







利用Scrapy爬取职友集中企业的信息数据
需求分析
- 要抓取的地址url: http://www.jobui.com/cmp
- 要抓取的信息,是对应的每个公司详情页中的数据
- 首先需要获取所有公司的列表,程序自动翻页,获取下一页的链接地址,获取每个公司的详情页的url
- 获取到详情页的url 发起请求,在详情页中获取想要抓取的数据
代码编写
首先利用命令行创建爬虫项目
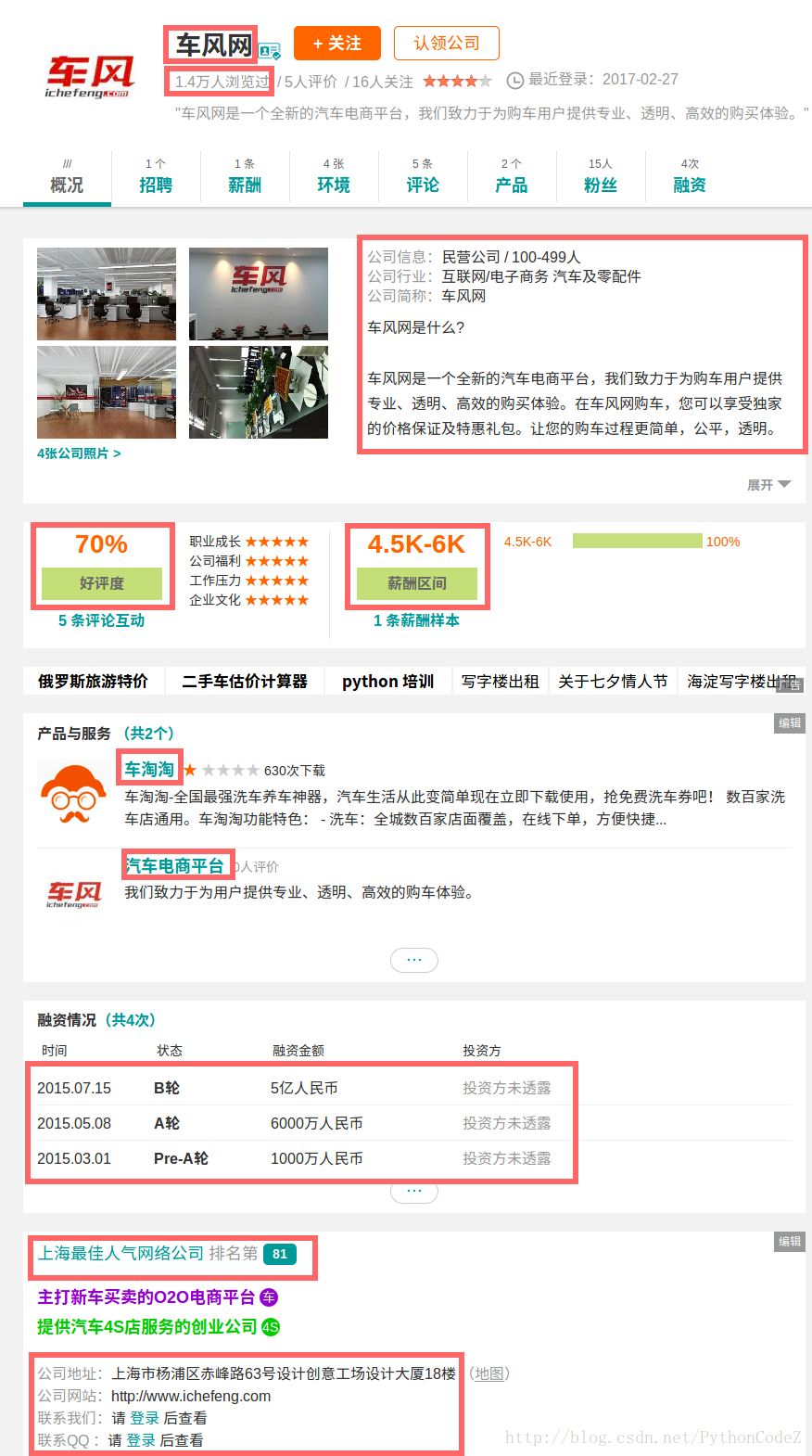
scrapy startproject ZhiYouJi编写项目的items文件,定义要保存的字段,下图找了一个信息比较全的公司的详情页,要保存的信息就是红框圈出来的信息.那我们编辑items.py文件
import scrapy class ZhiyoujiItem(scrapy.Item): # 公司名 name = scrapy.Field() # 浏览量 views = scrapy.Field() # 公司性质 type = scrapy.Field() # 公司规模 size = scrapy.Field() # 行业 industry = scrapy.Field() # 公司简称 abbreviation = scrapy.Field() # 公司信息 info = scrapy.Field() # 好评度 praise = scrapy.Field() # 薪资区间 salary_range = scrapy.Field() # 公司产品 