







(c语言)unicode和utf8转换
unicode和utf8转换规则
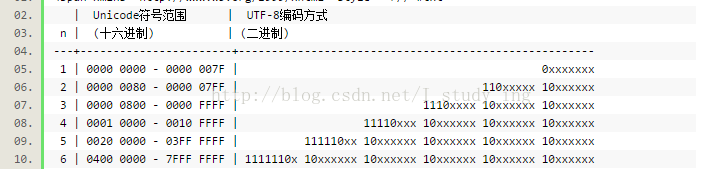
unicode与gb2312有着转换表
所以,只需要unicode和utf8之间进行转换即可
一、所以gb2312转utf8
void Gb2312ToUtf8(const char* input_file, const char *output_file)
{
printf("gb2312->utf8: \n");
//请在此处添加代码完成gb2312到utf8的转换
int byteCount=0;
int i=0;
int j=0;
u16 gbKey=0;
u16 unicodeKey=0;
long len;
FILE *fpIn=fopen(input_file,"rb");
if(fpIn==NULL){
printf("Unable to open the input file!\n");
return;
}
else{
fseek( fpIn, 0L, SEEK_END );
len = ftell( fpIn );
printf( "intput file size: %ldB\n", len );
}
FILE* fpOut=fopen(output_file,"wb");
if(fpOut==NULL)
{
printf("Unable to open the output file!\n");
return;
}
u8 *gb,*temp;
gb=new u8[len*2];
temp=new u8[len*2];
fseek(fpIn,0L,SEEK_SET);
fread(gb,sizeof(u8),len,fpIn);
int count=0;
while(i<len){
memcpy(&gbKey,(gb+i),2);
gbKey=(gbKey >> 8) | (gbKey << 8);
unicodeKey=SearchCodeTable_GB2312(gbKey);
byteCount=0;
//unicodeKey->utf-8
if(unicodeKey==0){
printf("fail:table can not find the key: 0x%x \n",gbKey);
count++;
temp[j]=gb[i];
j++;
}
else {
if(unicodeKey<=0x0000007F){
temp[j]=unicodeKey&0x7F;
byteCount=1;
continue;
}
else if(unicodeKey>=0x00000080&&unicodeKey<0x000007FF){
temp[j+1]=(unicodeKey&0x3F)|0x80;
temp[j]=((unicodeKey>>6)&0x1F)|0xC0;
byteCount=2;
continue;
}
else if(unicodeKey>=0x00000800&&unicodeKey<=0x0000FFFF){
temp[j+2]=(unicodeKey&0x3F)|0x80;
temp[j+1]=((unicodeKey>>6)&0x3F)|0x80;
temp[j]=((unicodeKey>>12)&0x0F)|0xE0;
byteCount=3;
i++;
continue;
}
else if(unicodeKey>=0x00010000&&unicodeKey<=0x0010FFFF){
temp[j+3]=(unicodeKey&0x3F)|0x80;
temp[j+2]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>12)&0x3F)|0x80;
temp[j]=((unicodeKey>>18)&0xF7);
byteCount=4;
continue;
}
else if(unicodeKey>=0x00200000&&unicodeKey<=0x03FFFFFF){
temp[j+4]=(unicodeKey&0x3F)|0x80;
temp[j+3]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+2]=((unicodeKey>>12)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>18)&0x3F)|0x80;
temp[j]=((unicodeKey>>24)&0xF7);
byteCount=5;
continue;
}
else if(unicodeKey>=0x04000000&&unicodeKey<=0x7FFFFFFF){
temp[j+5]=(unicodeKey&0x3F)|0x80;
temp[j+4]=((unicodeKey>>6)&0x3F)|0x80;
temp[j+3]=((unicodeKey>>12)&0x3F)|0x80;
temp[j+2]=((unicodeKey>>18)&0x3F)|0x80;
temp[j+1]=((unicodeKey>>24)&0x3F)|0x80;
temp[j]=((unicodeKey>>30)&0xF7);
byteCount=6;
continue;
}
else{
printf("out of unicodeKey ! \n");
continue;
}
}
j+=byteCount;
i+=1;
}
printf("There are %d wrong!",count);
fwrite(temp, sizeof(u8),j, fpOut);
delete []gb;
delete []temp;
fclose(fpIn);
fclose(fpOut);
}
二、utf8转gb2312
void Utf8ToGb2312(const char* input_file, const char *output_file)
{
printf("utf8->unicode: \n");
int byteCount = 0;
int i = 0;
int j = 0;
u16 unicodeKey = 0;
u16 gbKey = 0;
long len;
FILE* fpIn=fopen(input_file,"rb");
if(fpIn==NULL)
{
printf("Unabile to open the input file!\n");
return;
}
else
{
// 将指针定位到文件末尾
fseek( fpIn, 0L, SEEK_END );
len = ftell( fpIn );
printf( "intput file size: %ldB\n", len );
}
FILE* fpOut=fopen(output_file,"wb");
if(fpOut==NULL)
{
printf("Unabile to open the output file!\n");
return;
}
u8 *utf8,*temp;
utf8=new u8[len];
temp=new u8[len];
fseek( fpIn, 0L, SEEK_SET );
fread(utf8, sizeof(u8),len,fpIn);
i=3;
while (i < len)
{
switch(GetUtf8ByteNumForWord((u8)utf8[i]))
{
case 0:
temp[j] = utf8[i];
byteCount = 1;
break;
case 2:
temp[j] = utf8[i];
temp[j + 1] = utf8[i + 1];
byteCount = 2;
break;
case 3:
//这里就开始进行UTF8->Unicode
temp[j + 1] = ((utf8[i] & 0x0F) << 4) | ((utf8[i + 1] >> 2) & 0x0F);
temp[j] = ((utf8[i + 1] & 0x03) << 6) + (utf8[i + 2] & 0x3F);
//取得Unicode的值
memcpy(&unicodeKey, (temp + j), 2);
// printf("unicode key is: 0x%04X\n", unicodeKey);
//根据这个值查表取得对应的GB2312的值
gbKey = SearchCodeTable(unicodeKey);
// printf("gb2312 key is: 0x%04X\n", gbKey);
if (gbKey != 0)
{
//here change the byte
//不为0表示搜索到,将高低两个字节调换调成我要的形式
gbKey = (gbKey >> 8) | (gbKey << 8);
// printf("after changing, gb2312 key is: 0x%04X\n", gbKey);
memcpy((temp + j), &gbKey, 2);
}
byteCount = 3;
break;
case 4:
byteCount = 4;
break;
case 5:
byteCount = 5;
break;
case 6:
byteCount = 6;
break;
default:
printf("the len is more than 6\n");
break;
}
i += byteCount;
if (byteCount == 1)
{
j++;
}
else
{
j += 2;
}
}
fwrite(temp, sizeof(u8),j, fpOut);
delete []utf8;
delete []temp;
fclose(fpIn);
fclose(fpOut);
}














 5221
5221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









