










Scala与MapReduce的开发需要有一个IDE支持才更方便,本文介绍两个Eclipse插件,方便在Eclipse上开发Scala程序和MapReduce程序。
一、 系统环境
CentOS 6.5
JDK 1.8
Hadoop 2.6.0
Spark 1.6.0
Scala 2.10.4
二、 Eclipse的安装
我们这里选择的版本是eclipse-java-juno-SR2-linux,即Eclipse 3.8,将下载完的包,解压,将解压得到的文件夹放到/usr下面。
运行该目录下面的eclipse.sh即可启动。我们也可以在桌面上创建启动器,命令选择该sh脚本文件即可,方便运行,而不需要每次都输命令。首次启动使用Eclipse,会让我们选择Workspace,即工作空间,以后的工程都会放在这个工作空间里,我们选择自己合适的目录建立一个文件夹当做自己的Workspace既可。至此,Eclipse的安装就完成了。
三、 hadoop-eclipse-plugin-2.6.0的手动安装
下面,我们安装hadoop-eclipse插件,我们的hadoop版本是2.6.0,所以我们选择的插件一定要跟我们的hadoop版本相匹配,否则不能正常使用。从网上搜索插件,下载,该插件是个jar包。接下来我们安装插件。
- 将该jar包放在Eclipse目录的plugins目录下,如/usr/eclipse/plugins。
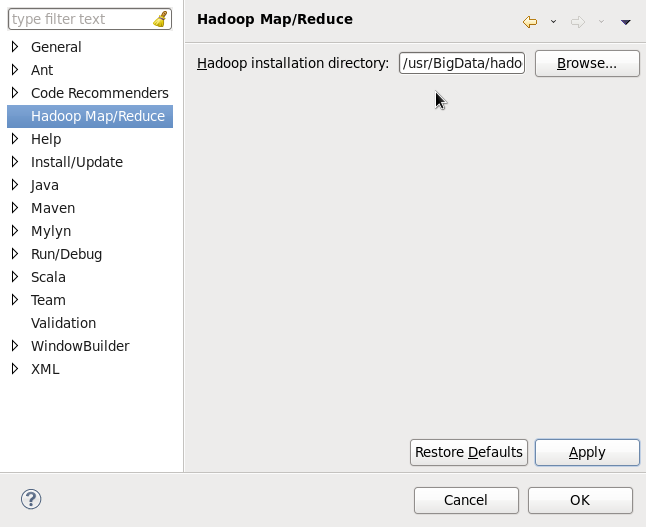
- 启动Eclipse,配置Hadoop installation directory,在Eclipse窗口中,选择Windows——Prefeerces,左栏会有Hadoop Map/Reduce选项,点击,在右面,点击浏览,设置Hadoop的安装路径,OK。如下:
3.配置Map/Reduce Locations
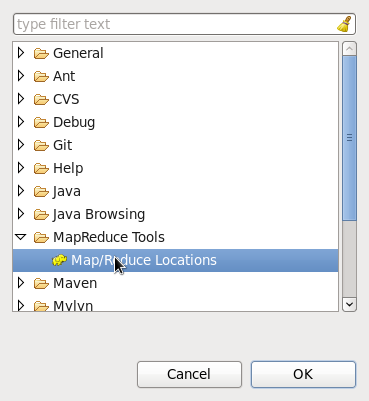
Windows—Open Perspective—Other,选择Map/Reduce,点击OK。如下
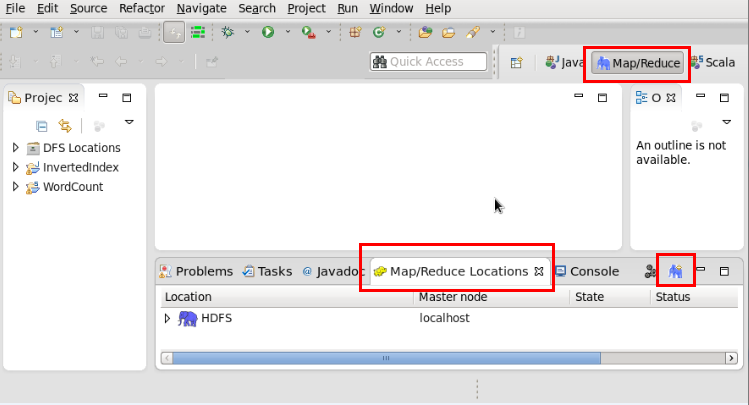
点击Map/Reduce Locations选项卡,点击右上角的小象加号图标,添加一个Hadoop Location 配置。如下:
在弹出的窗口中输入Location Name(任意),配置DFS端口号为9000,如下:
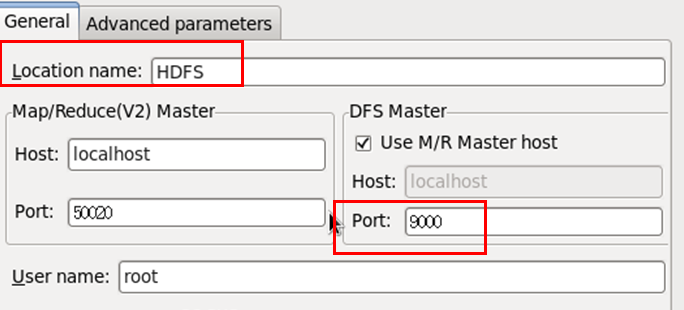
9000即是core-site.xml中的设置,点击Finish,完成配置。点击左侧的DFSLocation展开,如下(文件夹是自己建的,HDFS是我自己命名的Location Name):
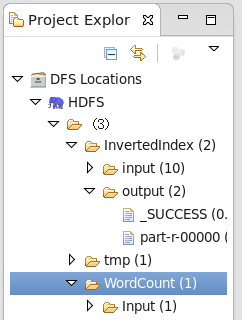
4.测试
File—>Project,选择Map/Reduce Project,输入项目名称InvertedIndex等,Finish,在项目中新建InvertedIndex类。
附(倒排索引代码,来自网络资源,作了修改):
package InvertedIndex;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class InvertedIndex {
public static class InvertedIndexMap extends Mapper<Object, Text, Text, Text> {
