






点击上方“程序员大咖”,选择“置顶公众号”
关键时刻,第一时间送达!


写在最前面的话:
大家好,我是Victor 278,由于本人是做前端的,Python学来作知识扩充的,看到非常多的小伙伴高呼着想从0开始学爬虫,这里开始写定向爬虫从0开始,献给想学爬虫的零基础新人们,欢迎各位大佬们的指点。
本文章适用人群:
1、零基础的新人;
2、Python刚刚懂基础语法的新人;
学习定向爬虫前需要的基础:
1、Python语法基础;
2、请阅读或者收藏以下几个网站:
1)Requests库
http://cn.python-requests.org/zh_CN/latest/
2)BeautifulSoup4库
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
如果没有Python基础的新人,我建议可以学习以下资料:
1、官方最新的英文文档(https://docs.python.org/3/)
2、python 3.60版本中文文档(http://www.pythondoc.com/pythontutorial3/index.html)
3、廖雪峰Python教程(https://www.liaoxuefeng.com/)
备注:书籍也有很多选择,但是其实入门教程讲来讲去都是那些东西,不做细究,你随意挑一本完完整整的学习好比你浪费时间选择教材要强多了。
正文开始:
我假设你已经符合上述的标准,现在我们就来开始第一个爬虫的网站,我们首先挑选一个下手;
附上URL:中国天气网(http://www.weather.com.cn/weather1d/101280101.shtml#dingzhi_first)
第一步:
请确保你已经安装了Requests和Beautifulsoup4的库,否则你可以打开CMD(命令提示符)然后输入
pip3 install requestspip3 install Beautifulsoup4pip3 install lxml安装完毕后接着打开你的编辑器,这里对编辑器不做纠结,用的顺手就好。
首先我们做爬虫,拿到手第一个步骤都是要先获取到网站的当前页的所有内容,即HTML标签。所以我们先要写一个获取到网页HTML标签的方法。
整个爬虫的的代码搭建我都采用的是将不同的功能做成不同的函数,在最后需要调用的时候进行传参调用就好了。
那么问题来了,为什么要这么做呢?
写代码作为萌新要思考几件事:
1、这个代码的复用性;
2、这个代码的语义化以及功能解耦;
3、是否美观简洁,让别人看你的代码能很清楚的理解你的逻辑;
代码展示:
'''
抓取每天的天气数据
python 3.6.2
url:http://www.weather.com.cn/weather1d/101280101.shtml#dingzhi_first
'''
import requests
import bs4
def get_html(url):
'''
封装请求
'''
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'ContentType':
'text/html; charset=utf-8',
'Accept-Encoding':
'gzip, deflate, sdch',
'Accept-Language':
'zh-CN,zh;q=0.8',
'Connection':
'keep-alive',
