







- 课程地址:spark讲解
- Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
- Scala | Spark核心编程 | SparkCore | 算子
- Scala | 宽窄依赖 | 资源调度与任务调度 | 共享变量 | SparkShuffle | 内存管理
- Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
一、学习目标
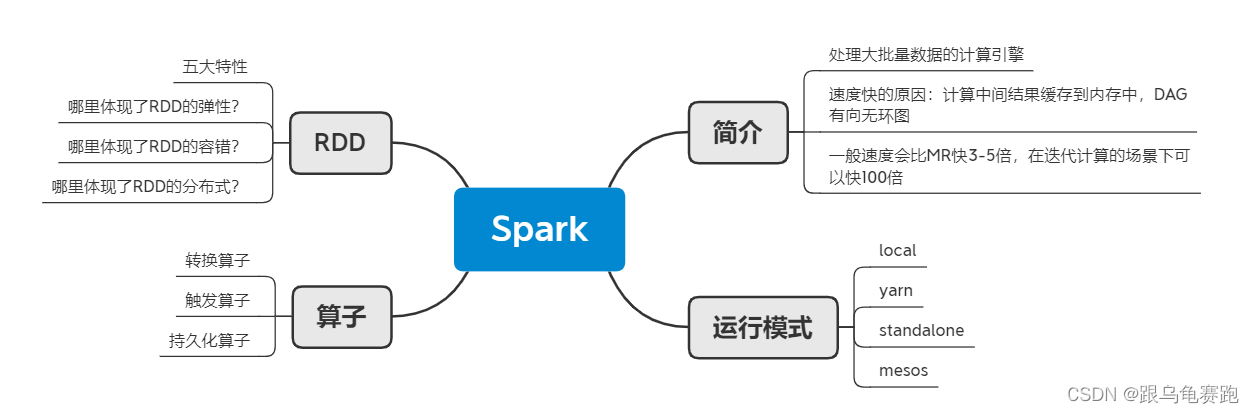
二、本机开发–scala配置
1. 下载Scala
我这里选择的scala2.11.8
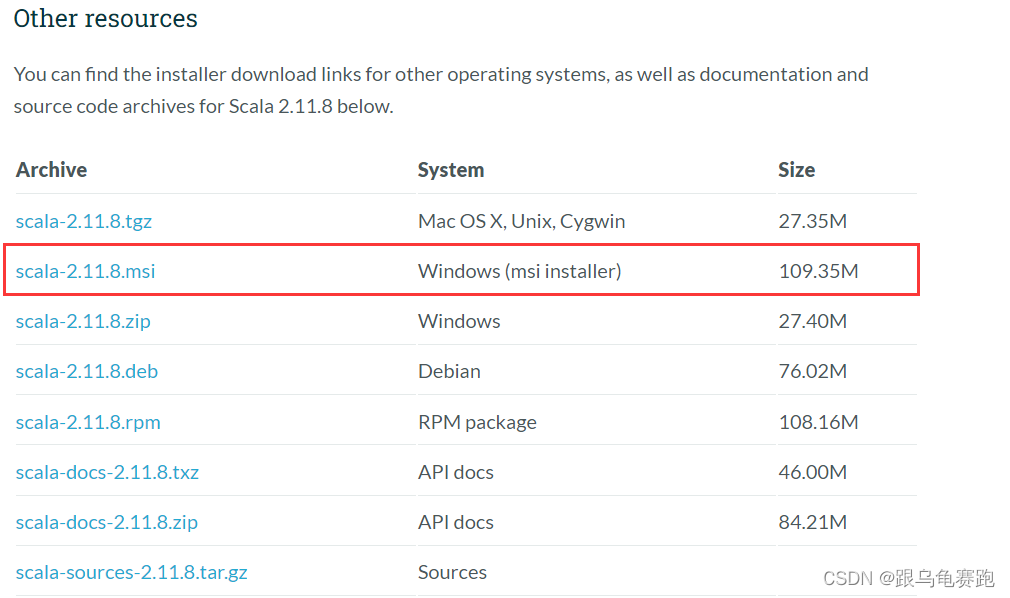
2. 安装scala
- 将下载的scala2.11.8的msi的文件剪切到指定文件夹
D:\scala2.11.8 - 双击点击安装,一直点击next,或者同意协议,然后选择自己的安装目录
