







目录
1、前面
2、java线程池
3、c++线程池
4、区别
5、写一个
6、使用
7、其它
内容
1、前面
线程池主要用于减少应用程序线程的数量并提供工作线程的管理。应用程序可以排队工作项,将工作与可执行的句柄关联起来,根据定时器自动排队,并与I / O绑定。像 Android里面就很多地方用到了线程池,如 AsyncTask 等等。
说到线程池,就先说下享元模式。
享元模式
享元模式:一组对象的集合,对于全局的对象创建,通过对象共享池的方式减少对象的创建
单例模式:保证一个类只有一个对象
和单例模式区别:享元模式并不是为了提供唯一的对象访问
但两者都是为了减少内存消耗,提升性能
java 和 android 中用到享元模式的例子有以下等等:
a、android 系统 drawable 全局缓存
在 android.content.res 包 的 ResourcesImpl.java 中,如下
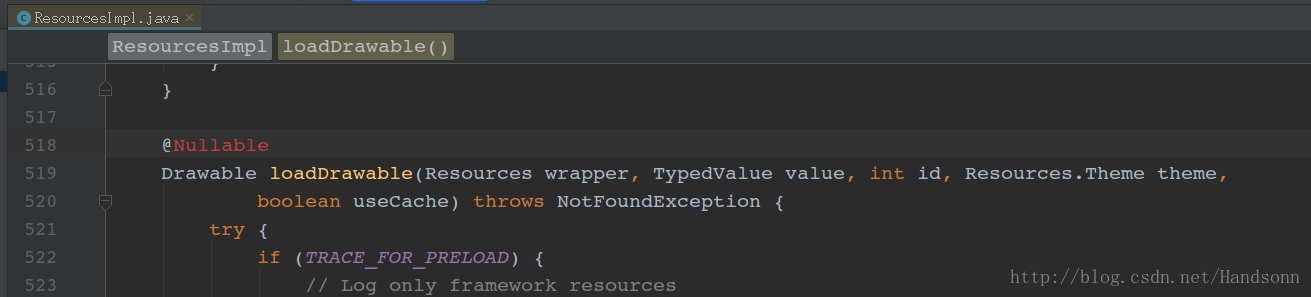
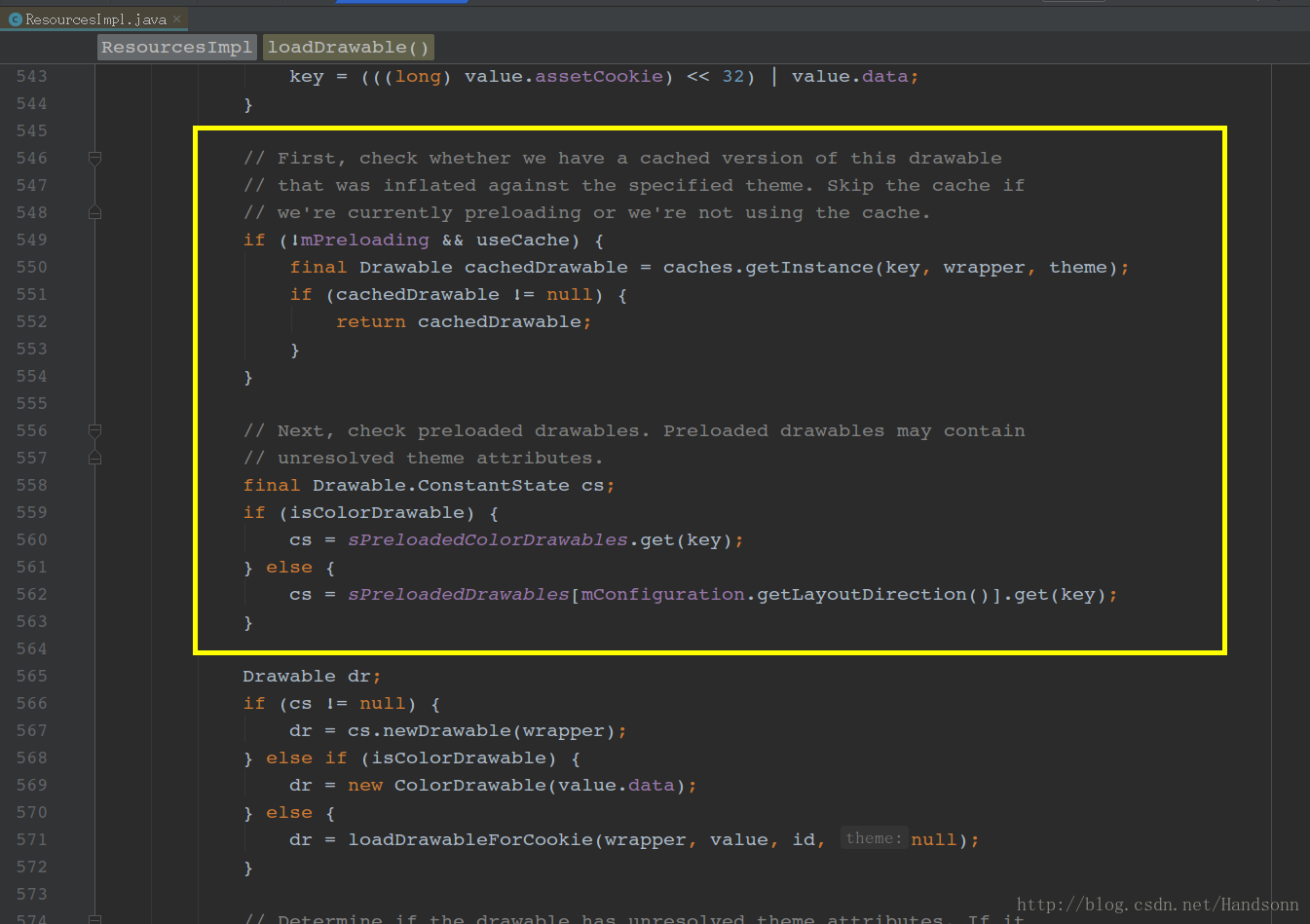
可以看到,系统有一份全局的缓存 sPreloadedDrawables ,每次获取 drawable 时,系统会从缓存中取出这个 bitmap 然后构造 drawable 。
( pS: 这里也有一些坑,如果我们使用这个获取复用的 bitmap ,执行 recycle 之类的操作,就会报错 “trying to use a recycled bitmap android.graphics.Bitmap”, 在之前 使用过 Glide 处理大头像的过程中也遇到过这种情况,具体解决方法是 :忽略 Glide 的缓存 )
b、String字符串常量池