products = scrapy.Field() # 融资情况 financing_situation = scrapy.Field() # 公司排名 rank = scrapy.Field() # 公司地址 address = scrapy.Field() # 公司网站 website = scrapy.Field() # 公司联系方式 contact = scrapy.Field() # qq qq = scrapy.Field()编写好了items文件后,我们可以创建爬虫文件了,这里我使用的是CrawlSpider,使用命令行创建爬虫文件之前,我们需要先cd到ZhiYouJi文件夹中,然后使用命令:
scrapy genspider -t crawl zhiyouji 'jobui.com'创建好爬虫文件后,我们使用pycharm打开项目
这样我们前期的就准备好了,接下来就是怎么去编写爬虫,怎么去获取数据了.
打开spider路径下的zhiyouji.py文件,在这里我们先分析一波.
首先我们要确定我们的起始的url也就是start_url,修改文件中start_url
start_urls = ['http://www.jobui.com/cmp']首先,网站的数据是分页的,我们要获取到下一页的url.
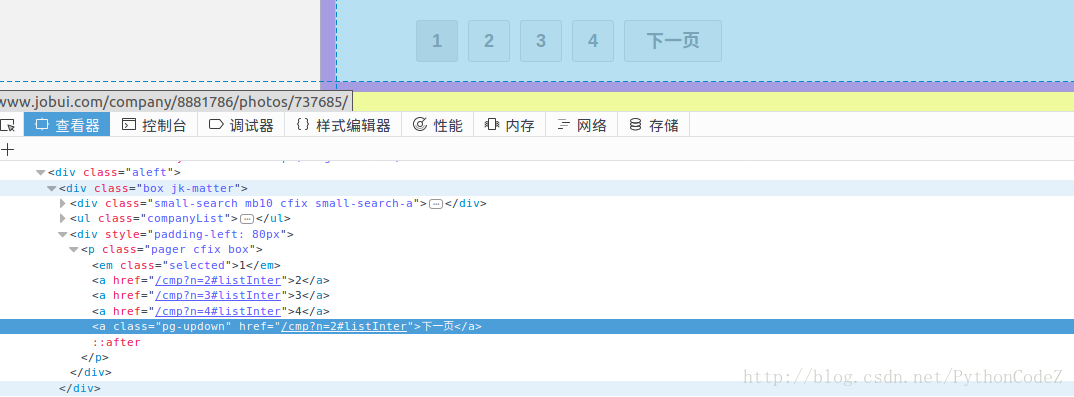
通过分析,我们发现下一页的url地址的 规律就是/cmp?n=页数#listInter,那我们可以使用正则将下一页的链接提取出来.