}
try:
htmlcontet = requests.get(url, headers=headers, timeout=30)
htmlcontet.raise_for_status()
htmlcontet.encoding = 'utf-8'
return htmlcontet.text
except:
return " 请求失败 "上述代码几个地方我特别说明一下:
'''
抓取每天的天气数据
python 3.6.2
url:http://www.weather.com.cn/weather1d/101280101.shtml#dingzhi_first
'''
import requests
import bs4养成好习惯代码一开始的注释表明这是一个什么功能的Python文件,使用的版本是什么,URL地址是什么,帮助你下次打开的时候能快速理解这个文件的用途。
由于Requests和Beautifulsoup4是第三方的库,所以在下面要用import来进行引入
然后是
def get_html(url):
'''
封装请求
'''
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'ContentType':
'text/html; charset=utf-8',
'Accept-Encoding':
'gzip, deflate, sdch',
'Accept-Language':
'zh-CN,zh;q=0.8',
'Connection':
'keep-alive',
}
try:
htmlcontet = requests.get(url, headers=headers, timeout=30)
htmlcontet.raise_for_status()
htmlcontet.encoding = 'utf-8'
return htmlcontet.text
except:
return " 请求失败 "其中
def get_html(url):构造一个名为get_html的函数,并传入你要请求的URL地址进去,会返回一个请求后的结果,
构造好后,调用的时候直接
url = '包裹你的url'
get_html(url)然后同样备注好你的这个函数的功能是做什么的,headers里面包裹了一些伪装成浏览器访问的一些头部文件可以直接你复制过去使用。
这里要说一下为什么要做基础的伪装成浏览器,由于有了爬虫,自然就有反爬虫。有些网站为了恶意避免爬虫肆意爬取或者进行攻击等等情况,会做大量的反爬虫。伪装浏览器访问是反爬虫的一小步。
好了我们继续,
htmlcontet = requests.get(url, headers=headers, timeout=30)
htmlcontet.raise_for_status()
htmlcontet.encoding = 'utf-8'
return htmlcontet.text第一条如果我们看了Requests之后就知道这是一个解析你传入的url,并包含了请求头,响应延时
第二条,如果当前页面响应的情况会返回一个json数据包,我们通过这个语法来确认是否为我们要的成功响应的结果
第三条,解析格式,由于该网站我们可以看到已知字符编码格式为utf-8所以在这里我就写死了是utf-8
最后都没问题后,返回一个页面文件出来
第二步:
拿到一个页面文件后,我们就需要观察一下该网页的HTML结构