常量池是不同于堆和栈的独立内存,常量池中最多只有一份相同的字符串对象
c、数据类型缓存
Integer : -128 到 127
Boolean:全部缓存
Byte:全部缓存
Character : <= 127
Short : -128 到 127
Long : -128 到 127
d、rxjava的Schedulers
该线程池提供了多种线程 Schedulers.io() 、 Schedulers.computation() 、 Schedulers.newThread() 等
e、rxjava的zip操作符
f、IPC里面的Binder连接池
具体可以参考 《Android开发艺术探索》 一书介绍
g、数据库连接池
。。。
另外,线程池还涉及到了 生产者-消费者 模式等等,这里就不赘述。
2、java线程池
我的是 JDK 1.8 的版本
1)、JDK1.7 以前常用这4种
a、newSingleThreadExecutor
b、newFixedThreadPool
c、newCachedThreadPool
d、newScheduledThreadPool
对于以上四种,
a、b、c 内部都调用了 new ThreadPoolExecutor()
d 内部调用了 new ScheduledThreadPoolExecutor(),而 ScheduledThreadPoolExecutor() 是 ThreadPoolExecutor() 的子类
所以只需看看 ThreadPoolExecutor()

具体的参数说明在文档里注释有解释 :
a、corePoolSize: 核心线程数,默认情况下,核心线程会一直在线程池中存活,即使处于闲置状态。如果将 ThreadPoolExecutor 的 allowCoreThreadTimeOut 设置为 true,那么闲置的核心新城在等待心任务到来是也会有超时策略,具体时间由keepalivetime 决定。
