







 本文介绍了两种文件拷贝的方法,并重点实现了一种高效且节省内存的边读边写拷贝方式。通过具体代码示例展示了如何使用Java进行文件拷贝,并优化了读写过程。
本文介绍了两种文件拷贝的方法,并重点实现了一种高效且节省内存的边读边写拷贝方式。通过具体代码示例展示了如何使用Java进行文件拷贝,并优化了读写过程。
如果要想实现文件的拷贝操作,有以下两种方法:
方法1、将所有文件的内容一次性读取到程序之中,然后一次性输出;这样的话就需要开启一个跟文件一样大小的数据用于临时保存这些数据,但是当文件过大的时候呢?程序是不是会崩掉呢?欢迎大家踊跃尝试^@^。
方法2、采用边读边写的操作,这样一来效率也提高了,也不会占用过多的内存空间。
所以,我们采用第二种方法,边读边写。
package signal.IO;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyFile {
/**
* 定义一个方法来实现拷贝文件的功能
*
* @param src 源文件路径
* @param target 目标文件路径
* @throws IOException
*/
public static void CopyFile(File src, File target) throws IOException{
/**
* 验证源文件是否存在
*/
if(!src.exists()){
System.err.println("There is no such a file !!!");
System.exit(1);
}
/**
* 验证目标路径是否存在,不存在的话创建父路径
*/
if(!target.getParentFile().exists()){
target.getParentFile().mkdirs();
}
int temp = 0; //用作标示是否读取到源文件最后
InputStream input = new FileInputStream(src);
OutputStream output = new FileOutputStream(target);
while((temp = input.read()) != -1){
output.write(temp);
}
input.close();
output.close();
}
public static void main(String[] args) {
String in = "C:\\Users\\Administrator\\Desktop\\tmp.txt";//源文件路径
String out = "C:\\Users\\Administrator\\Desktop\\tmp_copy.txt";//目标路径(此时还可以重命名)
File src = new File(in);
File target = new File(out);
try {
CopyFile(src, target);
System.out.println("Copy Successfully !");
} catch (IOException e) {
System.err.println("ERROR: Something wrong while copying !");
e.printStackTrace();
}
}
}
正如代码中写的那样,我们是一边读取一边写入。使用到的 read() 方法源码如下:
...
/**
* Reads the next byte of data from the input stream. The value byte is
* returned as an <code>int</code> in the range <code>0</code> to
* <code>255</code>. If no byte is available because the end of the stream
* has been reached, the value <code>-1</code> is returned. This method
* blocks until input data is available, the end of the stream is detected,
* or an exception is thrown.
*
* <p> A subclass must provide an implementation of this method.
*
* @return the next byte of data, or <code>-1</code> if the end of the
* stream is reached.
* @exception IOException if an I/O error occurs.
*/
public abstract int read() throws IOException;
...里面写到,”@return the next byte of data, or -1 if the end of the stream is reached.”,read() 方法的返回值为 “-1” 时表示文件读取完毕。这样一来就不难解释:
while((temp = input.read()) != -1){
output.write(temp);
}有了这个基础,我们就可以再稍微改进一下,不要一次一个字节一个字节的读取和写入了。版本2如下:
package signal.IO;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class CopyFileVersion2 {
/**
* 定义一个方法来实现拷贝文件的功能
*
* @param src 源文件路径
* @param target 目标文件路径
* @throws IOException
*/
public static void CopyFile(File src, File target) throws IOException{
/**
* 验证源文件是否存在
*/
if(!src.exists()){
System.err.println("There is no such a file !!!");
System.exit(1);
}
/**
* 验证目标路径是否存在,不存在的话创建父路径
*/
if(!target.getParentFile().exists()){
target.getParentFile().mkdirs();
}
int temp = 0;
byte data[] = new byte[1024]; //每次读取1024字节
InputStream input = new FileInputStream(src);
OutputStream output = new FileOutputStream(target);
while((temp = input.read(data)) != -1){
output.write(data,0,temp);
}
input.close();
output.close();
}
public static void main(String[] args) {
String in = "C:\\Users\\Administrator\\Desktop\\tmp.txt";
String out = "C:\\Users\\Administrator\\Desktop\\tmp_copy.txt";
File src = new File(in);
File target = new File(out);
try {
long start = System.currentTimeMillis();
CopyFile(src, target);
long end = System.currentTimeMillis();
System.out.println("Copy Successfully! \nAnd it costs us " + (end - start) + " milliseconds.");
} catch (IOException e) {
System.err.println("ERROR: Something wrong while copying !");
e.printStackTrace();
}
}
}
很明显可以看出不同,这里我们定义了一个1024字节的数组,这个数组的大小由自己来决定,其实这就是与第一种方法的结合。
这里我们用到 read() 和 write() 两个方法也跟之前不同了,是带参数的。
read( byte b[] ) 源码如下:
/**
* Reads some number of bytes from the input stream and stores them into
* the buffer array <code>b</code>. The number of bytes actually read is
* returned as an integer. This method blocks until input data is
* available, end of file is detected, or an exception is thrown.
