







一、SIMD
SIMD单指令流多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX、SSE、AVX以及AMD的3D Now!技术,本文只介绍Intel的SIMD技术。
二 、MMX
MMX是由英特尔开发的一种SIMD多媒体指令集,共有57条指令。它于1996年集成在英特尔奔腾(Pentium) MMX处理器上,以提高其多媒体数据的处理能力。
其优点是增加了处理器关于多媒体方面的处理能力,缺点是占用浮点数寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名)以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。后来英特尔在此基础上发展出SSE指令集。现在新开发的程序不再仅使用MMX来优化软件执行效能,而是改使用如SSE、AVX等更容易优化效能的新一代多媒体指令集,不过目前的处理器仍可以执行针对MMX优化的较早期软件。
MMX寄存器,称作MM0到MM7,实际上就是处理器内部80比特字长的浮点寄存器栈st(0)到st(7)的尾数部分(64比特长)的复用。由于浮点栈寄存器的高16位未被MMX技术使用,因此这16位都置为1,因此从栈寄存器的角度看,其浮点值为NaN或Infinities,这可用于区分寄存器是处于浮点栈状态还是MMX状态.作为MMX寄存器都是直接访问。利用了装配数据类型(packeddata type)的概念,每个MMX寄存器的64比特字长可以看作是2个32位整数、或者4个16位整数、或者8个8位整数,从而可以执行整数SIMD运算。这对于1990年代中期的2D、3D计算的加速还是很有意义的,因为当时的计算机的图形处理器(GPU)还很不发达。但现在MMX整数SIMD运算对于图形运算来说是多余的技术了。不过MMX的饱和算术运算(saturationarithmeticoperations)对于一些数字信号处理应用还是有用的。
三、 SSE
继 MMX技术之后,Intel又于1999年在Pentium-III处理器上推出SSE技术,引入了新的128比特宽的寄存器集 (register file),称作XMM0到XMM7。这些XMM寄存器用于4个单精度浮点数运算的SIMD执行,并可以与MMX整数运算或x87浮点运算混合执行。 2001年在Pentium 4上引入了SSE2技术,进一步扩展了指令集,使得XMM寄存器上可以执行8/16/32位宽的整数SIMD运算或双精度浮点数的SIMD运算。这使得 SIMD技术基本完善。
SSE(StreamingSIMD Extensions)是英特尔在其计算机芯片Pentium III中引入的指令集,是继MMX的扩充指令集。SSE指令集提供了 70条新指令。
SSE寄存器:
SSE 加入新的 8个 28 位缓存器(XMM0~XMM7)。除此之外还有一个新的 32 位的控制/状态缓存器(MXCSR)。不过只能在 64位的模式下才能使用额外8个缓存器。
每个缓存器可以容纳 4个32位单精度浮点数,或是2个 64位双精度浮点数,或是 4个32位整数,或是 8个16位短整数,或是 16个字符。整数运算能够使用正负号运算。而整数 SIMD运算可能仍然要与 8个64位MMX缓存器一起执行。
因为操作系统必须要在进程切换的时候保护这些128位的缓存器状态,除非操作系统去启动这些缓存器,否则默认值是不会去启用的。这表示操作系统必须要知道如何使用FXSAVE与FXRSTOR 指令才能储存x87 与SSE缓存器的状态。而在当时IA-32的主流操作系统很快的都加入了此功能。
由于 SSE加入了浮点支持,SSE就比MMX更加常用。而SSE2加入了整数运算支持之后让SSE更加的有弹性,当MMX变成是多余的指令集,SSE指令集甚至可以与MMX并行运作,在某些时候可以提供额外的性能增进。
第一个支持 SSE的 CPU是 Pentium III,在FPU与SSE之间共享执行支持。当编译出来的软件能够交叉的同时以FPU与SSE运作,PentiumIII并无法在同一个周期中同时执行FPU与SSE。这个限制降低了指令管线的有效性,不过XMM缓存器能够让SIMD与纯量浮点运算混合执行,而不会因为切换MMX/浮点模式而产生性能的折损。
数据类型
Intrinsic使用的数据类型和其寄存器是对应,有
· 64位 MMX指令集使用
· 128位 SSE指令集使用
· 256位 AVX指令集使用
甚至AVX-512指令集有512位的寄存器,那么相对应Intrinsic的数据也就有512位。
具体的数据类型及其说明如下:
1. **__m64** 64位对应的数据类型,该类型仅能供MMX指令集使用。由于MMX指令集也能使用SSE指令集的128位寄存器,故该数据类型使用的情况较少。