这里介绍一下如何观察一个网页的结构,打开F12或者,找个空白的位置右键——>检查
我们大概会看到这样的一个情况:
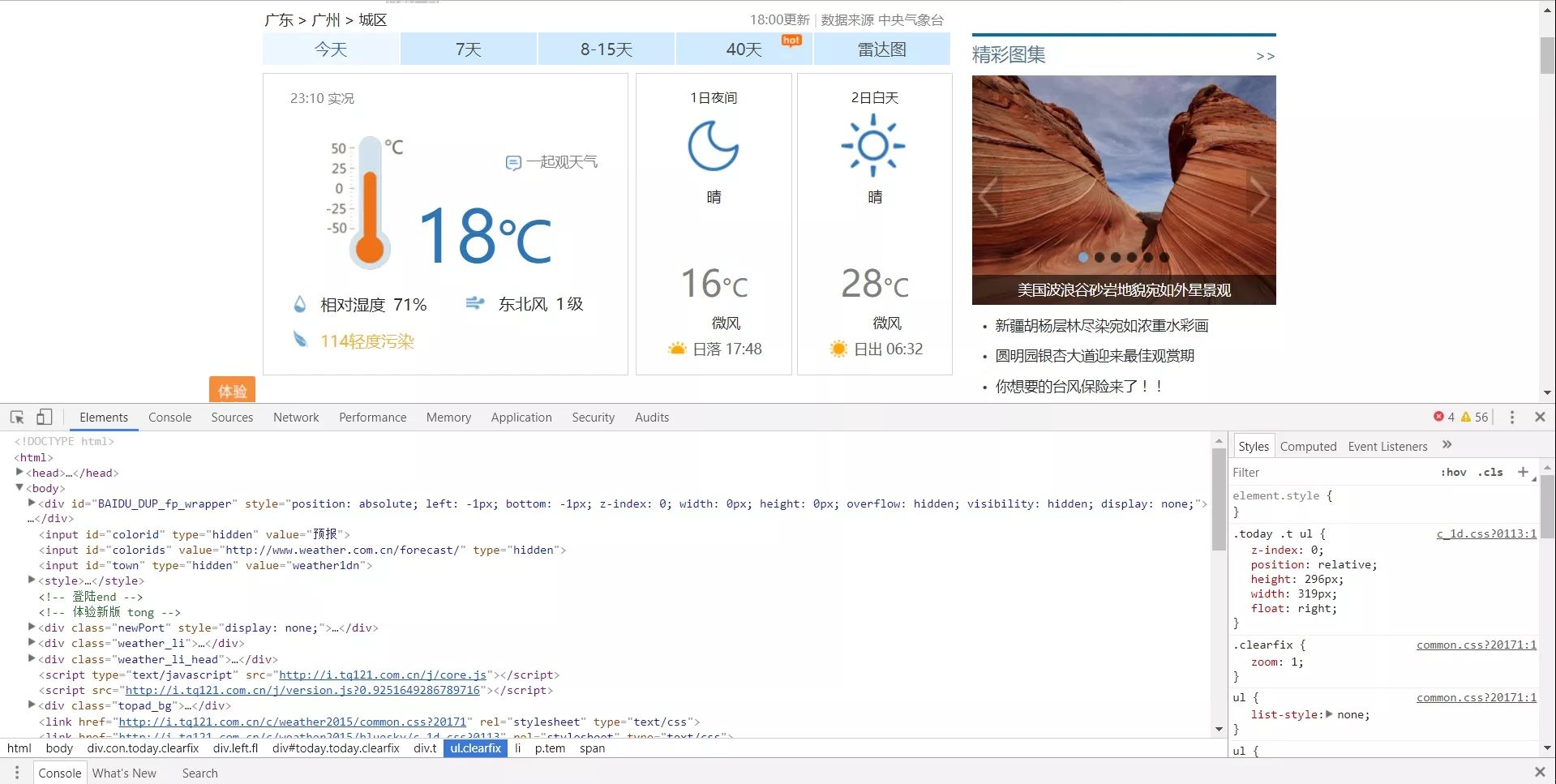
没错你看到那些<body><div>这些就是HTML语言,我们爬虫就是要从这些标记里面抓取出我们所需要的内容。
我们现在要抓取这个1日夜间和2日白天的天气数据出来:
我们首先先从网页结构中找出他们的被包裹的逻辑
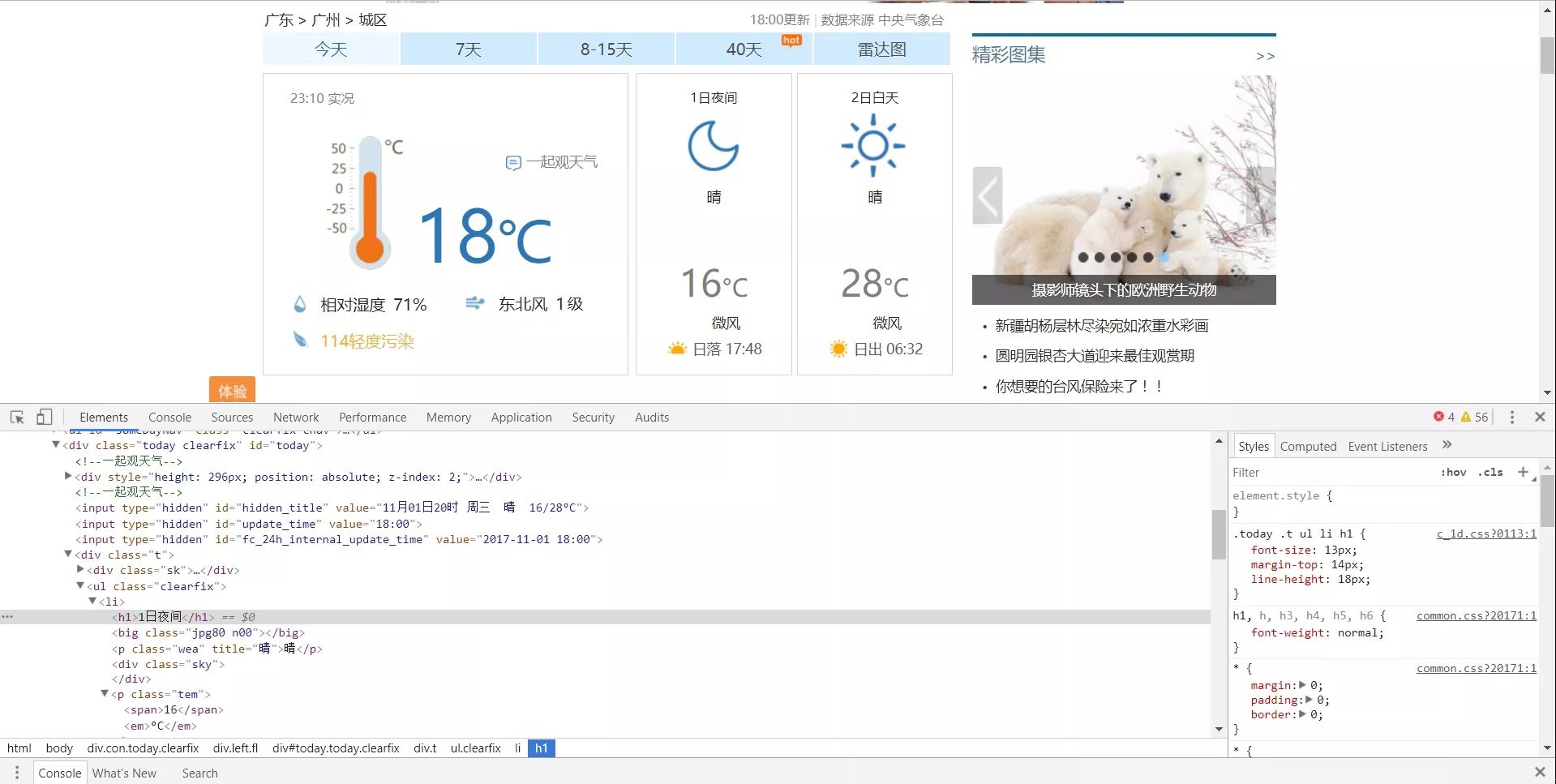
很清楚的能看到他们的HTML嵌套的逻辑是这样的:
<div class="con today clearfix">
|
|_____<div class="left fl">
|
|_____<div class="today clearfix" id="today">
|
|______<div class="t">
|
|_____<ul class="clearfix">
|
|_____<li>
|
|_____<li>我们要的内容都包裹在li里面,然后这里我们就要用BeautifulSoup里面的find方法来进行提取查询
我们继续构建一个抓取网页内容的函数,由于我们最终要的数据有两条,所有我先声明一个weather_list的数组来等会保存我要的结果。
代码如下:
def get_content(url):
'''
抓取页面天气数据
'''
weather_list = []
html = get_html(url)
soup = bs4.BeautifulSoup(html, 'lxml')
content_ul = soup.find('div', class_='t').find_all('li')
for content in content_ul:
try:
weather = {}
weather['day'] = content.find('h1').text
weather['temperature'] = content.find(
'p', class_='tem').span.text + content.find(
'p', class_='tem').em.text
weather_list.append(weather)
except:
print('查询不到')
print (weather_list)同样的话不说第二遍,我们要写好注释。在声明完数组后,我们就可调用刚才封装好的请求函数来请求我们要的URL并返回一个页面文件,接下来就是用Beautifulsoup4里面的语法,用lxml来解析我们的网页文件。
你们可以用
soup = bs4.BeautifulSoup(html, 'lxml')
print (soup)就可以看到整个HTML结构出现在你眼前,接下来我就们就根据上面整理出来的标签结构来找到我们要的信息
content_ul = soup.find('div', class_='t').find_all('li')具体方法,要熟读文档,我们找到所有的li后会返回一个这样的结构

这是一个数组的格式,然后我们遍历它,构造一个字典,我们对于的操作字典建立'day','temperature'键值对
for content in content_ul:
try:
weather = {}
weather['day'] = content.find('h1').text
weather['temperature'] = content.find(
