






作者写给自己的话,错误百出,请自行略过:
这个世界的信息是复杂的,但是人脑处理的信息是稀疏的。我们不可能直接硬处理感官庞杂的输入,需要一个信息提取的过程,这个过程在人脑中称之为抽象。Deep Learning之所以大行其道,就是因为它在一定程度上模拟了人脑处理信息的抽象过程。有研究表明,人眼视网膜上的相邻感光细胞间存在竞争的关系,光照差异强烈的地方感官细胞尤为兴奋,计算机视觉研究者利用这一点提出了很多基于图像梯度信息的算子,如Sobel、Haar、Gabor、Sift等,我们用它们计算好每一点的“中间-外围差”后,通常都会进行下一步--降采样(Downsampling) 。卷积神经网络每一层都有类似的过程,第一步使用各种“随机”的算子对图像进行卷积,第二步降采样的过程叫max-pooling,即提取每个子块的信息,这些信息一层一层的下去直到输出结果,跟真实结果对比,再回过头来用BP调整每一层的算子,最后稳定的神经网络中,每层的算子是最能表示这一层输入信息的算子,这一层的输出是输入的一个稀疏表示。另外信号处理领域的小波变换,也是这样一个逐层差分的过程,如果把差分看出是一阶导数的话,差分的差分就是二阶导数,小波变换就可以看出是按导数展开的泰勒级数(这里很容易联想到傅里叶变换,一个用各种三角函数展开任意信号的过程)。
上面说到的卷积过程,其实就是一个线性变换的过程,在线性代数中解释为将一个向量映射到另一个空间中的过程,稀疏性在这里就是映射过去的坐标有很多0元素,即新坐标的L1范数很小,换句话说我们找到的新空间的基底太优秀了,只用几个基就能表示原来的向量,这个过程有点像PCA,保留特征值大的方向,去除特征值小的方向,达到去噪的目的,去噪也可以说是提取主要信息。这里可能要问,为啥不直接映射到这几个基的子空间,要保存那么多0干嘛?这是因为这个向量可能映射到这几个基,另外一个向量可能映射到其他几个基,如果对原始向量集合不做任何假设的话,你不能确定哪些基是一定是没用的。不过如果你对原始数据稍微做些分析的话,你可以知道这些数据在新空间中只有r维是有用的,你就可以将数据映射到一个随机的、4*r维的空间中,这就是大名鼎鼎的压缩感知了,如果想恢复信号可以用压缩感知提供的方法。
DL的训练过程就是找每一层最优秀基底的过程,本来一层就够慢了,还是多层的,收敛的过程可以预见是多么缓慢。我看下面这些论文的目的,就是想通过研究稀疏性,来找到一种稍微快点的训练DL的方法。
一、Robust Face Recognition via Sparse Representation[1]
论文中用parsimony这个词,本意是“节俭”,这里我就用稀疏性代替。
稀疏性是一个已经用了很久的原则,在选择模型时,选择最少的特征或者只用部分特征作为分类依据(sparse PCA),可以获得很好的结果。对于人脑的研究也有稀疏性的身影,在视觉神经通道中,很多神经元只会对特定的刺激做出反应,比如颜色、纹理、方向、尺度,这些神经元组成的基底的话,向上的信号是稀疏的。在信号处理领域,通过凸优化计算L1-norm,获取过完备基底下的稀疏表示,已经获得越来越多的应用。
这篇文章的重点是研究信号的稀疏表示以及压缩后的保真度(fidelity),并且利用稀疏表示来实现分类。我们使用一组特殊的基底--测试样本本身,如果某个类的测试样本足够充分的话,我们就能通过测试样本的线性组合实现同类图像的表示,这种表示是天然稀疏的,因为只会用到训练集的一小部分,如果是未知图像,则结果不是稀疏解。事实上这种分类方法可以看成是最近邻算法NN和最近域算法NS的拓展,最近邻算法时在训练集中找最近的一个样本,最近域算法是样本附近找线性组合,我们的算法通过不断迭代找到用全局样本的线性组合系数。
具体到Face Recognition这个问题上,我们要解决的是两个问题:1)如何挑选好的特征提取方法,。特征提取是将高维的图片转化为(映射)低位的特征向量的过程,这个在Face Recognition问题里是核心问题,常见的方法有Eigenfaces, Fisherfaces, Laplacianfaces等等,但是压缩感知告诉我们一个道理,精心选择的映射方法并不一定是最好的,在满足信息量的前提下,随机生成的映射方法也是有效的。2)抗遮挡性。真实照片中人脸会有各种各样的遮挡物,我们的算法里很容易解决这个问题,把遮挡物添加到基底中就行了。
具体算法:
每个图像都处理为w*h大小的灰度图像,拉成一列,把一类的图像放在一个矩阵中,比如Ai就是第i类图像,Ai的大小就是m*ni,m=w*h,ni是第i类图像的个数。
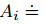

一副图像y表示为Ai的线性组合过程
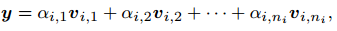
但是我们一开始并不知道y是哪个类的,所以要对所有类别图像求线性组合