b、maximumPoolSize:线程池所能容纳的最大线程数,当活动线程超过到达这个数值后,后续的新任务将会被阻塞
c、keepAliveTime: 非核心线程超时时长,超过这个间隔非核心线程就会被回收
d、unit: 用于指定 keepAliveTime 的时间单位,这是一个枚举
e、workQueue: 通过 execute 提交的runnable 会存储在这里
f、handler:
关于 handler 有 四种 饱和策略:默认是AbortPolicy,会直接抛出 RejectedExecutionException

ThreadPoolExecutor.AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:由调用线程处理该任务
关于这四种常用的线程池使用的队列
newFixedThreadPool 如下图:

newSingleThreadExecutor 如下图:

newCachedThreadPool 如下图:

newScheduledThreadPool 如下图:
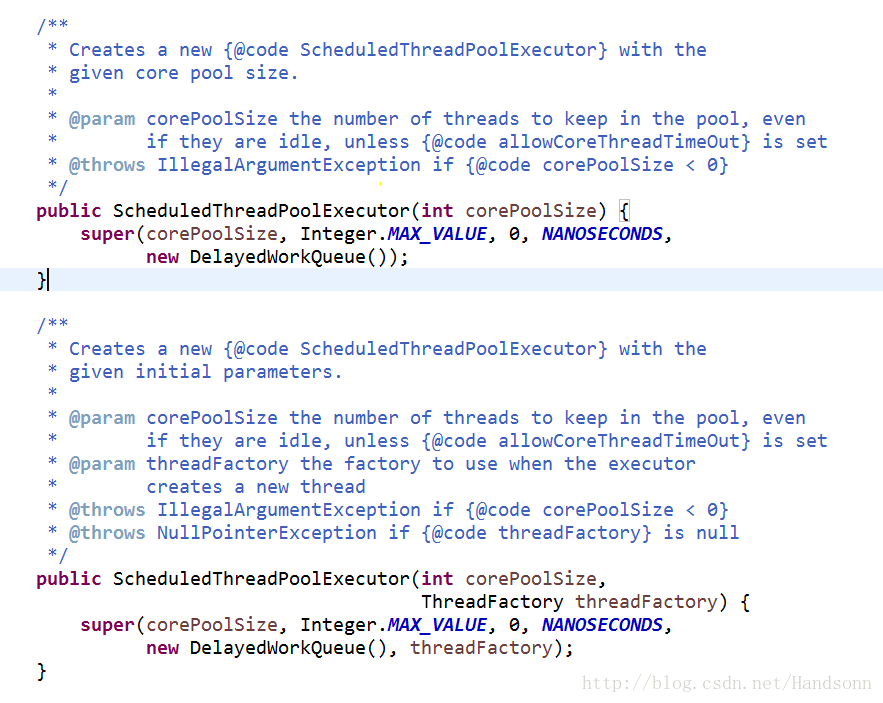
可以看到
a、newSingleThreadExecutor 和 newFixedThreadPool 使用的都是 LinkedBlockingQueue,链表队列,通过 Node 节点构造链表,具体可以看代码实现,( HashMap 中也是用 Node 节点构造链表 )

b、newCachedThreadPool 使用的是 SynchronousQueue
这是一个同步队列,队列的长度永远为0,每个插入操作必须等待另一个相应的删除操作线程,它不会保存提交的任务,而是将直接新建一个线程来执行新来的任务。
