







论文原文:
github上的复现,膜拜大神:
https://github.com/junxiaosong/AlphaZero_Gomoku
alphago Zero模型的理解:
0.应用场景:完美信息零和博弈游戏。
1.不再使用监督数据对模型进行训练,使用自博弈的方式,自动生成数据,学习围棋的知识。
2.前向搜索很有用,使用前向搜索的alphago Zero得分5185,使用裸网络的得分为3055,打不过alphago,这说明mcts的思路很有用
3.MCTS参与训练,这在之前是没有的,具体怎么实现的?
4.AlphaGo Zero 所使用的卷积神经网络的输入是 19 × 19 × 17 的张量 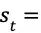
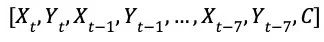 ,其 17 个通道中,
,其 17 个通道中,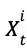 表示 t 时刻棋盘上第 i 个位置是否有己方的棋子,
表示 t 时刻棋盘上第 i 个位置是否有己方的棋子, 表示 t 时刻棋盘上第i个位置是否有对方的棋子,C 是一个常数,用于标识当前轮次的颜色。也就是使用了原始输入+时间序列作为输入,没有人工选择特征。每层都是二进制特征。之所以包含历史信息,是因为当前的局面不能代表全部的信息,比如一些重复的动作?
表示 t 时刻棋盘上第i个位置是否有对方的棋子,C 是一个常数,用于标识当前轮次的颜色。也就是使用了原始输入+时间序列作为输入,没有人工选择特征。每层都是二进制特征。之所以包含历史信息,是因为当前的局面不能代表全部的信息,比如一些重复的动作?
具体实现小技巧:
a = np.array([[0, 0, 0], [0, 0, 0], [0, 0, 0]]) # 棋盘
b = np.array([0, 2, 4, 6]) # 有子的位置
a[b // a.shape[0], b % a.shape[1]] = 1 # 长和宽
print(a)
[[1 0 1]
[0 1 0]
[1 0 0]]在复现程序中,使用了4层,分别为己方位置、敌方位置、上一步的动作、当前颜色。上一步动作只在棋盘上画一个点。
5.胜率超过55%,替换新的模型
6.在蒙特卡洛树搜索中,将Dirichlet噪声添加到根节点(板状态)的先验概率上,保证可以尝试所有动作,但是搜索可能仍会否决不良动作。什么意思,类似ε-greedy策略吗?
7.估值网络的结构:
使用包含40个残差结构的网络,效果很好。在有监督学习中,准确性也比之前的好。
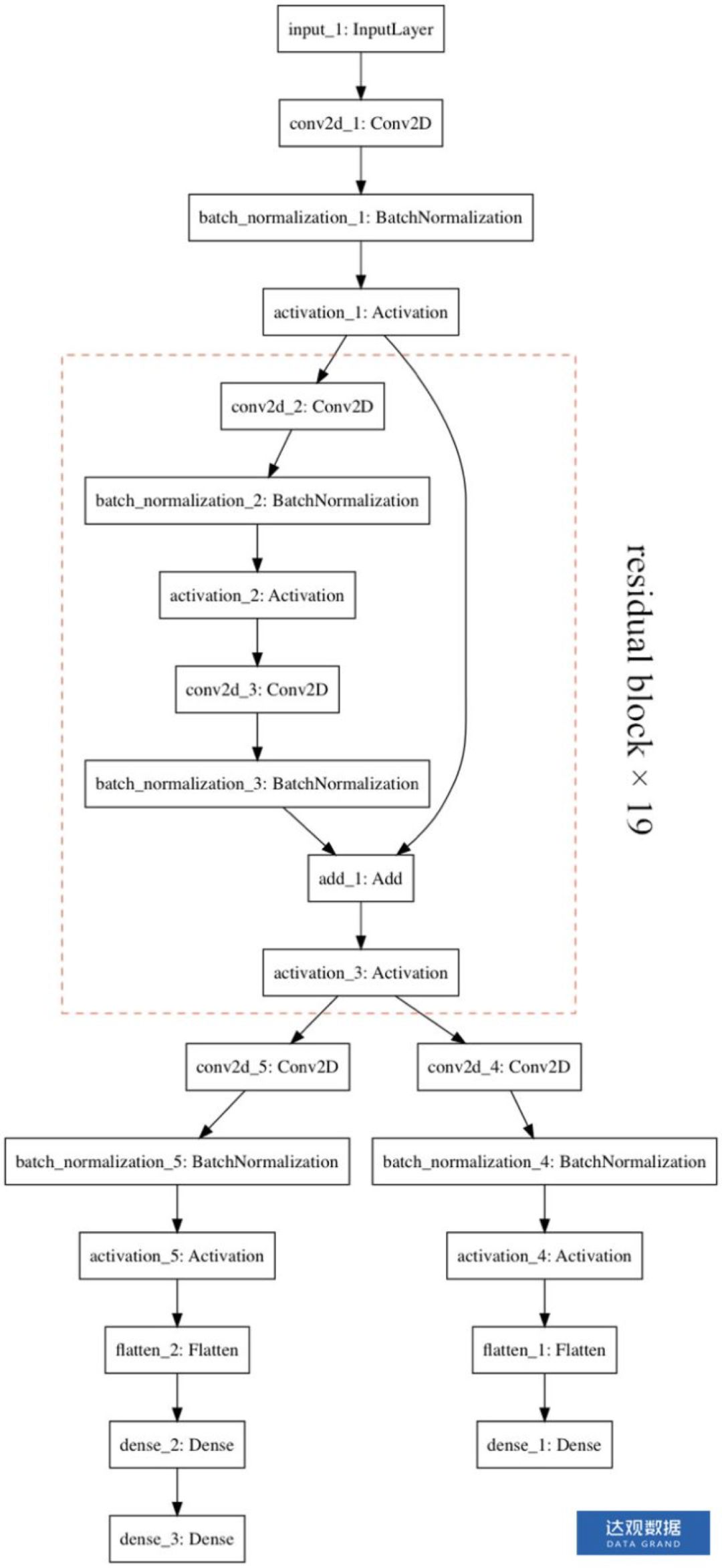
这种两头的结构有什么优势?
这个网络输出两个值,一是对当前节点的评估值,方便选择己方的下一步落子,二是下一步可能的落子位置的概率序列,方便mcts使用。
8.损失函数:
L=(z−v)2−πTlog(p)+c||θ||2
训练的目的是对于每个输入ss, 神经网络输出的p,vp,v和我们训练样本中的π,zπ,z差距尽可能的少。
损失函数由三部分组成,第一部分是均方误差损失函数,用于评估神经网络预测的胜负结果和真实结果之间的差异。第二部分是交叉熵损失函数,用于评估神经网络的输出策略和我们MCTS输出的策略的差异。第三部分是L2正则化项。
9.训练模型的时候,对自博弈数据进行拓展,因为围棋有对称平移不变形,算是个训练小技巧。
疑惑:
1.神经网络的双头结构的有什么好处?理论基础呢?
2.损失函数的第二项为什么和原来的策略越接近越好?有什么依据?














 2054
2054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