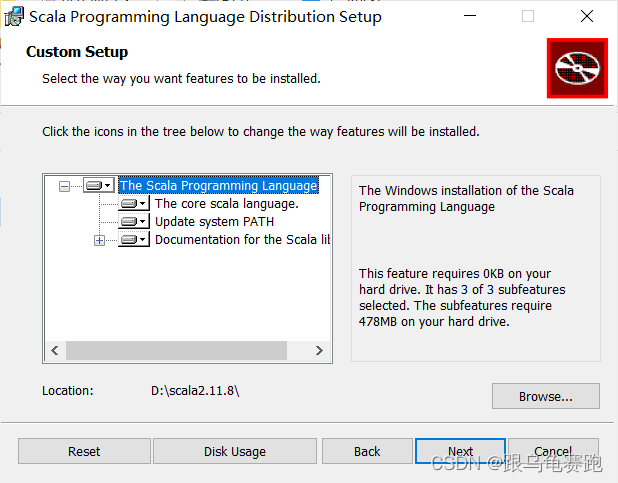
3. 配置Scala的系统环境变量
进入环境变量设置界面。
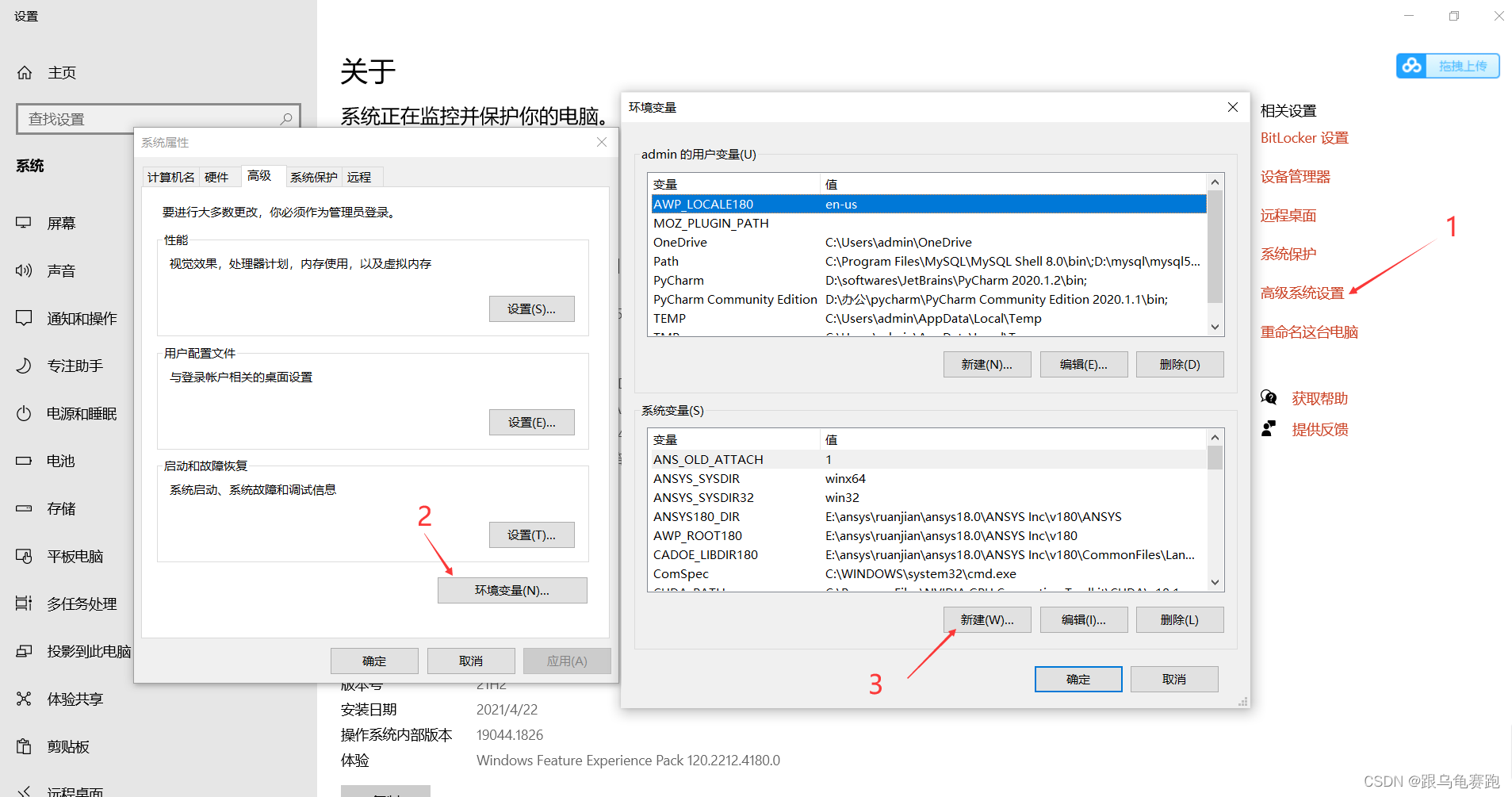
配置SCALA_HOME的地址;
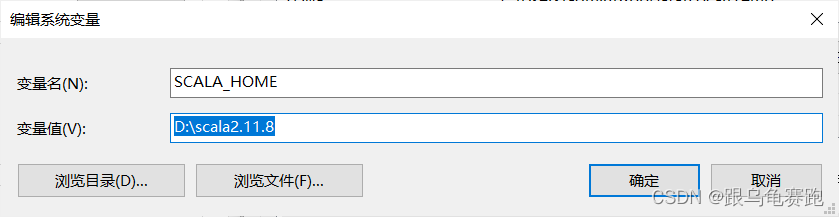
添加到path;
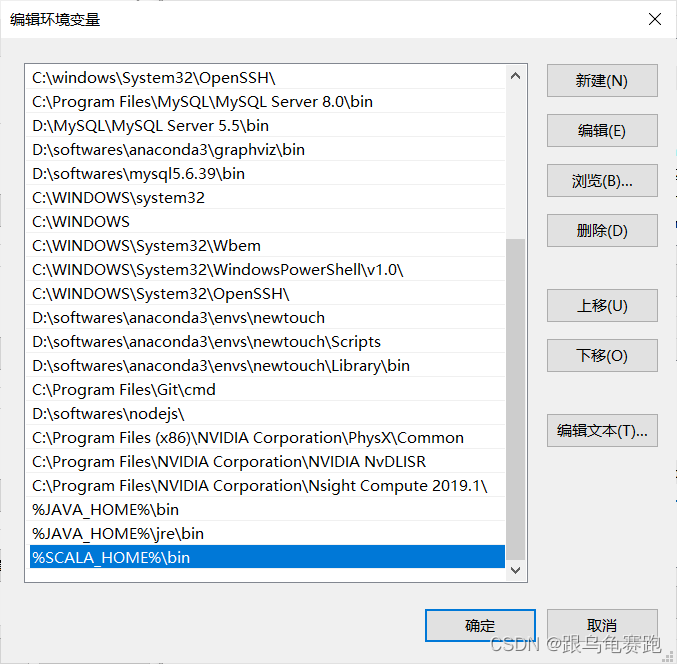
验证是否安装成功;打开命令提示符 输入scala,是否出现对应的版本号;