如下图:
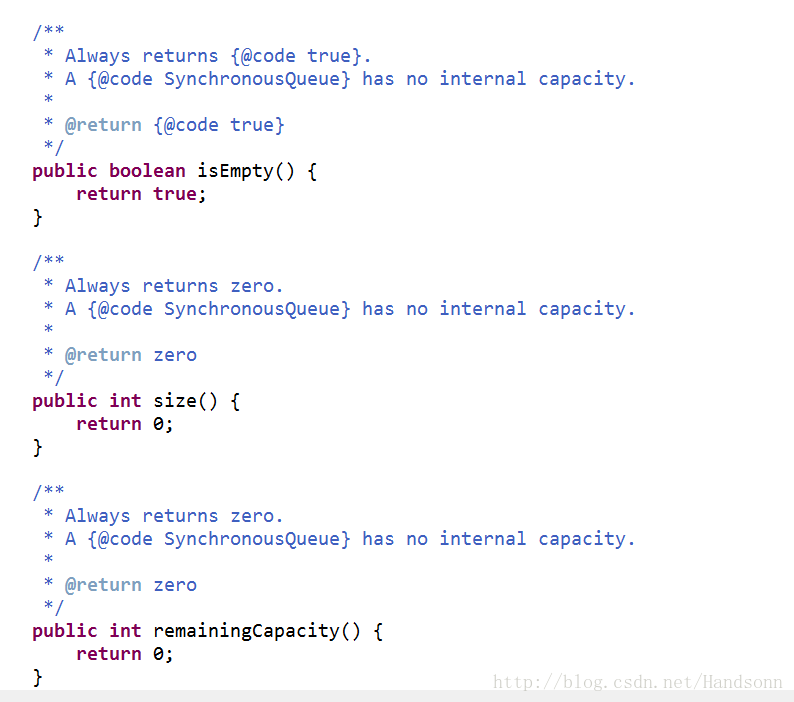
更多可以看代码具体实现
同步队列非常适合于切换设计,为了交付一些信息,事件或任务,在一个线程中运行的对象必须与在另一个线程中运行的对象同步。
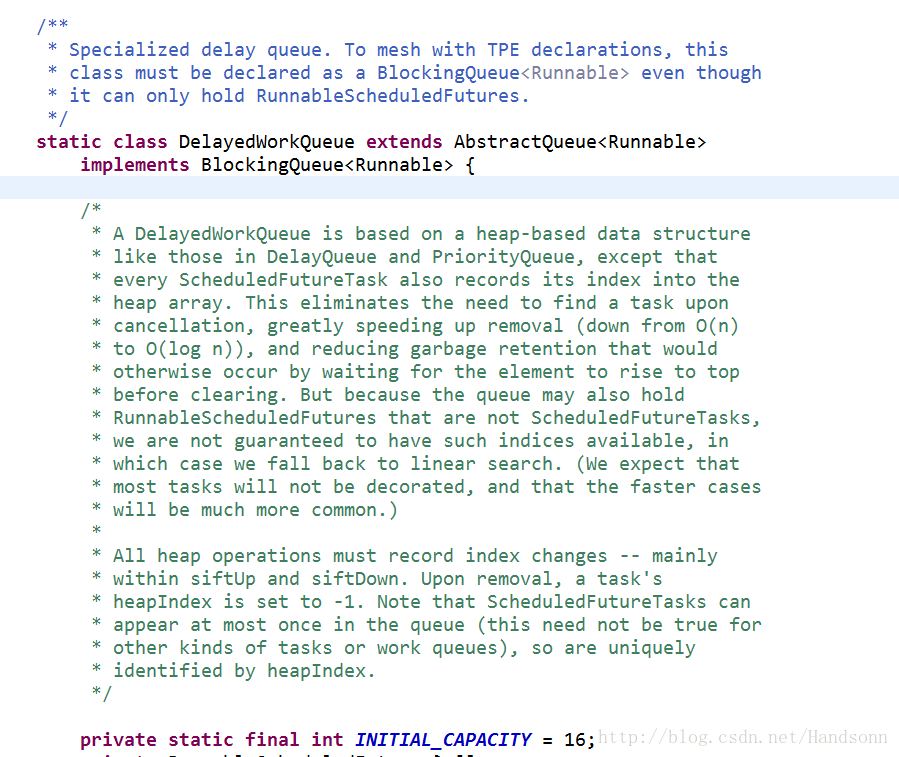
c、newScheduledThreadPool 使用的是 DelayedWorkQueue
看英文意思就是延时的队列,初始大小是16
关于 LinkedBlockingQueue ,与之对应的还有一个 ArrayBlockingQueue,后者是定长的,在一些情况下使用 ArrayBlockingQueue 比较好,个人理解:如有一个场景,假如服务器出问题,从数据库查询的数据需要通过线程池的 LinkedBlockingQueue,而这个时候出问题了导致阻塞,那么新来的任务就会由于阻塞让 LinkedBlockingQueue 无限增加,最后都有可能内存溢出,影响系统性能,进而影响系统使用。
2)、JDK 1.7 添加了 ForkJoinPool (PS:newWorkStealingPool 内部也是调用了 ForkJoinPool)
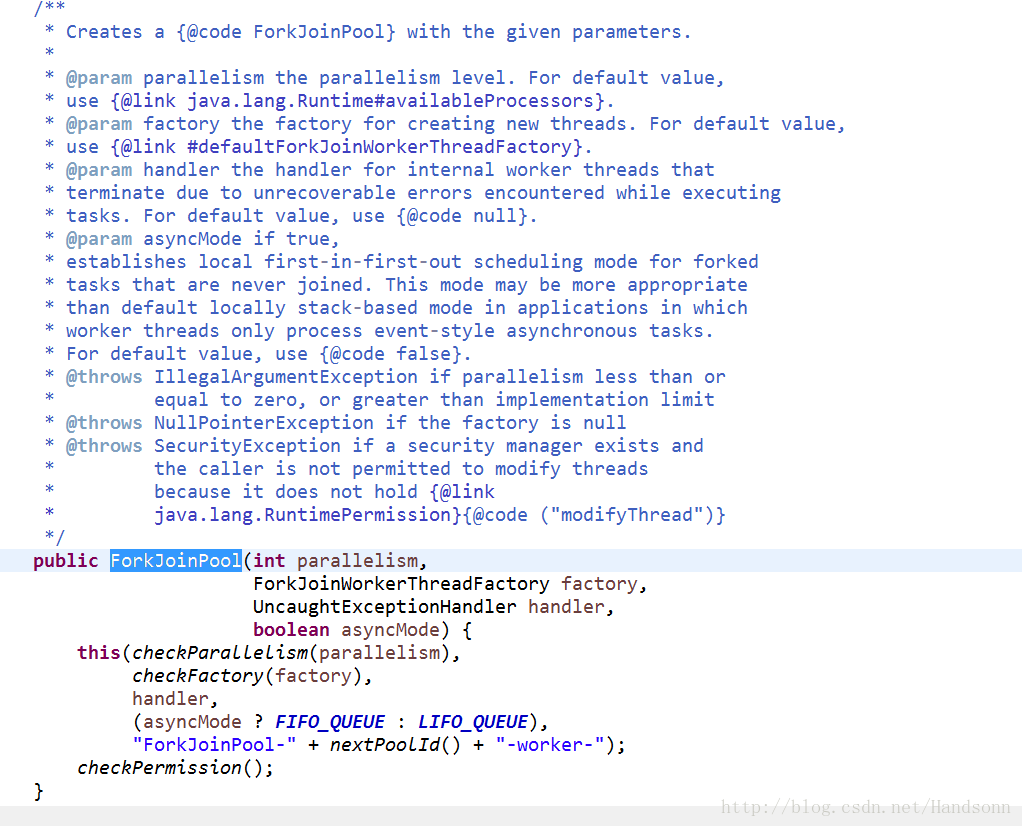
而 Java 8 为ForkJoinPool添加了一个通用线程池 CommomPool,具体可以看代码搜索,这个线程池用来处理那些没有被显式提交到任何线程池的任务,它是ForkJoinPool中一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量。