2. **__m128 / __m128i / __m128d** 这三种数据类型都是128位的数据类型。由于SSE指令集即能操作整型,又能操作浮点型(单精度和双精度),这三种数据类型根据所带后缀的不同代表不同类型的操作数。__m128是单精度浮点数,__m128i是整型,__m128d是双精度浮点数。
3. 256和512的数据类型和128位的类似,只是存放的个数不同,这里不再赘述。
知道了各种数据类型的长度以及其代码的意义,那么它的表现形式到底是怎么样的呢?看下图

__m128i yy;
yy是__m128i型,从上图可以看出__m128i是一个联合体(union),根据不同成员包含不同的数据类型。看其具体的成员包含了8位、16位、32位和64位的有符号/无符号整数(这里__m128i是整型,故只有整型的成员,浮点数的使用__m128)。而每个成员都是一个数组,数组中填充着相应的数据,并且根据数据长度的不同数组的长度也不同(数组长度 = 128 / 每个数据的长度(位))。在使用的时候一定要特别的注意要操作数据的类型,也就是数据的长度,例如上图同一个变量yy当作4个32位有符号整型使用时其数据是:0,0,1024,1024;但是当做64位有符号整型时其数据为:0,4398046512128,大大的不同
Intrinsic 函数的命名
Intrinsic函数的命名也是有一定的规律的,一个Intrinsic通常由3部分构成,这个三个部分的具体含义如下:
1. 第一部分为前缀_mm,表示是SSE指令集对应的Intrinsic函数。_mm256或_mm512是AVX,AVX-512指令集的Intrinsic函数前缀,这里只讨论SSE故略去不作说明。
2. 第二部分为对应的指令的操作,如_add,_mul,_load等,有些操作可能会有修饰符,如loadu将未16位对齐的操作数加载到寄存器中。
3. 第三部分为操作的对象名及数据类型,_ps packed操作所有的单精度浮点数;_pd packed操作所有的双精度浮点数;_pixx(xx为长度,可以是8,16,32,64)packed操作所有的xx位有符号整数,使用的寄存器长度为64位;_epixx(xx为长度)packed操作所有的xx位的有符号整数,使用的寄存器长度为128位;_epuxx packed操作所有的xx位的无符号整数;_ss操作第一个单精度浮点数。....
将这三部分组合到以其就是一个完整的Intrinsic函数,如_mm_mul_epi32对参数中所有的32位有符号整数进行乘法运算。
SSE指令集对分支处理能力非常的差,而且从128位的数据中提取某些元素数据的代价又非常的大,因此不适合有复杂逻辑的运算。
后续版本:
SSE2是 Intel在Pentium 4处理器的最初版本中引入的。SSE2指令集添加了对64位双精度浮点数的支持,以及对整型数据的支持,也就是说这个指令集中所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。这个指令集还增加了对CPU快取的控制指令。Intel后来在其Intel 64架构中也增加了对x86-64的支持。
SSE3是 Intel在Pentium 4处理器的 Prescott核心中引入的第三代SIMD指令集。这个指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持
SSSE3是Intel针对SSE3指令集的一次额外扩充,最早内建于Core2 Duo处理器中。
SSE4是Intel在Penryn核心的Core 2 Duo与Core2 Solo处理器时,新增的47条新多媒体指令集,并且现在更新至SSE4.2
AVX是Sandy Bridge和Larrabee架构新指令集,Intel的微架构也进入了全速发展的时期,在2010年4月结束的IDF峰会上Intel公司就发布了2010年的RoadMap。2011年1月Intel发布全新的处理器微架构Sandy Bridge,其中全新增加的指令集也将带来CPU性能的提
升。AVX(AdvancedVector Extensions)是Intel的SSE延伸架构,如IA16至IA32般的把缓存器XMM 128bit提升至YMM 256bit,以增加一倍的运算效率。此架构支持了三运算指令(3-OperandInstructions),减少在编码上需要先复制才能运算的动作。在微码部分使用了LES LDS这两少用的指令作为延伸指令Prefix。
SSE sample vec_add.cpp
#include<stdio.h>
#include<stdlib.h>
#include<math.h>
#include<time.h>
#include<sys/time.h>
#include<stdbool.h>
#include<xmintrin.h>//SSE指令需要的头文件
#define N 4*100000
float op1[N] __attribute__((aligned(32)));//内存对齐
float op2[N] __attribute__((aligned(32)));