4. IDEA中的scala配置
新建一个java–spark的java项目
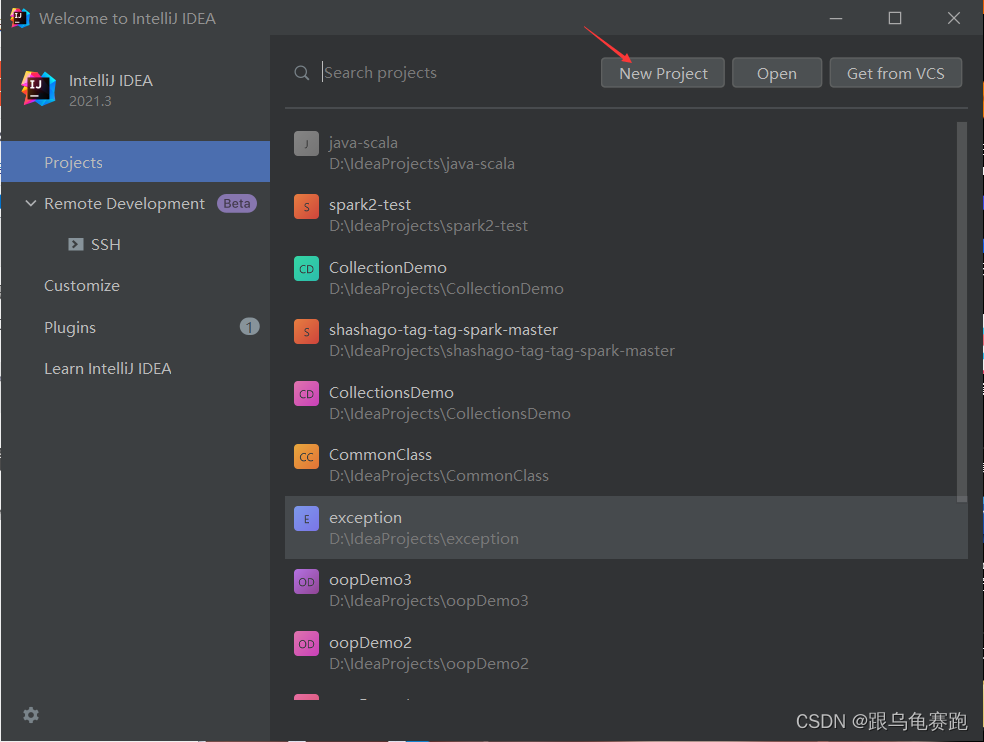
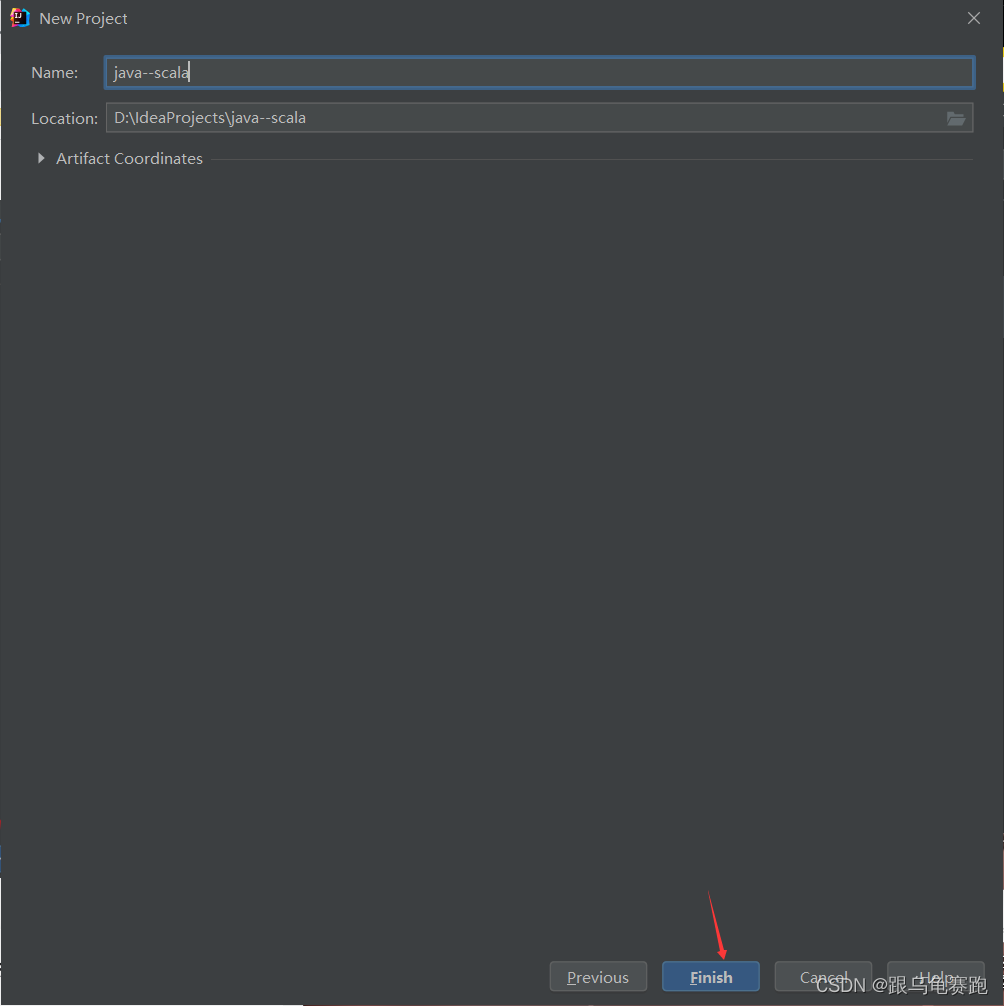
配置下载好的Scala-SDK
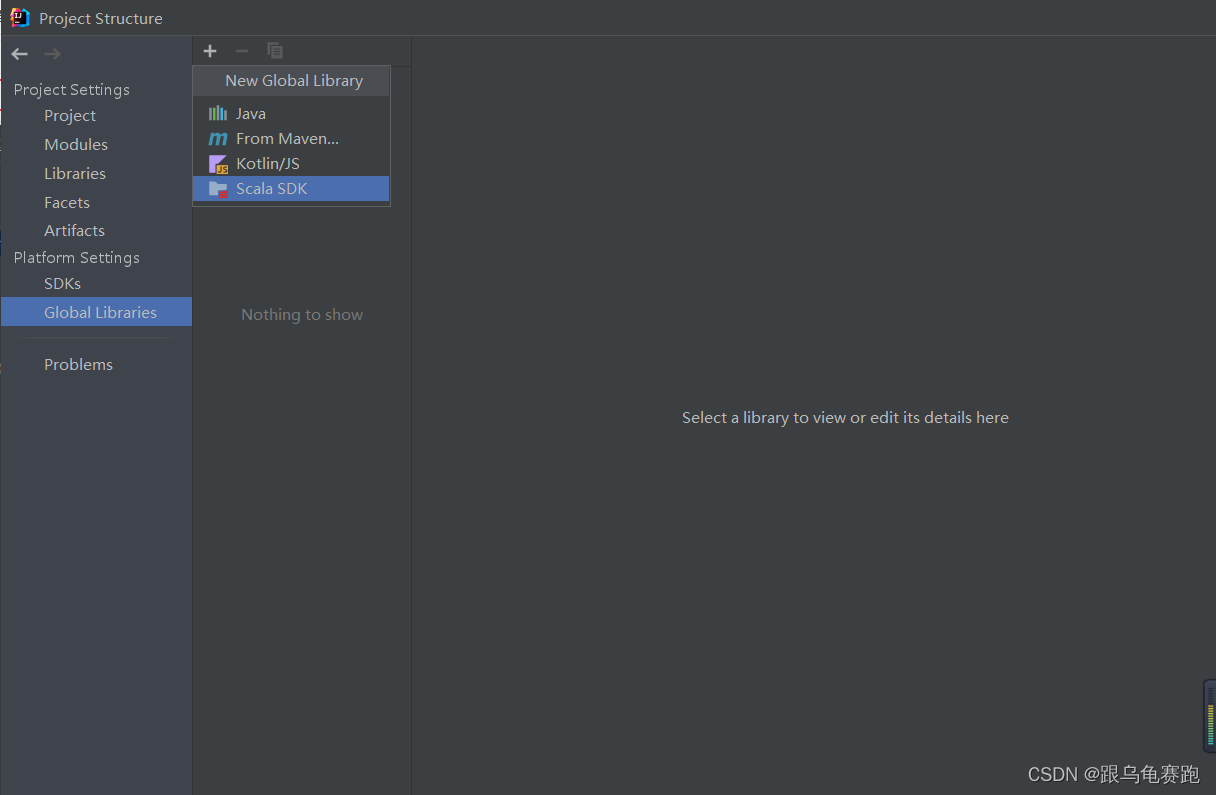
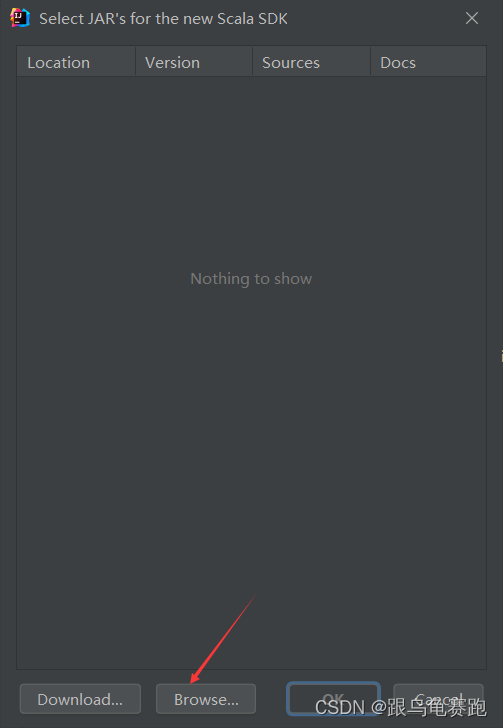
