






主要目标
爬取下图信息,上图更简单直观。

分析思路
首先找到我们要得数据在那,我们先去站长之家去看看;站长之家

这里的“全部行业”就是我们要得一级分类,我们来研究一下他的html源代码,

然后随意点开一分类看看

html源码如下:
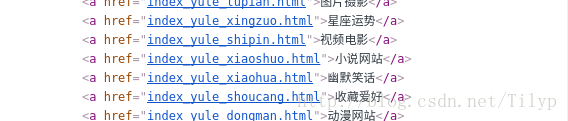
在点进去一个,我们就看到我们要得数据在哪里了;
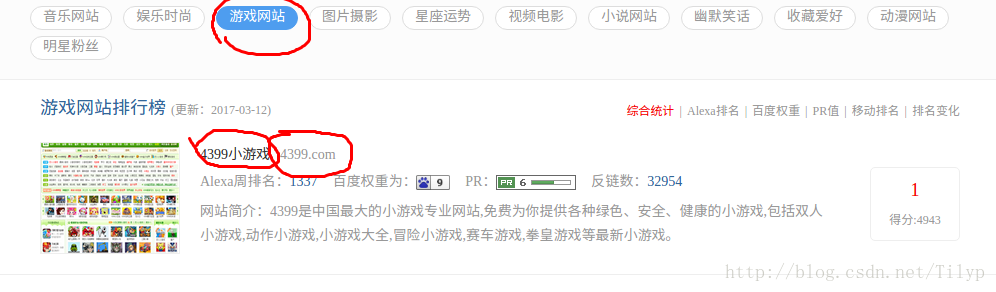
html内容如下:

我们看了这么多的东西有什么用呢?我总结出每级分类的url都可以在html源码里找的到,无须js,ajax等异步加载,那接下来我们看看如何分页的呢?

看到这张图我就知道这个二级分类下边有多少页内容了,但是为了保险起见,你们可以点到96页去验证,总页数得到了,我们来研究它如何分页的
这是首页url:http://top.chinaz.com/hangye/index_yule_youxi.html
这是第二页url:http://top.chinaz.com/hangye/index_yule_youxi_2.html
这是最后一页的url:http://top.chinaz.com/hangye/index_yule_youxi_96.html
因此我们可以构造“list” url,首页url唯一,不可构造
那么现在得到的结果就是这是一个很简单的list页爬取,无需处理异步,我们就来考虑要使用什么工具来抓取我们的数据了,由于这是一个很简单的应用,我们就用python2.7.12的urllib2库来抓取
代码如下:
#! -*- coding:utf-8 -*-
# __author__: andy
import random
import urllib2
import re
from time import sleep
import pymongo
from bs4 import BeautifulSoup
from agents.user_agents import agents
from filter import BloomFilter
class HangYe(object):
def __init__(self):
# 根url
self.root_url = "http://top.chinaz.com/hangye/"
# 实例化一个连接redis的包装类,有去重,此例未用去重
filter = BloomFilter()
self.rconn = filter.server
# 连接mongo库
client = pymongo.MongoClient("10.4.252.60", 27017)
# 如果mongo中有这个库就连接这个库,没有就创建这个库
db = client["hangye"]
# 创建表,原理同上
self.shop = db['chinaz']
def change_agents(self):
"""
设置use_agent,防止被墙,我这里有一个use_agents池,每次请求时随机从池取出一个添加到请求头里
:return:
"""
agent = random.choice(agents)
return agent
def base_request(self, url, flag):
"""
一个基本方法,传入url和一个标识符,每次请求时调用即可,
:param url:请求的url
:param flag:返回参数的标识符,为1时返回一级分类和它的url,为None时返回html内容
:return:
"""
request = urllib2.Request(url)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
# 设置设置use_agent,这里也可以设置其他header信息以json格式
opener.add_headers = [self.change_agents()]
response = opener.open(request).read()
# 这里使用BeautifulSoup来树化html,你们也可以用lxml,lxml速度快一点,因为etree是c写的
soup = BeautifulSoup(response, "lxml")
if flag == 1:
all_href = soup.find_all("div", class_="HeadFilter")[0].find_all("a")
top_list = []
for top_Category in all_href:
top_href = top_Category['href']
text_href = top_Category.get_text(strip=True)
top_list.append(top_href + "--" + text_href)
return top_list
if flag == None:
return soup
def top_category(self):
"""
此函数为了获取,二级分类和它的url,并和一级分类一起存入redis
:return:
"""
top_list = self.base_request(self.root_url, 1)
for hangye in top_list:
top_msg = hangye.split("--")
top_url = self.root_url + top_msg[0]
levels = self.base_request(top_url, 1)
for levels_msg in levels:
l = levels_msg.split("--")
line = l[0] + "--" + l[1] + "--" + top_msg[1]
print line
# 存数据
self.rconn.lpush("hangye:crawl", line)
def get_web_host(self):
# 取数据
msg = self.rconn.lpop("hangye:crawl")
top_msg = msg.split("--")
href_url = top_msg[0]
# 构造 请求url
levels_url = self.root_url + href_url
html = self.base_request(levels_url, None)
len = html.find_all("div", class_="ListPageWrap")[0].find_all("a")
# 抓取此二级分类下有多少页信息
len_page = re.findall(r"\d+", len[-2].get_text(strip=True))[0]
l = 1
while l <= int(len_page):
# 判断是否是第一页,已经请求过就直接分析
if l == 1:
html_msg = html
else:
index_url = href_url.split(".")[0] + "_" + str(l) + ".html"
levels_url = self.root_url + index_url
print levels_url
# 请求数据,并设置flag
html_msg = self.base_request(levels_url, None)
web_host = html_msg.find_all("ul", class_="listCentent")[0].find_all("h3", class_="rightTxtHead")
Chinaz = {}
Chinaz['top_category'] = top_msg[2]
Chinaz['level_category'] = top_msg[1]
for hd in web_host:
web_name = hd.find_all("a")[0].get_text(strip=True)
domain = hd.find_all("span")[0].get_text(strip=True)
Chinaz['web_name'] = web_name
Chinaz['domain'] = domain
# 抓取结果存入mongo
if Chinaz:
self.shop.insert(Chinaz, manipulate=False)
# 将抓取过的url存入redis,方便统计。
self.rconn.lpush("hangye:success", levels_url)
print levels_url + "|||" + "Request Successlly !!!"
l += 1
try:
hang = HangYe()
hang.top_category()
# 读取待爬队列中有多少url
len = hang.rconn.llen("hangye:crawl")
while len > 0:
sleep(1)
hang.get_web_host()
len = len -1
# 读取总共抓取了多少url
success = hang.rconn.llen("hangye:success")
print "Crawl success Total %s pages" % success
except (KeyboardInterrupt, SystemExit):
print "程序意外终止"代码该讲的已经写在注释里了,我就不罗嗦了;我们就让它跑起来吧!

大概不到半个小时就跑完了,这是跑下来的总数据

这里是我的github地址,代码随便写的,如有失误请多多指教!!!
有时间会继续更新爬虫的,如异步加载的处理,phantomjs和selenium的使用,scrapy + splash以及scrapy大型集群的搭建和使用,欢迎大家来指正和谈论。














 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









