







站长素材免费简历模板的url:https://sc.chinaz.com/jianli/free.html
开始前先说一下爬虫思路,requests和xpath简单的使用方法):
先打开网页
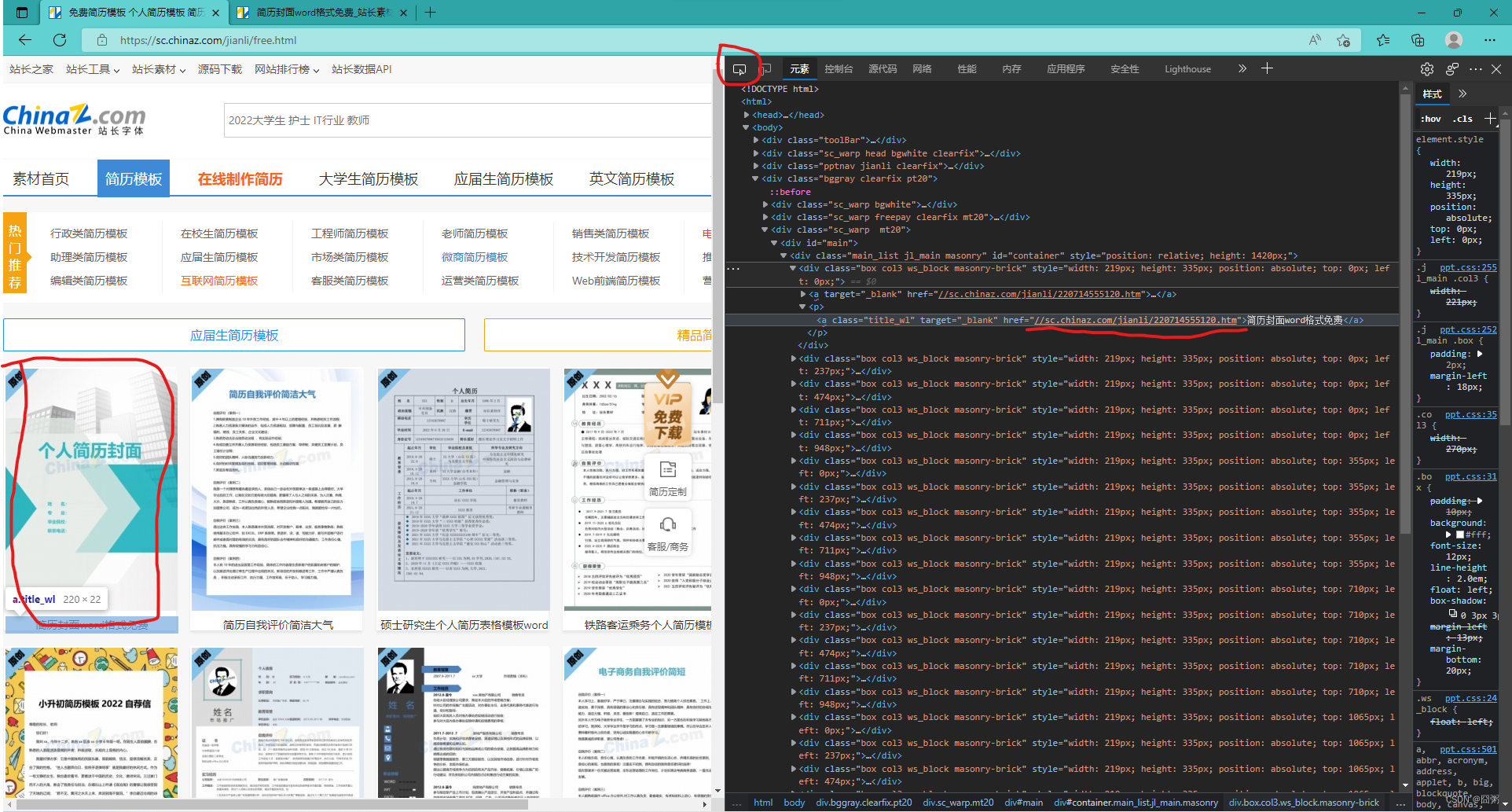
(分析)按F12,然后点击左上角的检查功能并随便点一个模板,里面<p>的href就是这个模板的下载页面的url(本页面我们需要爬取的)
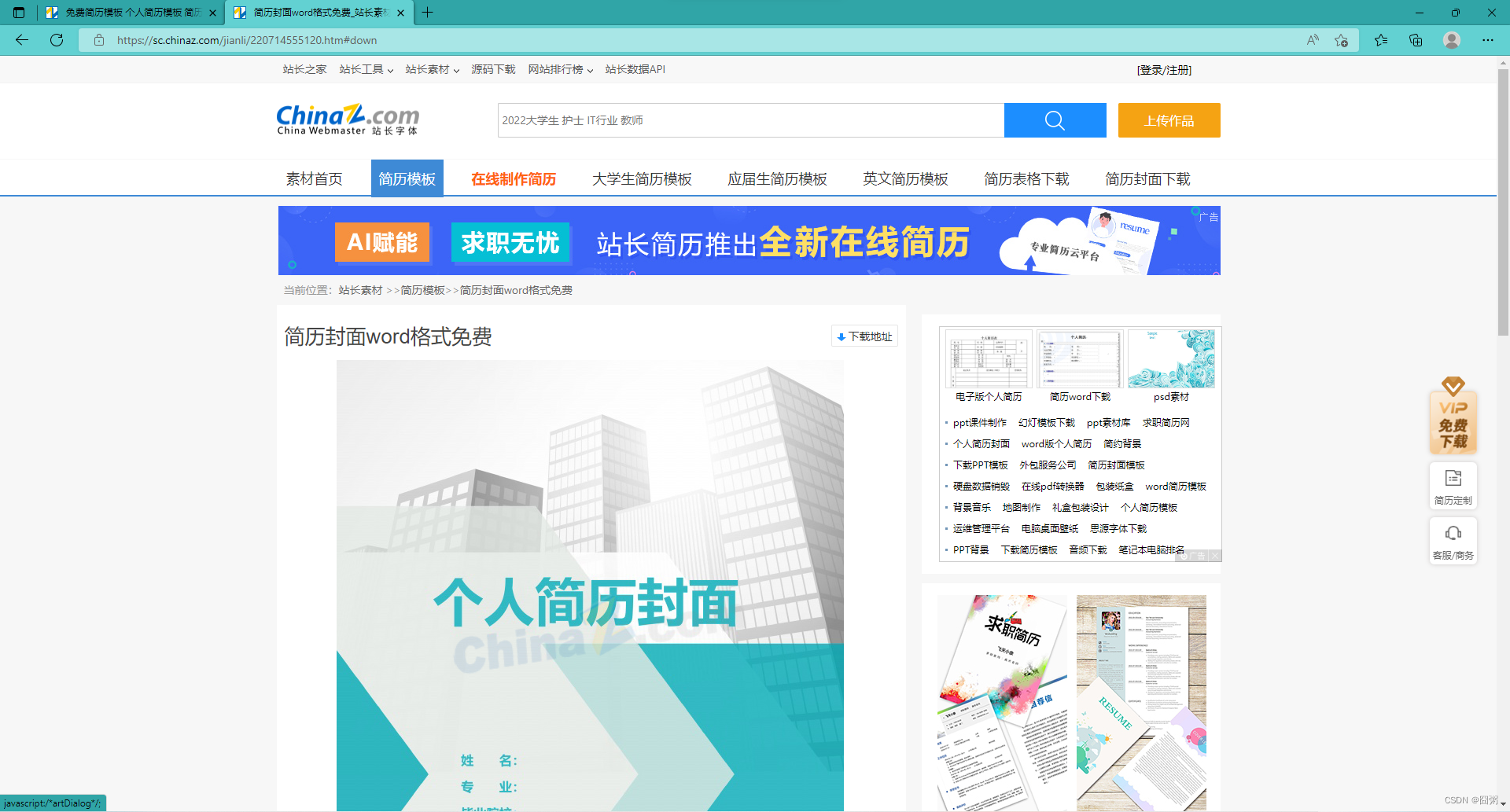
然后点击任意一个模板,他会跳转到下载页面:
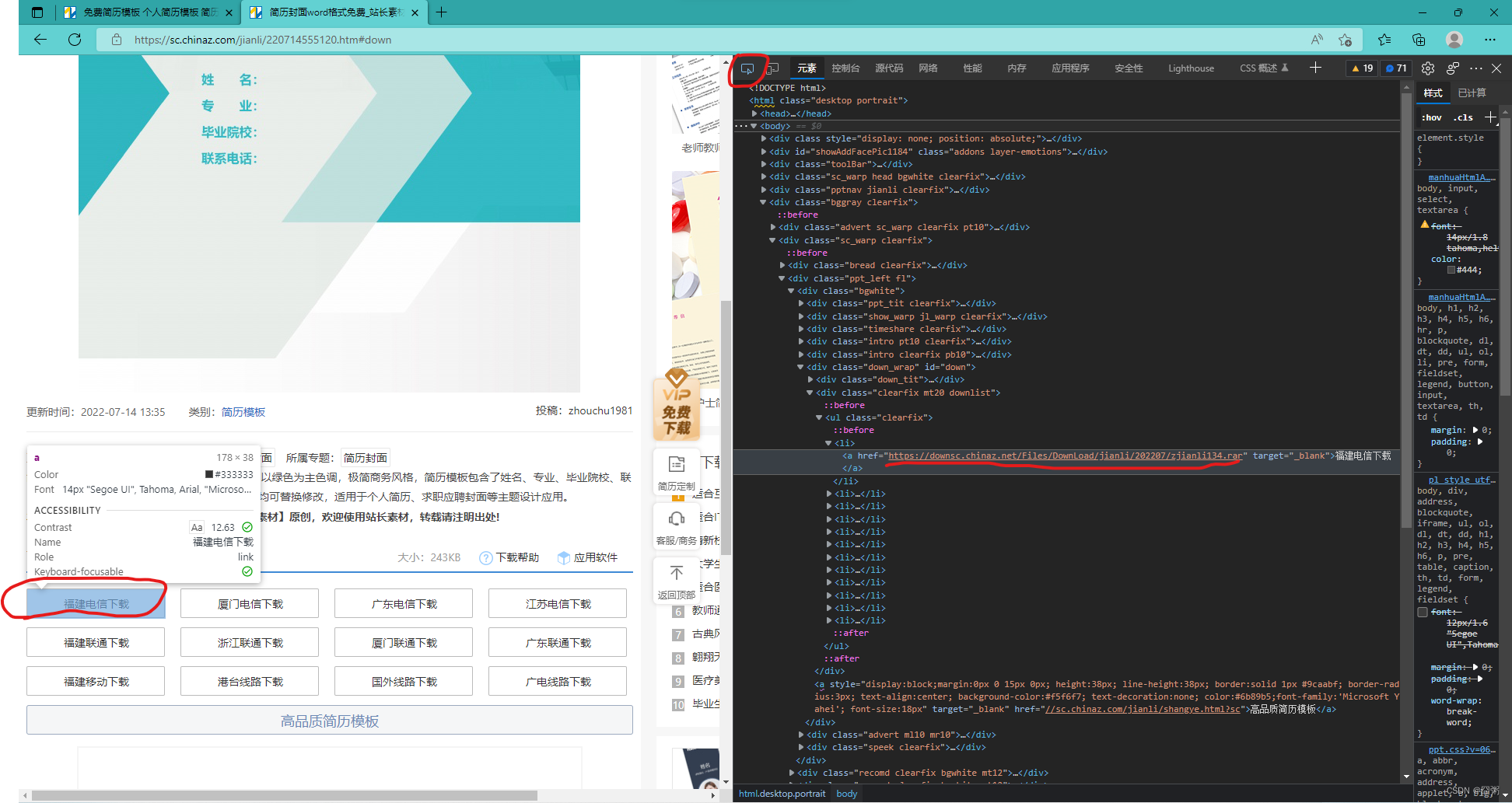
(分析)进入下载页面后往下拉就能看到下载地址,接下来就跟上面分析的一样(爬到这里的url就可以下载了)
requests和下xpath的简单使用:
要爬取上面提到的url,就得先用requests爬整个页面的源码然后再通过xpath筛选出url
页面源码 = requests.get(url='所处页面的url').text
选择要进行筛选的代码 = etree.HTML('页面源码')
选择要进行筛选的代码.xpath('进行筛选')
简单说一下xpath里面筛选的语法:
例子://div[@id="a1"]//img/@href
说明:筛选由ID为‘a1’的div开始下面任意层的img里的href属性
/:下一层 //:下任意层
@:属性前面需要加这个
!xpath返回的结果都是列表O
最后是代码:
#导入库
import requests