float result1[N] __attribute__((aligned(32)));
float result2[N] __attribute__((aligned(32)));
void init()
{
for(int i = 0;i < N; i++){
op1[i] = (float)rand()/(float)RAND_MAX;
op2[i] = (float)rand()/(float)RAND_MAX;
}
}
void checkResult(int debug)
{
bool isSame = true;
for(int i = 0;i < N; i++)
{
if (debug){
printf("%lf %lf\n", result1[i], result2[i]);
}
else{
if (fabs(result1[i] - result2[i]) > 0.000001){
isSame = false;
break;
}
}
}
if (!debug) {
if (isSame)
printf("Result is Same\n");
else
printf("Result is not same\n");
}
}
void add1()
{
for(int i = 0; i < N;i++)
result1[i] = op1[i] + op2[i];
}
void add2()
{
__m128 a;
__m128 b;
__m128 c;
for(int i = 0; i < N;i = i + 4)
{
//从op1+i执向的内存中,加载4个float数到寄存器
a = _mm_load_ps(op1 + i);
b = _mm_load_ps(op2 + i);
c = _mm_add_ps(a, b);//并行计算加4个float数据
//将寄存器中的 4个float数存储到c指向内存中
_mm_store_ps(result2 + i, c);
}
}
int main(int argc, char* argv[])
{
init();
srand((unsigned int)time(NULL));
printf("Add a vector:\n");
struct timeval start;
struct timeval end;
gettimeofday(&start,NULL);
add1();
gettimeofday(&end,NULL);
float time_use=1000.0*(float)(end.tv_sec-start.tv_sec)+(float)(end.tv_usec-start.tv_usec)/1000.0;
printf("add a vector Time use =%f(ms)\n",time_use);
printf("\n");
printf("Add a vector with SSE instructions:\n");
gettimeofday(&start,NULL);
add2();
gettimeofday(&end,NULL);
time_use=1000.0*(float)(end.tv_sec-start.tv_sec)+(float)(end.tv_usec-start.tv_usec)/1000.0;
printf("add a vector with sse Time use =%f(ms)\n",time_use);
printf("\n");
checkResult(0);
//test();
return 0;
}
编译:
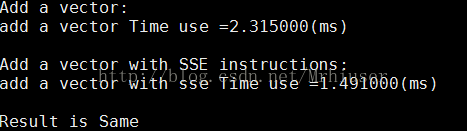
g++ vec_add.cpp -msse -o vec_add执行结果:
四、自动向量化
使用SSE、AVX的指令可以提高CPU的计算性能,但是学习和使用SIMD指令都需要成本。自动向量话只需要在编译时加入自动向量话指令,当然性能和使用SIMD指令要稍差些。
自动向量化编译选项:(gcc编译器)
-O3(使用O3默认打开自动向量化)
-ftree-vectorize(打开自动向量化)
-ftree-vectorizer-verbose=n(编译时输出向量化信息,n是整数,3和9常用)
参考:
1、https://software.intel.com/sites/landingpage/IntrinsicsGuide/#
2、http://blog.csdn.net/conowen/article/details/7255920
3、https://gcc.gnu.org/projects/tree-ssa/vectorization.html#using














 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