*
* <p> If the length of <code>b</code> is zero, then no bytes are read and
* <code>0</code> is returned; otherwise, there is an attempt to read at
* least one byte. If no byte is available because the stream is at the
* end of the file, the value <code>-1</code> is returned; otherwise, at
* least one byte is read and stored into <code>b</code>.
*
* <p> The first byte read is stored into element <code>b[0]</code>, the
* next one into <code>b[1]</code>, and so on. The number of bytes read is,
* at most, equal to the length of <code>b</code>. Let <i>k</i> be the
* number of bytes actually read; these bytes will be stored in elements
* <code>b[0]</code> through <code>b[</code><i>k</i><code>-1]</code>,
* leaving elements <code>b[</code><i>k</i><code>]</code> through
* <code>b[b.length-1]</code> unaffected.
*
* <p> The <code>read(b)</code> method for class <code>InputStream</code>
* has the same effect as: <pre><code> read(b, 0, b.length) </code></pre>
*
* @param b the buffer into which the data is read.
* @return the total number of bytes read into the buffer, or
* <code>-1</code> if there is no more data because the end of
* the stream has been reached.
* @exception IOException If the first byte cannot be read for any reason
* other than the end of the file, if the input stream has been closed, or
* if some other I/O error occurs.
* @exception NullPointerException if <code>b</code> is <code>null</code>.
* @see java.io.InputStream#read(byte[], int, int)
*/
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}源码已经很清楚的写出来了,”@param b the buffer into which the data is read.”,参数是要读取到内存中的字节数组,如果再跟下去,我们发现,其实这个方法是调用了 read( byte b[] , int off , int len )
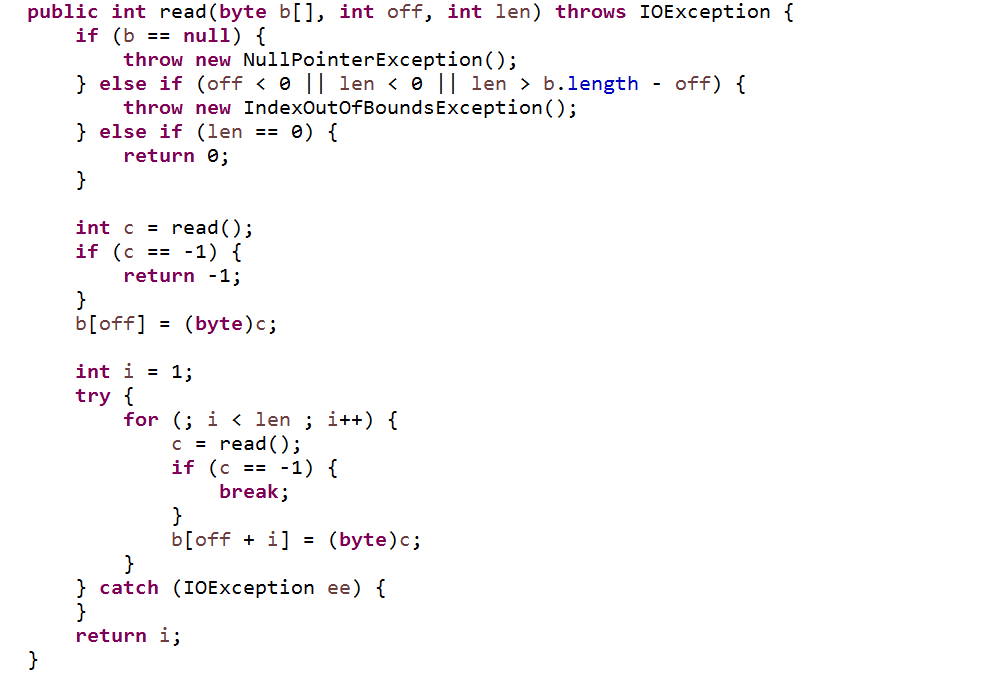
其实最后,还是使用的 read() 方法,我们只不过是调用了已经封装好的一些方法。
对于 write( byte b[], int off, int len )方法,源码如下:
/**
* Writes <code>len</code> bytes from the specified byte array
* starting at offset <code>off</code> to this output stream.
* The general contract for <code>write(b, off, len)</code> is that
* some of the bytes in the array <code>b</code> are written to the
* output stream in order; element <code>b[off]</code> is the first