private Text valueInfo = new Text();
private Text keyInfo = new Text();
private FileSplit split;
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 获取<key value>对所属的FileSplit对象
split = (FileSplit) context.getInputSplit();
StringTokenizer stk = new StringTokenizer(value.toString());
while (stk.hasMoreElements()) {
// key值由(单词:URI)组成
keyInfo.set(stk.nextToken() + ":" + split.getPath().toString());
// 词频
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
}
public static class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
Text info = new Text();
public void reduce(Text key, Iterable<Text> values, Context contex) throws IOException, InterruptedException {
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
// 重新设置value值由(URI+:词频组成)
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新设置key值为单词
key.set(key.toString().substring(0, splitIndex)+"\n");
contex.write(key, info);
}
}
public static class InvertedIndexReduce extends Reducer<Text, Text, Text, Text> {
private Text result = new Text();
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";\n";
}
result.set(fileList);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "InvertedIndex");
job.setJarByClass(InvertedIndex.class);
job.setMapperClass(InvertedIndexMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}在java文件的空白处右键Run As——Run Configurations…找到Arguments选项卡,配置如下:
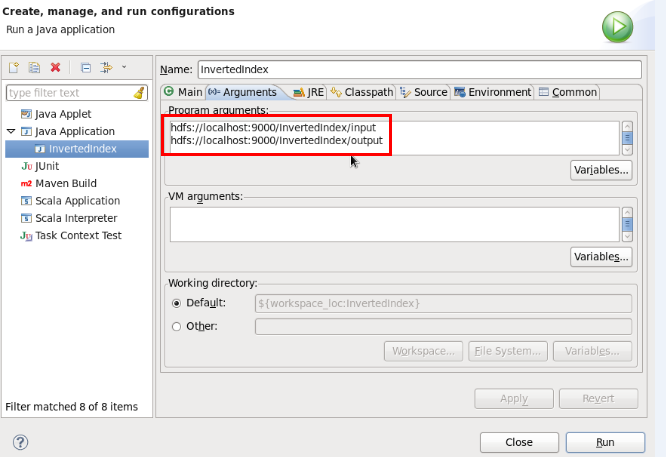
即,配置工程的输入和输出目录,我们都选择hdfs上的目录。需要注意的是,输出目录不能提前存在,否则执行的时候会报错提示输出目录已经存在。
最后,在DFS Location中刷新一下,就可以看到,相应的目录下面多出一个output目录,part-r-…文件即是输出的结果,如下:
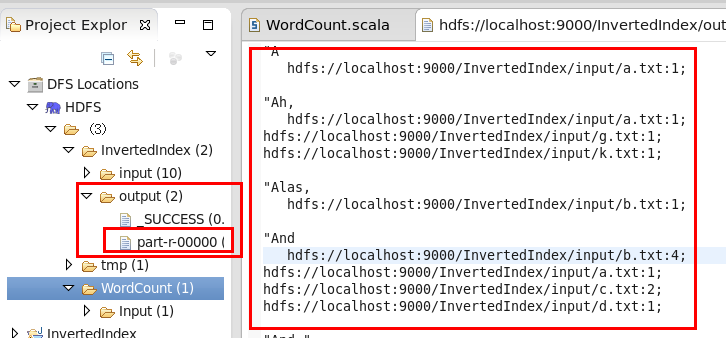
