






源地址:Hadoop伪分布式与集群安装
目录:
1、配置前的说明
配置前的说明
部署伪分布式与集群式 Hadoop 的绝大部分操作都是一样的,细节上区别在于集群式是在两台机子上部署的,两台机子都要执行下列操作,
伪分布式都是在一台机子上操作;
以下全部操作如没有特别说明,则伪分布式操作与集群式操作等同。
环境说明
| 伪分布式Hadoop l 本次hadoop配置的为伪分布模式,即在一个机子上作为namenode,又作为datanode。 l 操作系统:CentOS5.5 l JDK:1.6.0_26 l Hadoop:hadoop-0.21.0 |
| 集群分布式Hadoop l 本次hadoop配置的为集群分布模式,即在一个机子上作为namenode,另一台机子作为datanode。 l 操作系统:CentOS5.5 l JDK:1.6.0_26 l Hadoop:hadoop-0.21.0 l 网络配置  |
查看主机名
使用下面命令进行查看主机名,若要更改,请查看下一步操作。
#hostname
修改主机名
第一步,查看主机IP地址。
用下面命令即可查看,本机IP为192.168.1.101(以下操作请使用root用户方可执行)

第二步,若想更改主机名,则可以通过修改文件“/etc/sysconfig/network”中的HOSTNAME后面的值,即可改成我们想要的名字。
用下面命令进行修改主机名。
nano /etc/sysconfig/network
NETWORKING=yes
NETWORKING_ipv6=no
HOSTNAME=yeweipeng.localdomain第三步,修改文件“/etc/hosts”。
使用命令打开后更改为如图所示的样子。将原有的全部注释(前面加#),namenode为第一个,datanode为第二个。
因为伪分布式模式是namenode和datanode为同一个的,所以两个都是一样。

集群式则修改为如图所示。(两个机子修改为一样的,第一个为namenode,第二个datanode)

SSH无密码验证配置
在我们使用的Linux系统中,已经含有SSH的所有需要的套件了,默认情况下不需要安装。
以下操作要在root权限下进行。
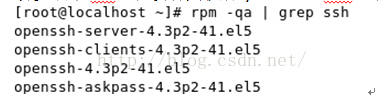
1.检查Linux是否安装SSH:rmp -qa|grep ssh,出现以下信息说明已安装,否则使用sudo apt-get ssh-server下载安装;
2.开启SSH服务:


3.查看SSH是否开机自启动:chkconfig --list sshd,如图为开机自启动。

4.设置SSH开机自启动:chkconfig sshd on,即可设置成功。下次开机时即可,自启动。若要查看运行3.
还要安装rsync,执行命令sudo yum install rsync。
创建Hadoop用户
使用root用户创建hadoop用户,依次执行下列命令即可。(集群模式则每台机器都需要这样操作)

生成SSH密钥

上述为伪分布式SSH配置成功,若为集群式还需要下列一个操作方可。

JDK配置
使用命令apt-get直接安装 OpenJDK 7

OpenJDK 默认的安装位置为: /usr/lib/jvm/java-7-openjdk-amd64 (32位系统则是 /usr/lib/jvm/java-7-openjdk-i86 ,可通过命令dpkg -L openjdk-7-jdk查看到)。安装完后就可以使用了,可以用 java -version 检查一下。
接着需要配置一下 JAVA_HOME 环境变量,在/etc/profile文件中添加下面内容:
打开vi /etc/profile:
export JAVA_HOME=/jdk1.7
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/bin:$PATHsource /etc/profile使变量生效。
执行命令java –version验证安装成功。

Hadoop安装配置
安装Hadoop
以下操作若不能执行,则使用visudo(该命令需要root权限)给hadoop用户添加最高权限,发生权限不足时,在每条命令前加sudo即可。
如图所示。该命令使用vi编辑器

注销,切换到hadoop用户下。新建目录sudo mkdir /usr/local/hadoop,
将hadoop-0.21.0.tar.gz解压缩到该目录下,在压缩包所在的文件夹下执行sudo tar -xvzf hadoop-0.21.0.tar.gz –C /usr/local/hadoop
配置环境变量
修改/etc/profile文件,在文件最后添加两行。
export HADOOP_HOME=/usr/local/hadoop/hadoop-0.21.0
export PATH=$HADOOP_HOME/bin:$PATH配置master和slave
两个文件在/usr/local/hadoop/hadoop-0.21.0/conf/下面,
master文件填写
192.168.1.101(namenode的IP)
slave文件填写
192.168.1.101(datanode的IP)
因为是伪分布,所以都一样,且只有一个。若为集群,则为
master文件填写
192.168.1.147(namenode的IP)
slave文件填写
192.168.1.103(datanode的IP)配置三个xml文件
三个xml文件都是在/usr/local/hadoop/hadoop-0.21.0/conf/配置core-site.xml
创建文件夹mkdir /usr/hadoop/hadoop-0.21.0/tmp
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://yeweipeng(你的master机器名):9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-0.21.0/tmp</value>
</property>
</configuration>
配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1(datanode的数目)</value>
</property>
</configuration>配置 mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value><span style="font-family: Arial, Helvetica, sans-serif;">yeweipeng</span><span style="font-family: Arial, Helvetica, sans-serif;">(你的master机器名):9001</value></span>
</property>
</configuration>准备工作
使用root权限关闭防火墙,执行/etc/init.d/iptables stop,运行命令/etc/init.d/iptables status查看防火墙状态。
使用hadoop用户,将目录切换到/usr/local/hadoop/hadoop-0.21.0/bin下,格式化目录节点,hadoop namenode –format。
集群模式,上述两个操作只需要namenode机器操作,datanode则不需要。(准备工作中两步)在/usr/local/hadoop/hadoop-0.21.0/bin下执行start-all.sh启动hadoop。
用jps查看进程,如图所示有六个进程则为正确(伪分布式)

网页查看集群
打开http://yeweipeng(主机名):50070查看节点状况
打开http://yeweipeng(主机名):50030查看job状况 ;
测试
创建目录haoop fs -mkdir test
上传haoop fs -put 你要上传的目录
下载haoop fs -get 云端的目录 本地目录
配置中出现的错误
问题:启动成功后,发现在master查看live nodes为0
解决方案如下:
将文件/etc/hosts内原有的文件内容注释掉,添加namenode和datanode的IP地址与主机名。
问题:启动hadoop后,执行jps命令只有一个jps进程
解决方案如下:
只有一个进程的原因在于三个xml文件,master,slave的设置错误。
1. 在配置过程的xml文件我们将主机名都写为master导致错误,则将其改为namenode的主机名方可。
2. master上只能有namenode的IP地址,不得有datanode的地址。同理,slave上只能有datanode的IP地址,不得有namenode的。
问题:伪分布式配置SSH后,无论如何都需要输入密码
解决方案如下:
更改authorized_keys的权限为600
chmod 600 authorized_keys















 2972
2972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