上面的线性方程一般是欠定的,x0有无限多的解,我们要找的是最稀疏的那个解,理论上应该是用x的L0-norm,但是这样的问题是NP-hard。还好有压缩感知的几位大牛[2-4],我们知道L1-norm也足够好。
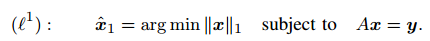
上面这个是多项式时间内可以解的。(陆吾生教授2010年的视频,讲这个最优化问题的解法,非常通俗易懂,他使用的方法是这个人的[5,6])
论文中给了一个简单的解释:
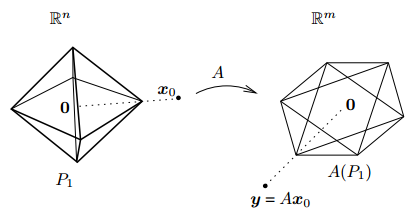
P1是一个多面体,x0是某个面上的一个点,多面体上所有点通过A线性变换到新空间,仍然是一个多面体,并且当P1放大缩小时,A(P1)也按同比例放大缩小,因此可以控制P1逐渐放大,直到A(P1)第一次接触到y,此时的x即是一个L1-norm下的稀疏解。
有了稀疏解x,判断x属于哪个类就非常简单了,论文中的做法是定义一个跟类别有关的函数
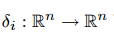
这个函数将x中不属于i类部分的系数全置为0,再求转化后的y=Ax,如果y变化很小,说明这个x是属于类i的,即

算法如下:

实验过程:
将Extended Yale B这个人脸识别数据集的一半作为训练数据,每张图片都降采样到12*10大小,拉成一列放在A中。测试时也同样的方法降采样,用上面的算法获得类标。

上图是测试第一个类中某张人脸的过程,可以看出绝大多数系数是接近于0的,也就是说此时系数是稀疏的。与之相对应的是分类时得到的余量,只有类1是比较小,即此图片是属于类1的。
细心的人可能会注意到,我们前面一直讨论的是将原图片放在A中作为训练基底,为什么这里变成了降采样后的图片,原因有两点,一是原图太大,计算量实在惊人,二是根据压缩感知,我们事先可以对数据进行线性变换,而不会损失信息,如果想恢复信息,可以通过线性变换矩阵后的基底矩阵求解稀疏系数,从而恢复原始信息。需要注意的是,这里的“不会损失信息”是相对的,跟基底矩阵有关,比如原来是y=Ax,对y做一个线性变换R,y'=Ry=RAx,此时不损失信息意味着y在A中有多少信息,y‘在RA中就还是多少。
拿实验中的线性变换举例,假设马赛克是求分块区域平均值的方法得到,R的第一行应该是[1100000000000000110000000000000000000000000000000000000000000000...]/4这样的形式,下面119行依次把相应的区域设为1,即得到一个d*m的矩阵,m是图像的大小(拉成一列),d是图像变换后的大小(这里是120),A是m*n的矩阵,RA的意思就是将A基底中每一列(亦即每张训练图片)做一个线性变换,将变换后的图片作为新的基底,压缩感知保证这个新基底的表现跟原始基底一样好,只要满足两个条件,y在A中的稀疏系数的非零元素个数为t时,d满足
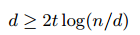
以及R跟A应该不相关。注意这里只要求R跟A不相关,并与要求R一定是人为精心设计的变换。

图a是原图,图b从左往右依次是Eigenfaces,Laplacianfaces, downsampled (12 10 pixel) image, and random projection。random projection的每个元素都是高斯分布N(0,1),实验表明这几个线性变换的方法的分类效果几乎都是一样。
接下来讲遮挡问题:按照上面的思路,处理遮挡问题只要把有遮挡的人脸也放进A就解决了,但是其实仔细想想这是不对,因为遮挡可能出现在图像的任意部分,而且以任意形状出现,那么有没有一种基底能描述这样复杂的遮挡问题呢?答案简单到令人发指,只要在A后面添加一个单位矩阵就行了。


e0是图像遮挡部分,我们假设只占图像的一小部分,因此其在单位矩阵构成基底下可以有稀疏解,把它跟x放在一起还是稀疏解,因此只要对上面的算法进行非常小的改动就行了。当然,这里I也可以是其他基底,只要你能保证遮挡部分在这个基底下有稀疏解就行了。
改动后算法求y=Bw的稀疏解,并且余量计算方法变成下面的形式:
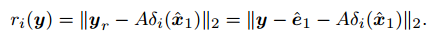
[1] Wright, John, et al. "Robust face recognition via sparse representation."Pattern Analysis and Machine Intelligence, IEEE Transactions on 31.2 (2009): 210-227.
[2] D. Donoho, “For most large underdetermined systems of linear equations the minimal l1-norm solution is also the sparsest solution,” Comm. on Pure and Applied Math, vol. 59, no. 6, pp. 797–829, 2006.
[3] E. Candes, J. Romberg, and T. Tao, “Stable signal recovery from incomplete and inaccurate measurements,” Comm. on Pure and Applied Math, vol. 59, no. 8, pp. 1207–1223, 2006.
[4] E. Candes and T. Tao, “Near-optimal signal recovery from random projections: Universal encoding strategies?” IEEE Trans. Information Theory, vol. 52, no. 12, pp. 5406–5425, 2006.
[5] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM J. Imaging Sciences, vol. 2, no. 1, pp. 183-202, 2009.
[6] A. Beck and M. Teboulle, “Fast gradient-based algorithms for constrained total variation denoising and deblurring problems,” IEEE Trans. Image Processing, vol. 18, no. 11, pp. 2419-2434, Nov. 2009.














 6068
6068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