# 获取下一页的url Rule(LinkExtractor(allow=r'/cmp\?n=\d+\#listInter'), follow=True),获取到了下一页的url地址,我们接下来就是要获取详情页的url地址了,通过查看发现,详情页的链接的规律是/company/数字/,那就可以使用正则来匹配出详情页的url
# 获取详情页的url Rule(LinkExtractor(allow=r'/company/\d+/$'), callback='parse_item', follow=False),获取详情页链接时,我们制定了回调函数,parse_item,那么接下来就要在函数里面提取我们想要得到的数据了.代码其实很见到,就是利用了xpath来提取自己想要拿到的数据,xpath不熟悉的小伙伴可以去网上找一下教程学一下,下面放代码:
def parse_item(self, response): # 实例化item对象 item = ZhiyoujiItem() # 使用xpath提取数据 # 公司名称 item['name'] = response.xpath('//*[@id="companyH1"]/a/text()').extract_first() # 浏览量 item['views'] = response.xpath('//div[@class="grade cfix sbox"]/div[1]/text()').extract_first().split(u'人')[0].strip() """ 有些公司的详情页面没有图片 所以页面的结构有些不同 """ # 公司性质 try: item['type'] = response.xpath('//div[@class="cfix fs16"]/dl/dd[1]/text()').extract_first().split('/')[0] except: item['type'] = response.xpath('//*[@id="cmp-intro"]/div/div/dl/dd[1]/text()').extract_first().split('/')[0] # 公司规模 try: item['size'] = response.xpath('//div[@class="cfix fs16"]/dl/dd[1]/text()').extract_first().split('/')[1] except: item['size'] = response.xpath('//*[@id="cmp-intro"]/div/div/dl/dd[1]/text()').extract_first().split('/')[1] # 行业 item['industry'] = response.xpath('//dd[@class="comInd"]/a[1]/text()').extract_first() # 公司简称 item['abbreviation'] = response.xpath('//dl[@class="j-edit hasVist dlli mb10"]/dd[3]/text()').extract_first() # 公司信息 item['info'] = ''.join(response.xpath('//*[@id="textShowMore"]/text()').extract()) # 好评度 item['praise'] = response.xpath('//div[@class="swf-contA"]/div/h3/text()').extract_first() # 薪资区间 item['salary_range'] = response.xpath('//div[@class="swf-contB"]/div/h3/text()').extract_first() # 公司产品 item['products'] = response.xpath('//div[@class="mb5"]/a/text()').extract() # 融资情况 data_list = [] node_list = response.xpath('//div[5]/ul/li') for node in node_list: temp = {} # 融资日期 temp['date'] = node.xpath('./span[1]/text()').extract_first() # 融资状态 temp['status'] = node.xpath('./h3/text()').extract_first() # 融资金额 temp['sum'] = node.xpath('./span[2]/text()').extract_first() # 投资方 temp['investors'] = node.xpath('./span[3]/text()').extract_first() data_list.append(temp) item['financing_situation'] = data_list # 公司排名 data_list = [] node_list = response.xpath('//div[@class="fs18 honor-box"]/div') for node in node_list: temp = {} key = node.xpath('./a/text()').extract_first() temp[key] = int(node.xpath('./span[2]/text()').extract_first()) data_list.append(temp) item['rank'] = data_list # 公司地址 item['address'] = response.xpath('//dl[@class="dlli fs16"]/dd[1]/text()').extract_first() # 公司网址 item['website'] = response.xpath('//dl[@class="dlli fs16"]/dd[2]/a/text()').extract_first() # 联系方式 item['contact'] = response.xpath('//div[@class="j-shower1 dn"]/dd/text()').extract_first() # qq号码 item['qq'] = response.xpath('//dd[@class="cfix"]/span/text()').extract_first() # for k,v in item.items(): # print k,v # print '****************************************' yield item上面代码中需要注意的地方:
- 首先有的详情页面公司概况的地方是有图片的,而有的公司是没有图片的,这就造成了我们写的xpath可能遇到没有图片的页面会匹配不到数据,所有就进行了相应的处理.
""" 有些公司的详情页面没有图片 所以页面的结构有些不同 """ # 公司性质 try: item['type'] = response.xpath('//div[@class="cfix fs16"]/dl/dd[1]/text()').extract_first().split('/')[0] except: item['type'] = response.xpath('//*[@id="cmp-intro"]/div/div/dl/dd[1]/text()').extract_first().split('/')[0] # 公司规模 try: item['size'] = response.xpath('//div[@class="cfix fs16"]/dl/dd[1]/text()').extract_first().split('/')[1] except: item['size'] = response.xpath('//*[@id="cmp-intro"]/div/div/dl/dd[1]/text()').extract_first().split('/')[1]其余的地方,就是正常的使用xpath来提取出自己想要的数据.
