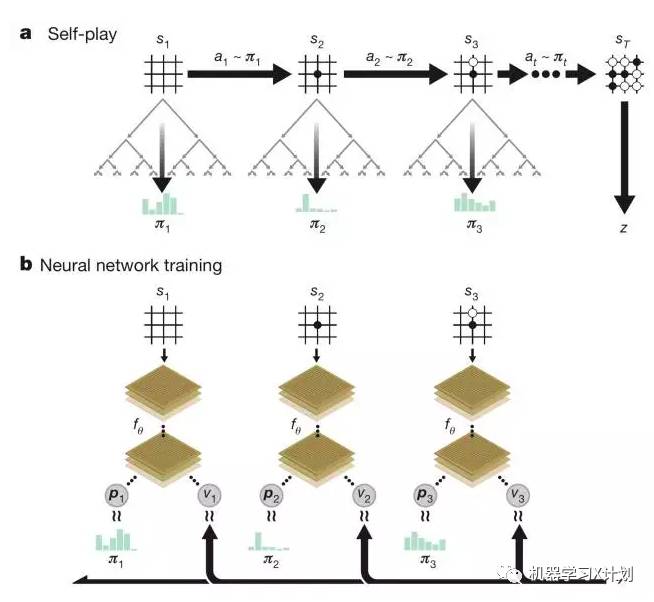
在每一个状态 S,利用深度神经网络 fθ 的输出作为参照执行 MCTS 蒙特卡洛搜索树算法,MCTS 搜索的输出是每一个状态下在不同位置对应的概率 π。
上图 a 表示自对弈过程 s1,…,sT。在每一个位置 st,使用最新的神经网络 fθ 执行一次 MCTS,根据得出的概率 at∼πi 落子,终局计算出胜者 z。
上图 b 表示神经网络 fθ 的参数更新过程。st 作为输入,得到下一步所有可能落子位置的概率分布 pt 和当前状态下选手的赢棋评估值 vt。
更新参数 θ 时,以最大化 pt 与 πt 的相似度和最小化预测的胜者 vt 和局终胜者 z 的误差为目标。
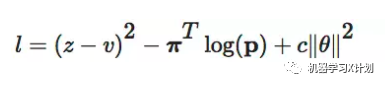
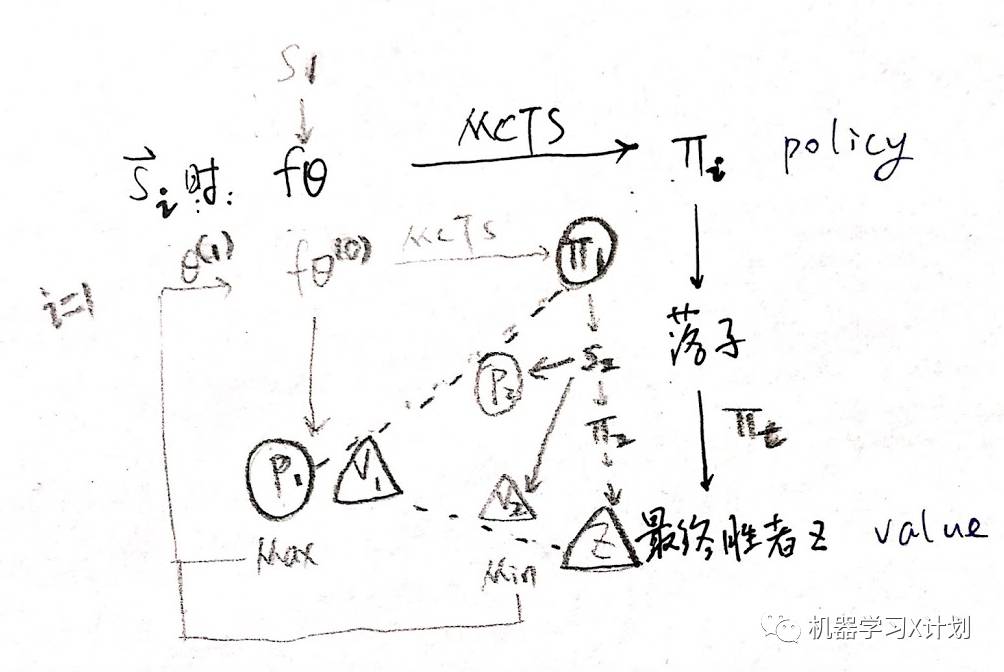
随机初始化 θ0
每一轮迭代 i⩾1,都自对弈一盘
第 t 步 MCTS 搜索 πt 进行落子
神经网络 fθ 以最大化 pt 与 πt 的相似度和最小化预测的胜者 vt 和局终胜者 z 的误差来更新参数 θ
学习资料:
https://www.nature.com/articles/nature24270.epdf?author_access_token=VJXbVjaSHxFoctQQ4p2k4tRgN0jAjWel9jnR3ZoTv0PVW4gB86EEpGqTRDtpIz-2rmo8-KG06gqVobU5NSCFeHILHcVFUeMsbvwS-lxjqQGg98faovwjxeTUgZAUMnRQ
https://charlesliuyx.github.io/2017/10/18/%E6%B7%B1%E5%85%A5%E6%B5%85%E5%87%BA%E7%9C%8B%E6%87%82AlphaGo%E5%85%83/
推荐阅读原文
也许可以找到你想要的:
[入门问题][TensorFlow][深度学习][强化学习][神经网络][机器学习][自然语言处理][聊天机器人]














 2082
2082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