ForkJoinPool 使用了 一种任务窃取算法 ( Work-Stealing Algorithm ) ,这是一种有效的负载均衡调度策略,在并行计算中的一种调度算法,当一个任务队列执行完任务处于空闲时,就会从还没执行完任务的任务队列中“窃取”任务来执行,
Work-Stealing Algorithm 可以参考 维基百科 : https://en.wikipedia.org/wiki/Work_stealing
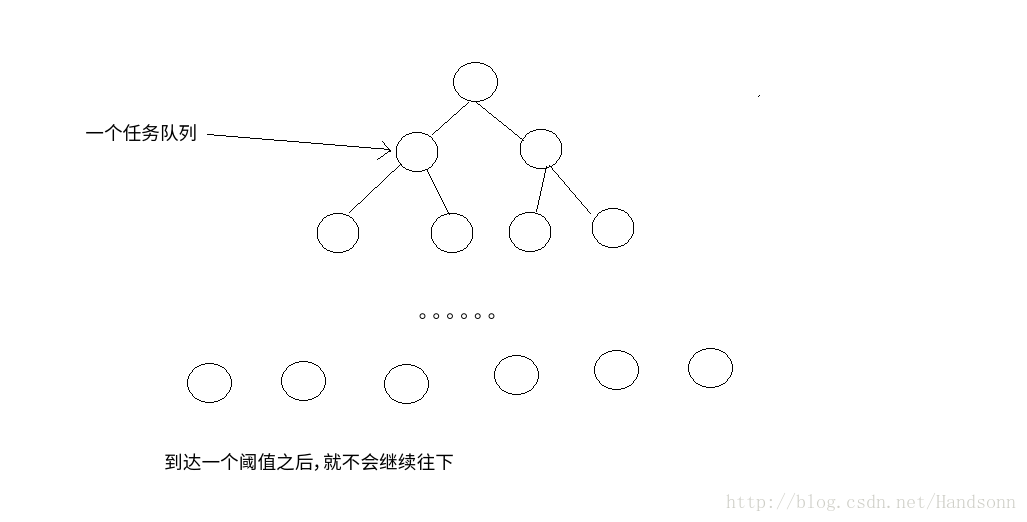
ForJoinPool 是根据 分治法 的思想来进行任务分配,如 有 100万个任务,会被分为多个子任务,反复递归,一直到一个阈值就会终止,因此,很重要的一点,这个阈值的取值会影响该线程池的执行性能 。
而关于任务的分发基本是“背包问题”,每个队列应该采取相同的时间量
比如有10个任务,每个任务时间长度不同,那么需要类似背包问题一样,通过时间量来进行分配,而不是简单的进行任务个数的平分。
俺们画个二叉树的图应该可以看出来:
ForkJoinPool 默认的线程数是处理器的数量 Runtime.getRuntime().availableProcessors(),如下图

在ForkJoinPool的运行过程中,会创建大量的子任务。而当它们执行完毕之后,会被垃圾回收,ThreadPoolExecutor则不会创建任何的子任务,因此不会导致任何的GC操作。所以在 gc 方面的时间也是需要考虑的,这个和 阈值的选取也有关。
另外,ForkJoinTask 提供了两个接口:
a、RecursiveAction 无返回值。
b、RecursiveTask 有返回值。
ForkJoinPool 由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责存放程序提交给ForkJoinPool