数据提取完了,把数据保存成json数据.打开管道文件pipelines.py
import json class ZhiyoujiPipeline(object): def open_spider(self, spider): self.file = open('zhiyouji.json', 'w', encoding='utf-8') def process_item(self, item, spider): data = json.dumps(dict(item), ensure_ascii=False, indent=2) self.file.write(data) return item def close_spider(self, spider): self.file.close()使用管道来保存数据,那我们就要将settings文件中的管道打开:
ITEM_PIPELINES = { 'ZhiYouJi.pipelines.ZhiyoujiPipeline': 300, }再使用命令运行爬虫
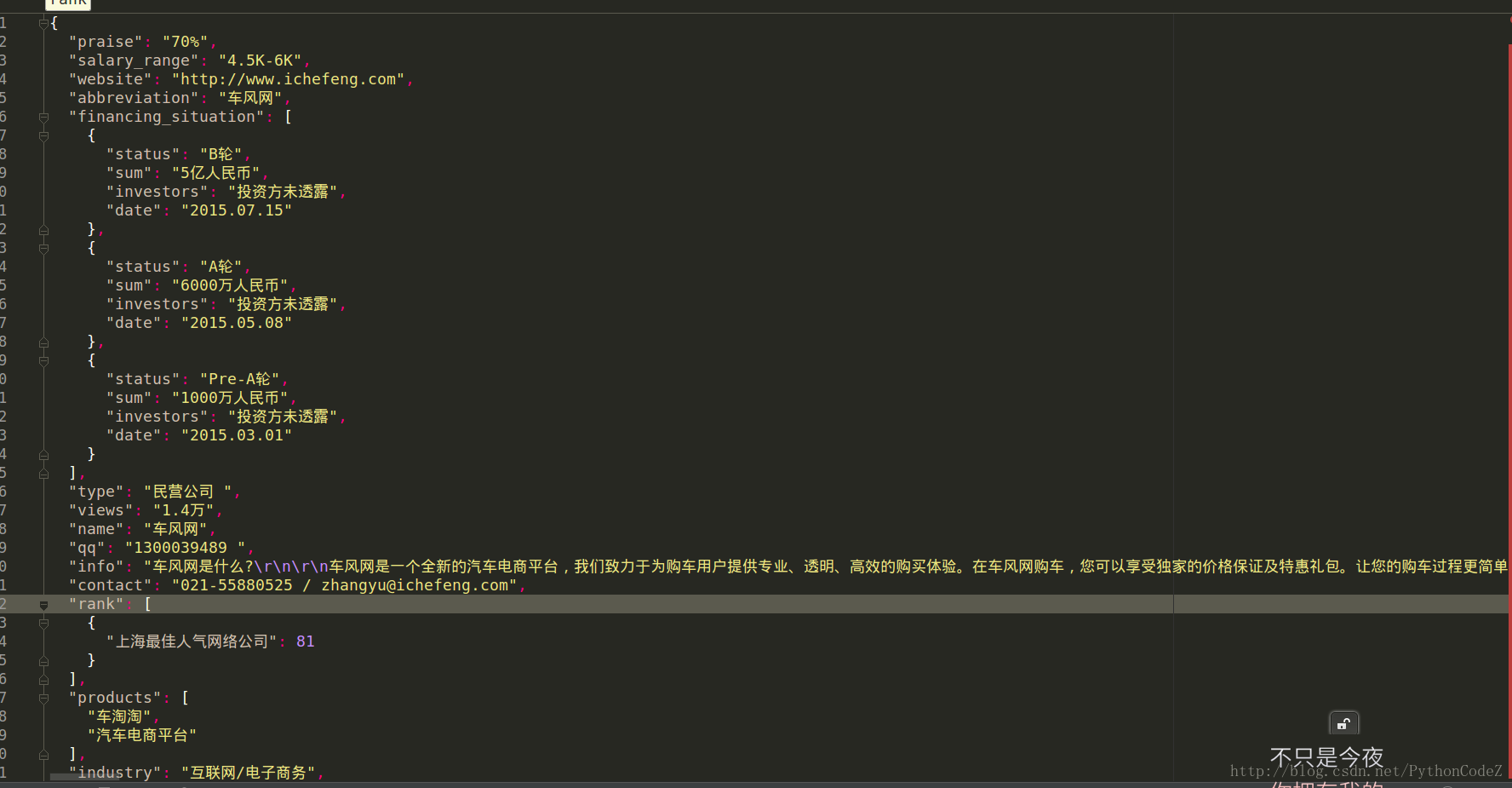
scrapy crawl zhiyouji由于数据太多,运行了一下就强行就项目停止了.下面的json文件中是保存的部分数据,
项目改成scrapy-radis分布式爬虫.下一篇上改造过后的项目.















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