import os
from lxml import etree
#创建文件夹,方便等一下存储数据
if not os.path.exists('./结果'):
os.mkdir('./结果')
#--------------------------------------------------第一个页面
begin_url = 'https://sc.chinaz.com/jianli/free.html'#指定开始页面的url
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
begin_text = requests.get(url=begin_url, headers=header).text#发起请求获取页面源码
begin_tree = etree.HTML(begin_text)#选择要筛选的代码
begin_href_list = begin_tree.xpath('//div[@id="main"]//p/a/@href')#对选择的代码进行筛选,选出每个简历的下载页面的url
#--------------------------------------------------第二个页面
#xpath返回的都是列表,需要用循环把筛选到的url一个个给他提出来再一个个发起请求
during_href_list = []
for during_url in begin_href_list:
during_url = 'https:'+during_url#因为筛选出的url少了“https:”,所以给他补上
during_text = requests.get(url=during_url, headers=header).text#重复上面获取源码的操作
during_tree = etree.HTML(during_text)
during_href = during_tree.xpath('//div[@id="down"]//ul//a[1]/@href')[0]#前面说了xpath返回的都是列表,如果不提出来等一下将返回很多列表
during_href_list.append(during_href)#然后加到前面创好的列表里
#--------------------------------------------------下载
#和上面一样的思路
for end_url in during_href_list:
end_content = requests.get(url=end_url, headers=header).t#这里爬到的是压缩包,要是用“conten”
#下面是存储爬到的数据
end_name = end_url.split('/')[-1]#文件名
end_path = './结果/'+end_name#文件路径
with open(end_path, 'wb') as o:#打开并存储
o.write(end_content)
print(end_name+'下载完成')
















 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