的任务,而ForkJoinWorkerThread数组负责执行这些任务。
更多具体说明可以参考 ForkJoinTask 类里面的调用和注释
ForkJoinPool 使用可以参考其它代码,例如,我们要两个数相加,可以一直分割成若干个小任务进行相加等等:
http://blog.csdn.net/dm_vincent/article/details/39505977
http://blog.csdn.net/xuguoli_beyondboy/article/details/44288047
ForkJoinPool 类中注意的几个 单词:
1、WorkQueues
2、Management
3、Joining Tasks
4、Common Pool
对于 java 线程池,还有两个可以注意的单词:
workercount

state

这里解释了各种情况下对应的 runState 。线程池的 runState 是 volitale 的,这个可以保证可见性,即保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。关于可见性,可以与 内存模型、原子性、有序性、happens-before原则 进行比较理解
线程池调整:
关于线程池容量的调整可以通过 setCorePoolSize 和 setMaximumPoolSize 来进行操作。
3、windows/c++线程池
c++ 11 的标准库并没有自带线程池
windows 提供了一个线程池机制,语法是通过 c++ 调用,有如以下 API:
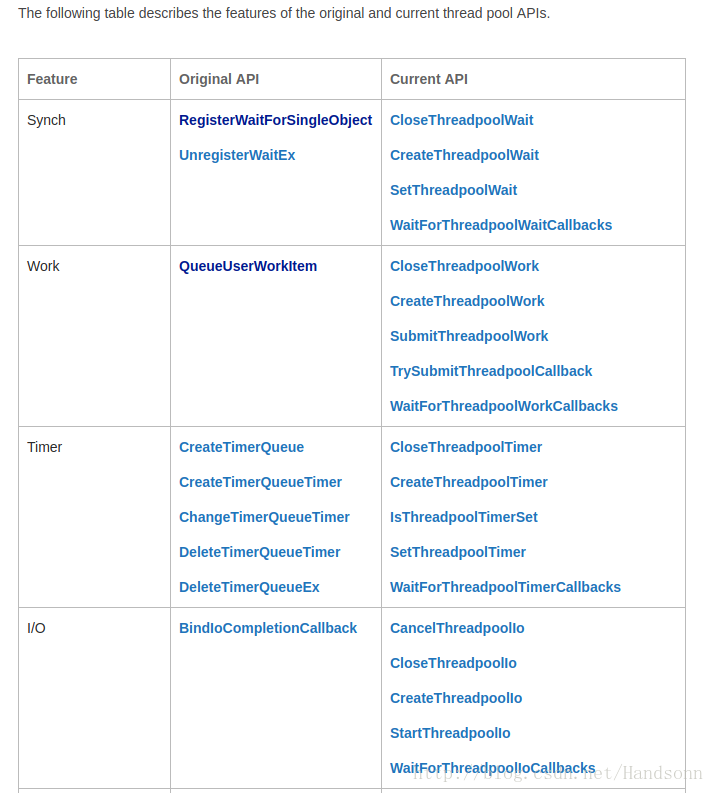
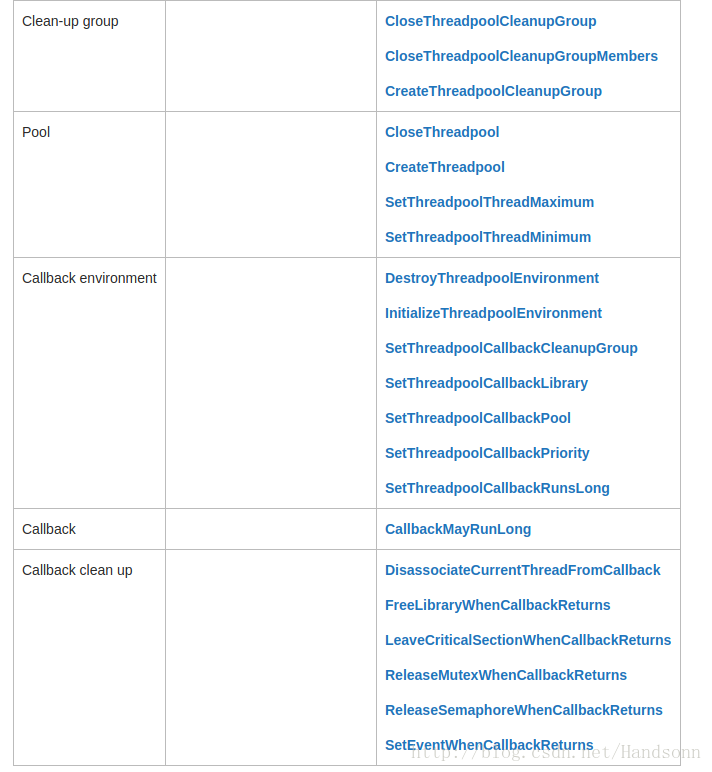
这些 API 可以有什么功能?
