







环境:scala 版本2.11.8,spark 版本2.0.1,使用 Intellij IDEA 来开发。
准备工作:
创建maven项目
可以从官网上找到我们建项目时使用的 archetype
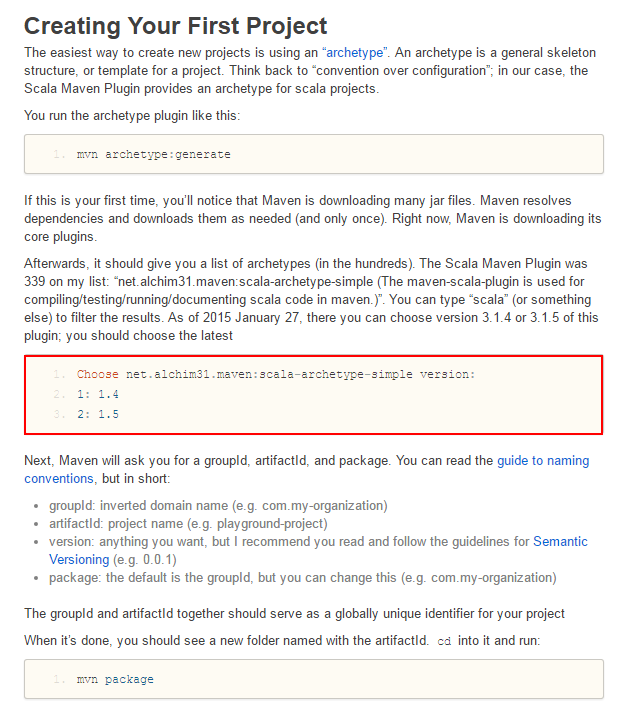
至于具体怎么创建项目,请参考一个朋友的文章Intellij IDEA 创建 spark/scala 项目
这个是前一段时间发现的一个朋友,强烈推荐大家去转转。
好了,这样一来就默认大家创建好了项目…
1 第一个例子
1.1 创建 SparkSession
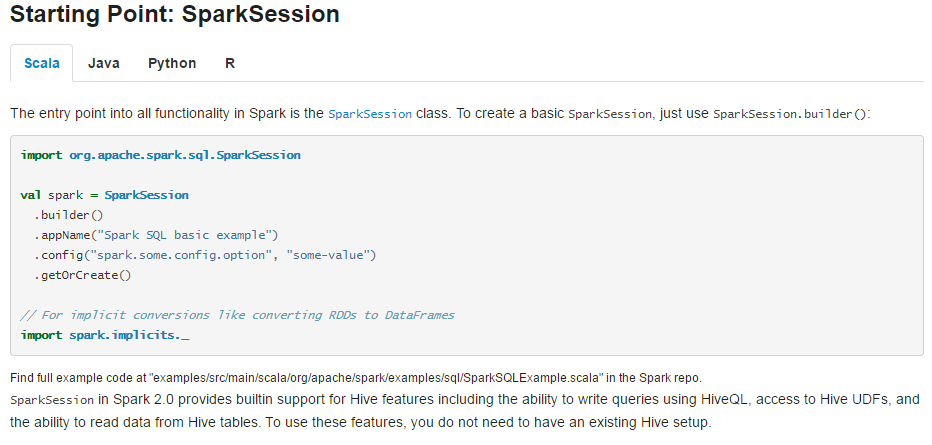
官方文档如是说。
那么我们可以按照这个例子来写。
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("sql test")
.master("local")
.getOrCreate()
import spark.implicits._ 1.2 创建 DataFrames