* byte written and <code>b[off+len-1]</code> is the last byte written
* by this operation.
* <p>
* The <code>write</code> method of <code>OutputStream</code> calls
* the write method of one argument on each of the bytes to be
* written out. Subclasses are encouraged to override this method and
* provide a more efficient implementation.
* <p>
* If <code>b</code> is <code>null</code>, a
* <code>NullPointerException</code> is thrown.
* <p>
* If <code>off</code> is negative, or <code>len</code> is negative, or
* <code>off+len</code> is greater than the length of the array
* <code>b</code>, then an <tt>IndexOutOfBoundsException</tt> is thrown.
*
* @param b the data.
* @param off the start offset in the data.
* @param len the number of bytes to write.
* @exception IOException if an I/O error occurs. In particular,
* an <code>IOException</code> is thrown if the output
* stream is closed.
*/
public void write(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}同样的,这个方法也是对 write( int b ) 方法的封装。
另外我加了可以测试耗费时间的一个小功能,原理很简单,就是使用 currentTimeMillis() 方法,源码如下:
/**
* Returns the current time in milliseconds. Note that
* while the unit of time of the return value is a millisecond,
* the granularity of the value depends on the underlying
* operating system and may be larger. For example, many
* operating systems measure time in units of tens of
* milliseconds.
*
* <p> See the description of the class <code>Date</code> for
* a discussion of slight discrepancies that may arise between
* "computer time" and coordinated universal time (UTC).
*
* @return the difference, measured in milliseconds, between
* the current time and midnight, January 1, 1970 UTC.
* @see java.util.Date
*/
public static native long currentTimeMillis();可以看到,这个方法的返回值是当前时间到1970年1月1日的间隔,单位是毫秒。
到此我们简单的文件拷贝功能就实现了,其实就是对于IO的一个实际应用。大家在学习的过程中可以追进源码去看,很多什么参数呀返回值什么的介绍的都很详细。用了这么长时间的Eclipse,是java程序员的真爱,代码提示的功能很给力,就怕有一天离开了Eclipse连”Hello World”都写不出来了^_^ 。相比大家在学习IO的时候,要么是看视频,要么是学院派,老师肯定会跟你说IO有多重要多重要,一定要学好,所以大家在学习的过程中不妨写几个小功能,以便于对IO更好的掌握。这次我只是一时兴起,不代表这就是最终的实现,大家可以结合自己学到东西,随意改我的代码,但是别忘了自己的目的。

















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









