







一:背景
什么是字典树?
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
假如给出一些单词,and,as,at,cn,com,构建下面的字典树:
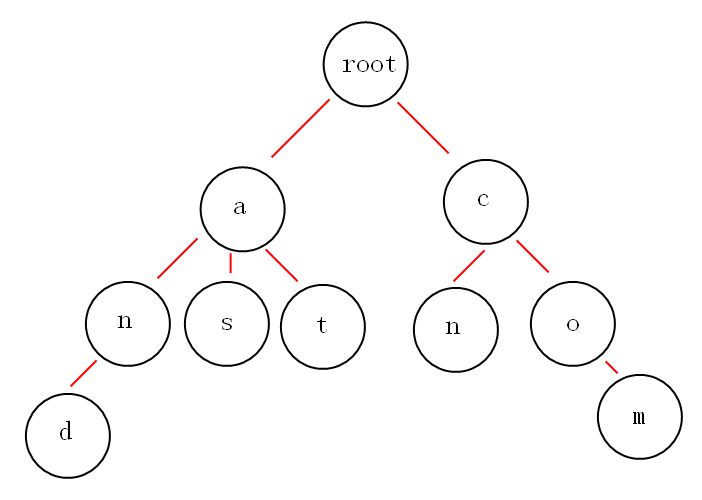
从上图可以发现:
它有3个基本性质:
1.根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2.从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3.每个节点的所有子节点包含的字符都不相同。
你可能会想,这有什么用?
第一:词频统计
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,可以说这是秒杀的效果。
二:完整代码
#define _CRT_SECURE_NO_DEPRECATE
#define _CRT_SECURE_CPP_OVERLOAD_STANDARD_NAMES 1
#include<iostream>
#define MAX 26//假设字符只出现 abc..k..xyz 26个小写英文字母
using namespace std;
struct Node
{
int num;
Node * next[MAX];
Node()
{
num = 0;
for (int i = 0; i < MAX; i++)
next[i] = nullptr;
}
};
class Trie
{
public:
Node *root;
Trie() { root = new Node; }
void Add(Node *node, const char *ch);
int Find(const char *ch);
void Delete(Node *node, const char *ch);
};
void Trie::Add(Node *node, const char *ch)
{
int len = strlen(ch);
if (len == 0)
return;
int order = *ch - 'a';//得到字符的位置
if (node->next[order] == nullptr)
node->next[order] = new Node;
len = strlen(ch + 1);
if (len == 0)//说明是一个单词的结尾,需要将该单词出现的次数加一
{
node->next[order]->num++;
return;//下面的递归可以结束了
}
Add(node->next[order], ch + 1);//递归下去
}
int Trie::Find(const char *ch)
{
Node *p = root;
while (*ch != '\0')
{
int order = *ch - 'a';
if (p->next[order] == nullptr)
return 0;
else
{
ch++;
p = p->next[order];
}
}
return p->num;
}
void Trie::Delete(Node *node, const char *ch)
{
int len = strlen(ch);
if (len == 0)
return;
int order = *ch - 'a';
if (node->next[order] == nullptr)
return;
len = strlen(ch + 1);
if (len == 0 && node->next[order]->num != 0)//找到该单词并且该单词出现次数大于0
{
node->next[order]->num--;
return;
}
Delete(node->next[order], ch + 1);
}
int main()
{
Trie tree;
tree.Add(tree.root, "strawberry");
tree.Add(tree.root, "grandfather");
tree.Add(tree.root, "policeman");
tree.Add(tree.root, "breakfast");
tree.Add(tree.root, "mutton");
tree.Add(tree.root, "bus");
tree.Add(tree.root, "bus");
tree.Add(tree.root, "computer");
int k = tree.Find("bus");
cout << k << endl;//2
tree.Delete(tree.root, "bus");
cout << tree.Find("bus") << endl;//1
return 0;
}三:总结
细心的朋友会发现,上面的代码有缺陷,拿Delete操作来说吧,if (len == 0 && node->next[order]->num != 0),这句代码其实是有问题的,因为我没有考虑node->next[order]->num==1的情况,如果等于1,现在执行删除,自减1,num就是0了,也就是这个单词从来没出现,那么表示这个 单词这一条路径都要delete(如果这条路径上不存在其他的单词),并且root处的指针需要reset。
好了,虽然代码是有缺陷的,但是只要把实现搞懂,该如何进行完善那就是看个人的需求了。
返回目录---->数据结构与算法目录
另外推荐读者下面这篇博客: http://blog.csdn.net/v_july_v/article/details/6897097,JULY大牛
图片资源和代码参考:http://www.cnblogs.com/huangxincheng/archive/2012/11/25/2788268.html















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