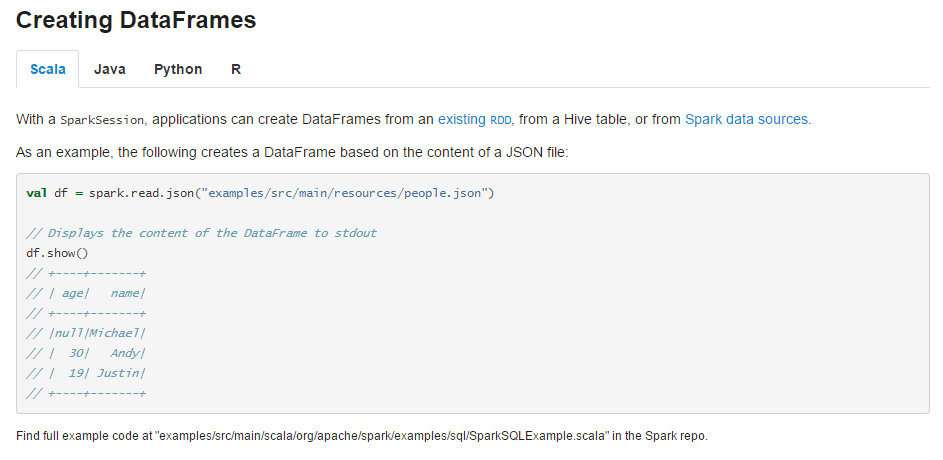
//创建dataframe
val df = spark.read.json("C:\\Users\\Administrator\\Desktop\\people.json")
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+就像官网写的那样,我们可以调用 show() 方法来打印出 df 的数据。这里我是把官网上的示例给放到了指定的目录。当然,我们也可以自己创建一个 json 文件,格式如下:
{"name":"Signal"}
{"name":"May j Lee","age":20}
{"name":"Jay Chou","age":36}
{"name":"Jack Chen","age":60}
当然,还有一些其他操作,我就不一一敲了,官网上给出的示例非常详细。用到类似的了就去官网上查…
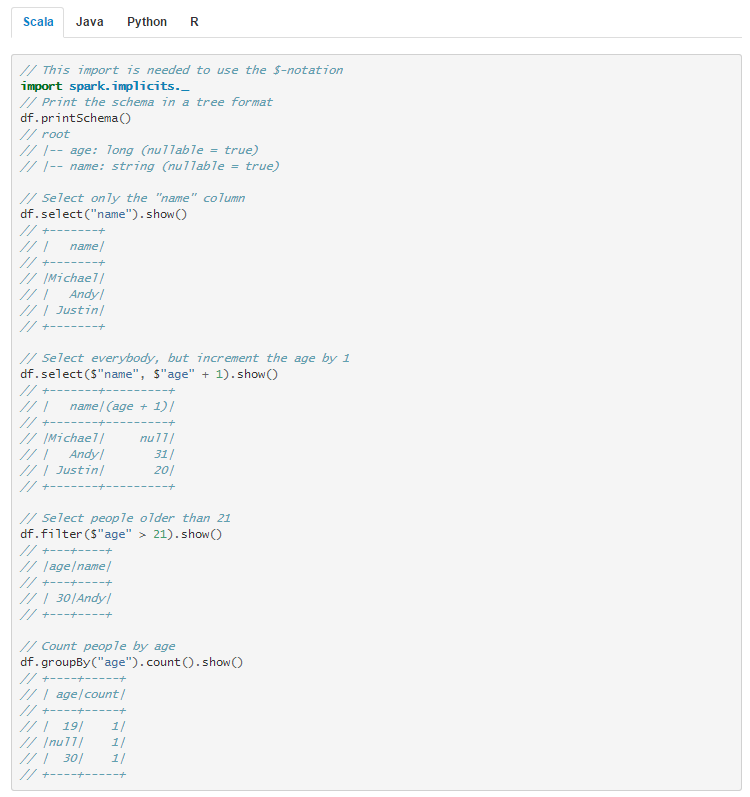
我们还可以使用 SQL 语句来操作:
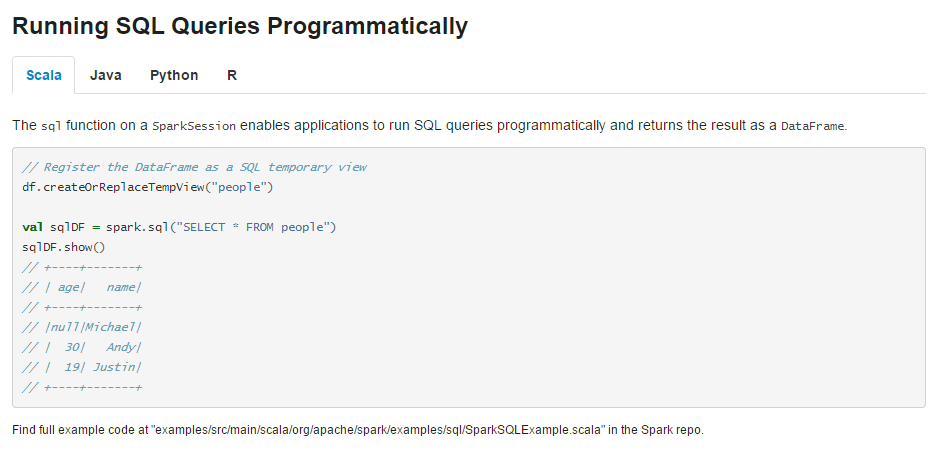
不过在我们使用 SQL 进行操作之前,需要使用 createOrReplaceTempView() 方法,熟悉 SQL 语句人肯定都知道”视图(view)“,接下来这个就是我们要操作的对象。
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("select * from people")
sqlDF.show()2 第二个例子
在第一个例子中,我们是根据一个 json 文件进行了一系列的操作,接下来我们是不是可以创建一个呢?
这里我们需要使用到的对象是 DataSets
2.1 创建 DataSets
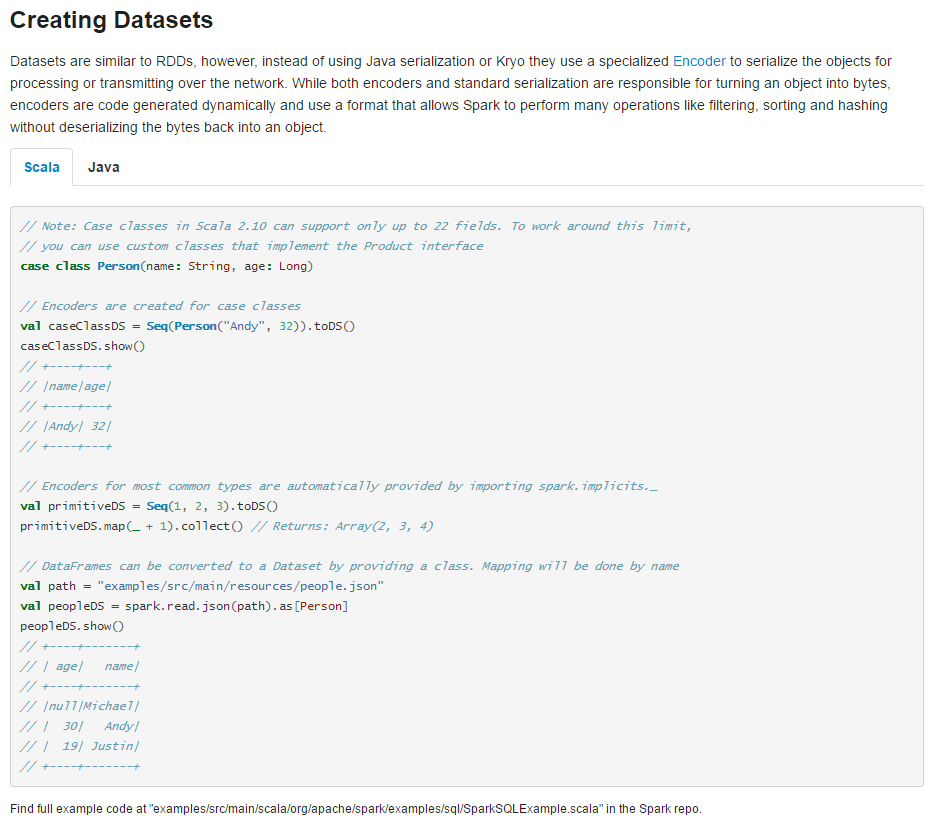
我们还是参照官网的例子来写:
def createDataSetsTest(spark:SparkSession): Unit ={
import spar 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