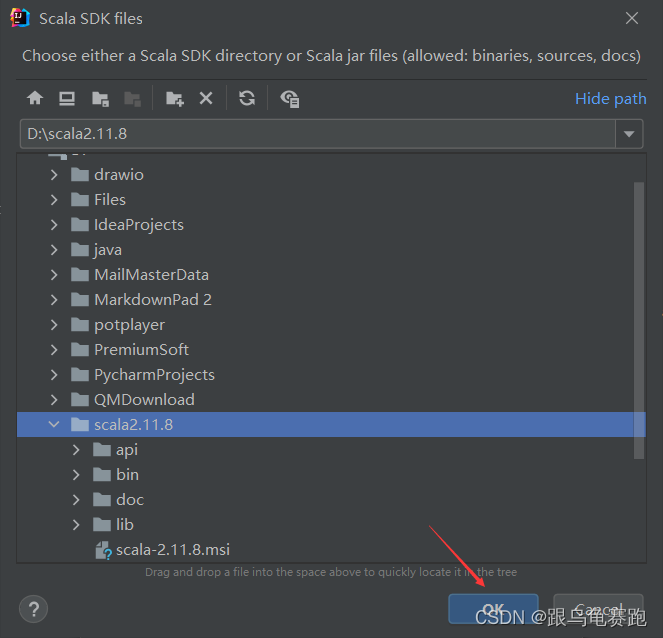
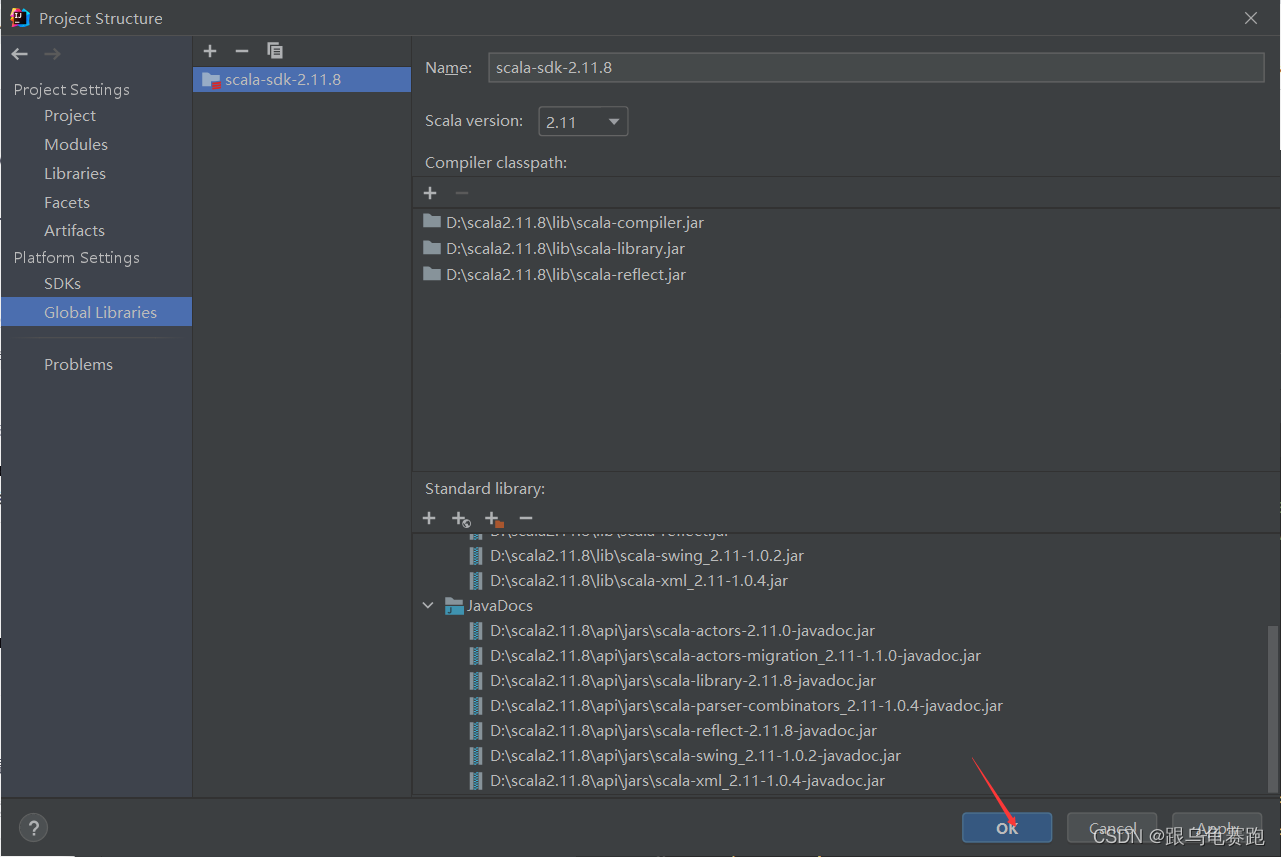
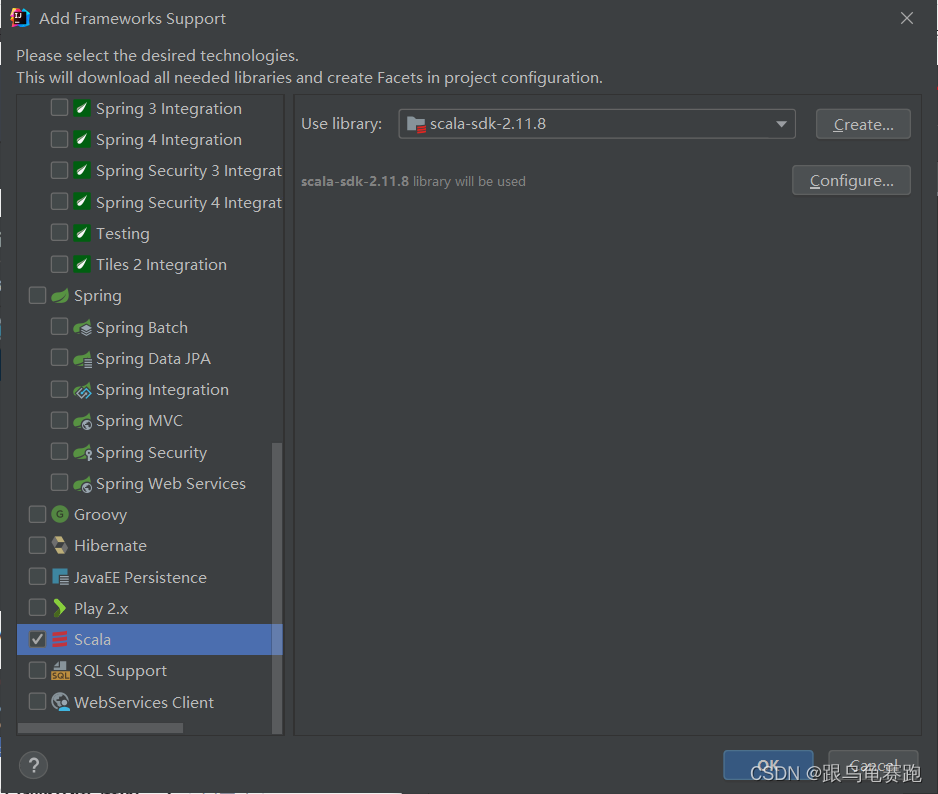
如果找不到Scala,查看IDEA安装完插件Scala后 通过add frameworks support找到不到scala插件
因为不是maven模式,因此,需要拿到spark相应的jar包spark-2.3.1-bin-hadoop2.6/jars