'p', class_='tem').span.text + content.find(
'p', class_='tem').em.text
weather_list.append(weather)
except:
print('查询不到')
print(weather_list)最后输出
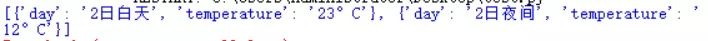
附上完整代码:
'''
抓取每天的天气数据
python 3.6.2
url:http://www.weather.com.cn/weather1d/101190401.shtml
'''
import json
import requests
import bs4
def get_html(url):
'''
封装请求
'''
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36',
'ContentType':
'text/html; charset=utf-8',
'Accept-Encoding':
'gzip, deflate, sdch',
'Accept-Language':
'zh-CN,zh;q=0.8',
'Connection':
'keep-alive',
}
try:
htmlcontet = requests.get(url, headers=headers, timeout=30)
htmlcontet.raise_for_status()
htmlcontet.encoding = 'utf-8'
return htmlcontet.text
except:
return " 请求失败 "
def get_content(url):
'''
抓取页面天气数据
'''
weather_list = []
html = get_html(url)
soup = bs4.BeautifulSoup(html, 'lxml')
content_ul = soup.find('div', class_='t').find('ul', class_='clearfix').find_all('li')
for content in content_ul:
try:
weather = {}
weather['day'] = content.find('h1').text
weather['temperature'] = content.find(
'p', class_='tem').span.text + content.find(
'p', class_='tem').em.text
weather_list.append(weather)
except:
print('查询不到')
print(weather_list)
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather1d/101190401.shtml'
get_content(url)欢迎大神,萌新指教,讨论~

来自:Victor 278
https://zhuanlan.zhihu.com/p/30632556
程序员大咖整理发布,转载请联系作者获得授权
















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