a、以异步的方式调用一个函数。 ———– 和 work 相关
b、每隔一段时间调用一个函数。———— 和 timer 相关
c、当内核对象触发时调用一个函数。—— 和 wait 相关
d、当异步IO请求完成时调用一个函数。— 和 I / O 相关
另外,清理组 clean up 关联每个 callback 对象,可以用于 释放 或者 等待,方便系统跟踪所创建的各种对象。
咱们自己通过画图来梳理它们之间的关联:
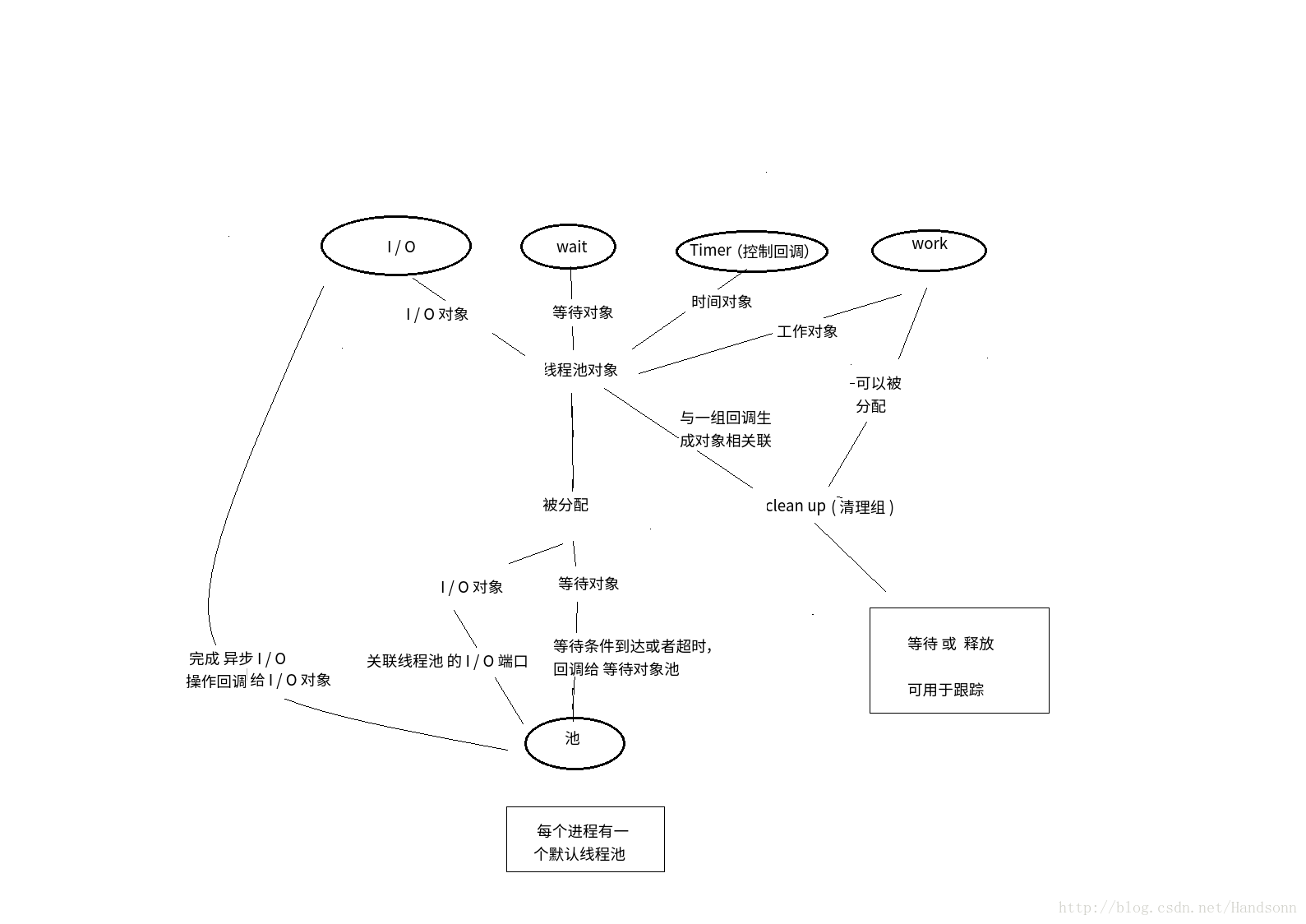
windows 每个进程都可以根据需要创建具有不同特征的多个独立池,并且每个进程还有一个默认的线程池,线程池的默认大小为每个可用处理器有 25 个线程,比如 我的电脑 4核心8硬件线程,默认有 25 × 8 个线程。
当我们提交一个请求后,线程池就会创建一个默认的线程池并让线程池的一个线程来调用回调函数。并不需要我们手动调用创建线程。当线程从入口函数返回时,并不会销毁而是返回到线程池。线程池会不断重复使用各个线程,而不会频繁销毁和新建线程。
API 使用例子可以参考官网 : https://msdn.microsoft.com/en-us/library/windows/desktop/ms686980(v=vs.85).aspx
4、区别
那么上面这两者有什么区别吗?
可以看到,windows 提供了一系列的 api 组合使用,也就是一套机制来实现一个线程池,结果通过回调来进行跟踪,并且 clean up 的 api 可以由我们来使用,所以在一些情况下可以进行回收,而 java 的提供了多个线程池,当然也可以进行线程的配置,包括核心和非核心,而清理工作由线程池进行,所以一些 shutdown 无效的情况下外部并无法手动清除。
5、写一个
我们需要做的操作有
a、入队操作,并且获取返回值
这是一个 lambda 表达式 ( ps:c++ 11 的新特性):
() -> return type {body}
typename result_of
template<typename F, typename... Args>
auto enqueue(F &&f, Args&&... args)
-> future<typename result_of<F(Args...)>::type>;b、中断操作,需要一个标志来中断线程,可以在析构函数中进行处理
ThreadPool::~ThreadPool()
{
...
