







标签(空格分隔): Python selenium
前言
近来都在与新浪这个大佬在pk。首先是网页爬取新浪微博,遇到的难题是cookie的存活期太慢,一般爬十分钟就over了一个;后来发明了手机版的模拟登录,顺风顺水了一段时间,结果新浪又来一个验证码,被气得半死。无奈手动输入验证码后,再模拟登录。然而不过两个月,新浪哥又开始抓严,搞得手机版的模拟登陆经常登陆不上去。最后实在无办法了,只好真的去“模拟”浏览器实现爬虫了。说道浏览器自动化操作,目前最好用的就是selenium啦。
关于selenium
Selenium原本是一个用于Web应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。它支持的浏览器包括IE,Chrome和Firefox等。现在很多虫师为了绕过反爬虫的机制,都选择selenium。由于selenium的原理是唤起浏览器操作,因而代价就是爬虫的非常慢。
selenium的安装
我的机子是Ubuntu,所以下面主要是总结我在Ubuntu安装的过程。
1. 输入安装命令行
sudo pip install -U selenium 2.下载驱动器geckodriver
(百度网盘的下载链接http://pan.baidu.com/s/1sk9Rw3z)
3.更新浏览器
如FireFox:
sudo apt-get update –> sudo apt-get install firefox4.selenium的测试代码
from selenium import webdriver
browser = webdriver.Firefox(executable_path='/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径(路径为geckodriver的存放路径)
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
print browser.page_source ## 输入返回的源代码PS:在我测试的时候它告诉我配置文件路径错了,那这该如何是好?
这个时候我将我的geckodriver放到另外一个地方:
sudo cp /home/totoro/codes/PycharmProjects/Weibo/geckodriver /usr/local/bin/geckodriver然后进入存放目录查看情况:
cd /usr/local/binls -l由于默认权限不是777,所以对其进行更改
sudo chmod 777 geckodriver最后就可以看到geckodriver呈现绿色了
selenium的测试结果
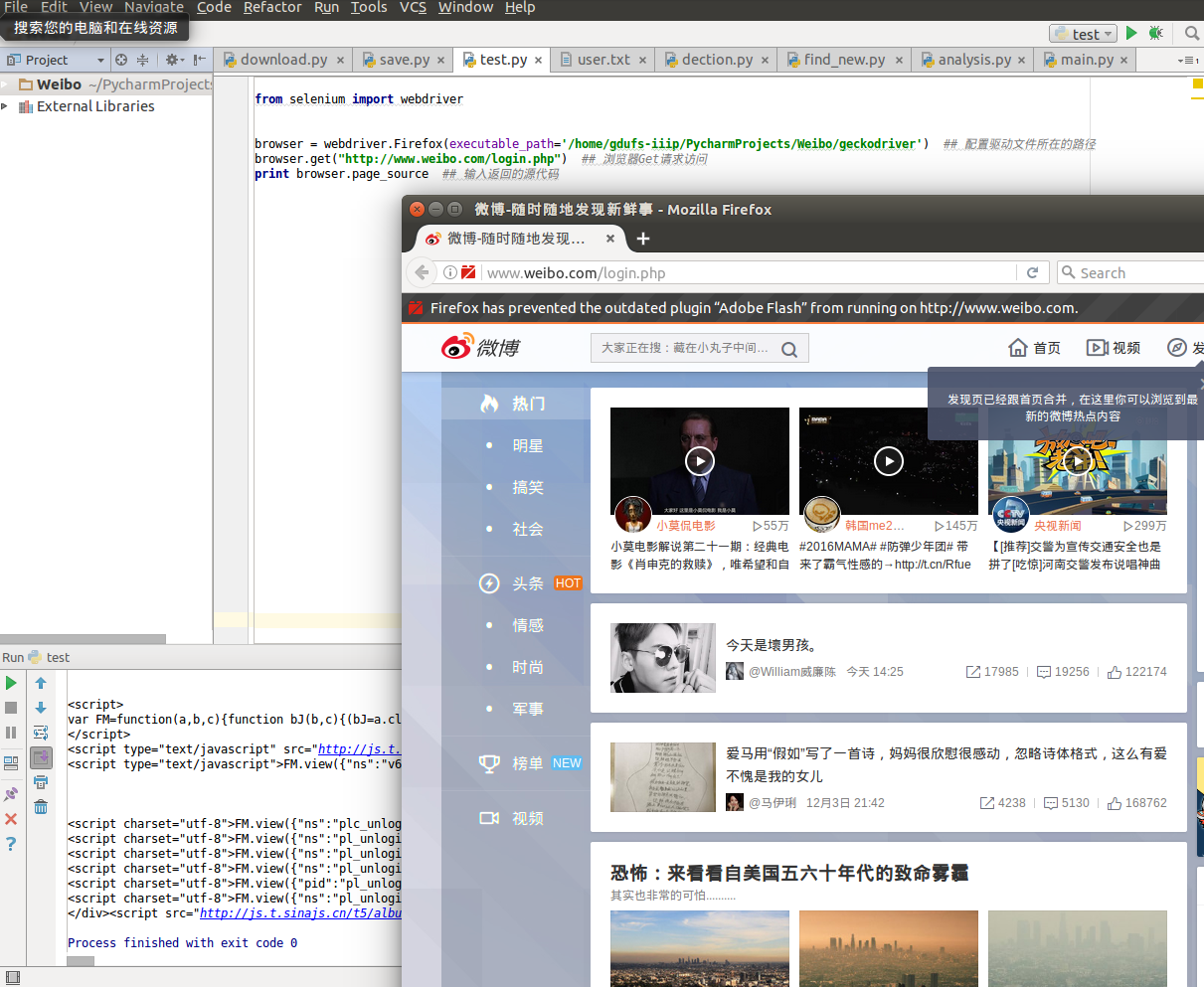
模拟登录过程
selenium开启的浏览器,但用户可以当这个浏览器正常使用。所以模拟登录的过程,其实就是程序设置休眠时间,让用户输入账号密码并完成登陆操作后,再实行网页抓取。具体的代码如下:
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
begin_time = time.time() ##记录开始账号密码的时间
while(True):
if ((time.time() - begin_time) > 60): ## 实现登录的时限为60秒
search_url = 'http://weibo.cn/search/mblog?hideSearchFrame=&keyword=林丹出轨&sort=hot&page=1' ##实行新闻网页抓取
browser.get(search_url)
content = browser.page_source
break
print content













 8430
8430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