放置到项目下的lib文件夹中
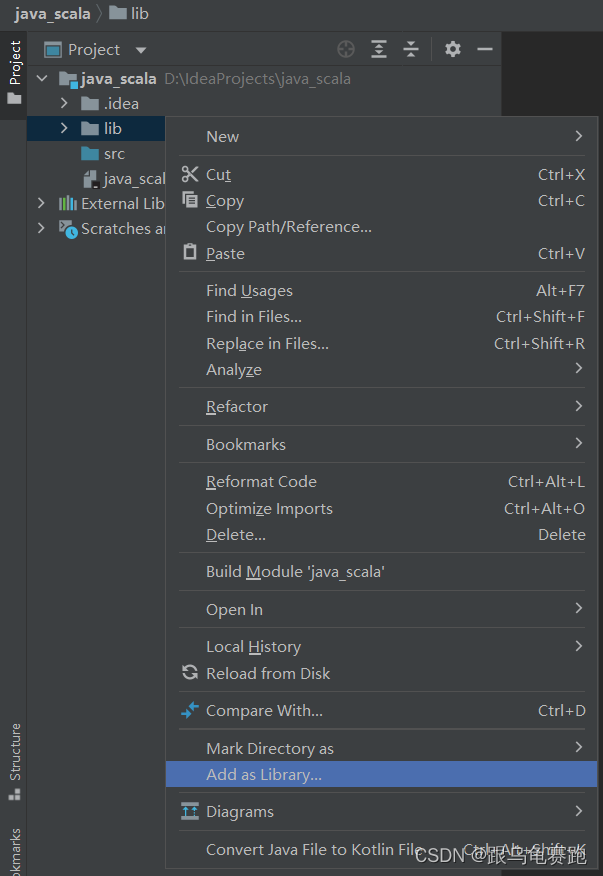
此时,会加载这些jar包

搞定!!!
5.开发第一个项目wordcount
Wordcount.scala:
package com.shsxt.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{
SPARK_BRANCH, SparkConf, SparkContext}
object Wordcount {
//主入口程序
def main(args: Array[String]): Unit = {
//1.创建sparkconf对象,针对此对象,配置改spark应用的配置信息
val conf = new SparkConf()
//setAppName:设置spark应用程序在运行时的任务名称
//setMaster:设置app的运行模式,本地模式设置为local即可
conf.setAppName("wordcount").setMaster("local")
//SparkContext是spark应用程序的所有入口
val sc = new SparkContext(conf)
//2.读取数据源文件
val line: RDD[String] = sc.textFile("data/word.txt")
//将数据分割并且一对多映射关系
val word: RDD[String] =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