stop = true;
}c、加锁(阻塞)、唤醒
mutex queue_mutex;
condition_variable condition;总的来说:
在构造函数中做一些初始化处理操作并且不断调用入队,在此期间需要进行加锁,然后便可入队,我们定义自己想要的返回值在入队之后获取并进行打印,最后在析构函数中标志中断为 true。
代码尚未完善,待定。。。

6、使用
如果 c++ IDE 直接使用,咱们可以写到 hpp 文件,然后 include 即可,在 Android 中,可以打包成 so 库
a、打包成 so 库
打包流程,图片较多,记录在下面这篇里面
http://blog.csdn.net/Handsonn/article/details/78106200
b、使用:视频弹幕、断点下载
视频弹幕就是不断同步视频播放和线程池的字符串输出,具体可以参考 :DanmakuFlameMaster
断点下载:正在完善,待续…
7、其它

1)为什么线程池要这么设计
线程池设计中采用了 system design 的多级跳思路,核心线程是固定创建的,非核心线程是当核心线程都满了,临时创建的,类似于内存满了,动态创建 swap(这里的前提是swap和内存读写速度一致)
system design 中 很多多级跳的思路都是借鉴 L1 Cache、L2 Cache、 L3 Cache来设计的
更多一级缓存、二级缓存、三级缓存的可以参考其他文章
2)什么时候使用线程池
线程池的出现:着眼于减少线程池本身带来的开销
我们将线程执行过程分为三个过程:T1、T2、T3:
T1:线程创建时间
T2:线程执行时间,包括线程的同步等时间
T3:线程销毁时间
那么我们可以看出,线程本身的开销所占的比例为
可以看到,设 T2 保持不变,当线程自身开销时间越来越多,即 创建越来越多线程,T1 + T3 会越来越大,分母随之变大,整个开销也会越来越大,也就是说,如果线程创建销毁很频繁的话,cpu 的这笔开销将是不可忽略的。
因此,可以考虑以下情况使用线程池:
1 、多个任务并且执行时间短,不需要立即创建新线程。线程池创建线程是滞后的,不会发现线程不够立即去创建新线程。
2 、任务单一时间长,如下载文件。
还有一些明显的好处:
a、方便管理,例如线程顺序控制(如优先级自定义、延时发送、自定义运作流程算法 等等);
b、一些结果反馈
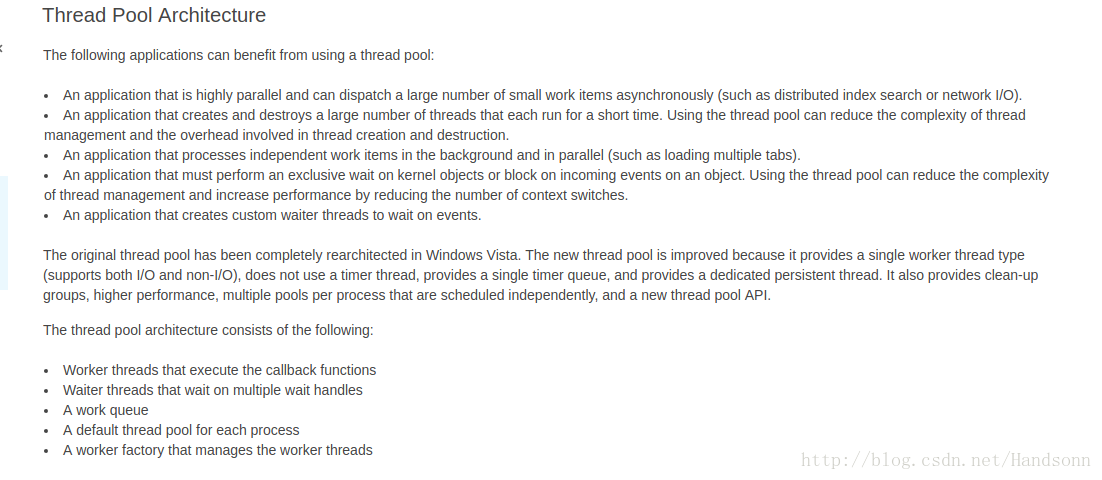
PS:线程池的优点可以参考 msdn 的叙述 ( 或者说什么情况下使用线程池比较有利 ):
3)文章推荐
http://www.cnblogs.com/lidabo/p/3328402.htm
http://www.linuxidc.com/Linux/2014-05/102272.htm
https://baike.baidu.com/item/CPU%E7%BC%93%E5%AD%98
https://msdn.microsoft.com/en-us/library/windows/desktop/ms686760(v=vs.85).aspx
github:
https://github.com/search?l=C%2B%2B&q=c%2B%2B+threadpool&type=Repositories&utf8=%E2%9C%93
关于线程池,还有很多地方并没有很好了解,如ForkJoinPool具体怎么分配任务,等等,可想而知,要写出一个这么优秀的线程池要多666,以上便是个人对线程池比较粗浅的一点理解,如有不对,欢迎指正,Thanks !














 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