至此,测试成功就证明插件安装完毕,可用。
四、 scala for eclipse的手动安装
本来在Eclipse或IntellJ Idea中插件可以自动从网上安装,但是,由于“种种原因”,可能安装不成功,这里就是scala插件没有自动安装成功后,手动从本地安装的方法。
1. 下载Scala ide
首先,对应Scala和Eclipse的版本下载插件,http://scala-ide.org/download/prev-stable.html,这里由于我们的Scala是2.10.4,Eclipse是3.8,所以我们下载的是

2.安装
下载完成后,解压,得到两个文件夹,一个features,一个plugins,还有另外两个jar包(不理会)。然后在Eclipse窗口中点击Help——Install New Software…,在弹出的窗口中点击Add——Local,定位到刚刚解压插件的包得到的文件夹目录即可,OK。
等待安装完毕即可。
3.配置
接下来,像MapReduce一样,依然是在Windows—Open Perspective—Other中,选择Scala窗口,打开。
4.测试
建立Scala工程,New——Scala Object(如果没有,就到Other里找)。然后建package建class,跟上面一样。
附(WordCount代码,来自网络资源,有修改):
package WordCount
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
/**
* 统计字符出现次数
*/
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: <file>")
System.exit(1)
}
val conf = new SparkConf()
.setMaster("local")
.setAppName("wordcount")
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
可以看出,scala代码完成功能强大且非常简短。红字部分是必须指定的,setMaster指定为本地,AppName可以任意起。如果不指定后面运行时会报错。完成之后我们依然Run As——Run Configurations…找到Arguments选项卡,读入文件依然从HDFS中获得,这时候需要注意的就是,如果要使用HDFS,我们就必须开启Hadoop。
配置如下:
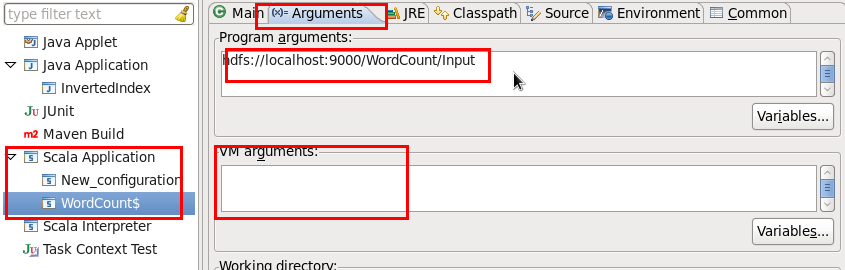
根据个人电脑的配置,有时候会碰到堆栈内存不够而出错的情况,可以在VM arguments中设置如下:-vmargs-Xms256m-Xmx1024m
运行结果如下:
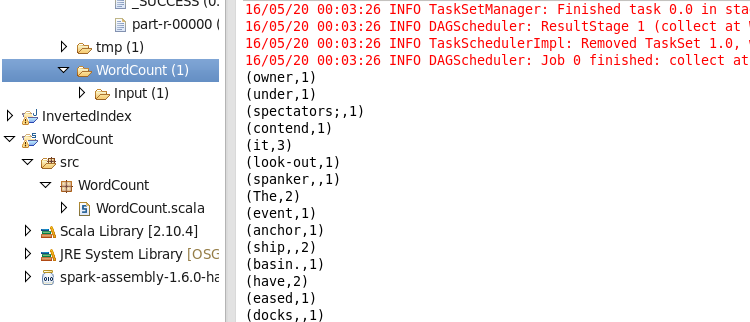
正常运行处结果,表明我们的配置正确。
全部配置成功,我们就可以在Eclipse中方便地开发Scala程序和MapReduce程序了。
Hadoo伪分布搭建http://blog.csdn.net/sunglee_1992/article/details/53024652
Spark+Scala环境搭建http://blog.csdn.net/SungLee_1992/article/details/53024749















 5754
5754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









