







1.join
表连接:
(1) 两个表m,n之间按照on条件连接,m中的一条记录和n中的一条记录组成一条新记录
(2)join 等值连接,只有某个值在m和n中同时存在时
(3)left outer join 左外连接,左边表中的值无论是否在右表中存在时,都输出,右边表中的值只有在左边表中存在时才输出
(4)right outer join 和left outer join 相反
(5)left semi join 类似exists
(6)mapjoin 在map端完成join操作,不需要用reduce,基于内存做join,属于优化操作
1-5的查含义和sql几乎是差不多的:
join的mr执行图:
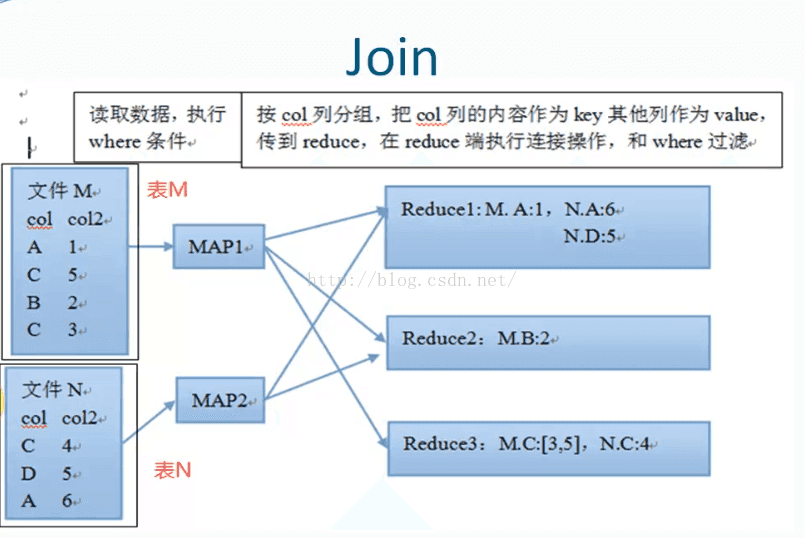
样例:
select m.col as col ,m.col2 as col2,n.col3 as cols
from
(select col,col2 from test where ...(map端执行)) m (左表)
[left outer|right outer|left semi] join
n(右表)
on m.col=n.col
where condition (reduce 端执行)
set hive.optimize.skewjoin=true;(优化操作 对join进行优化 如果可能出现数据倾斜 可以加上)
2.Mapjoin
(1) mapjoin (map side join)
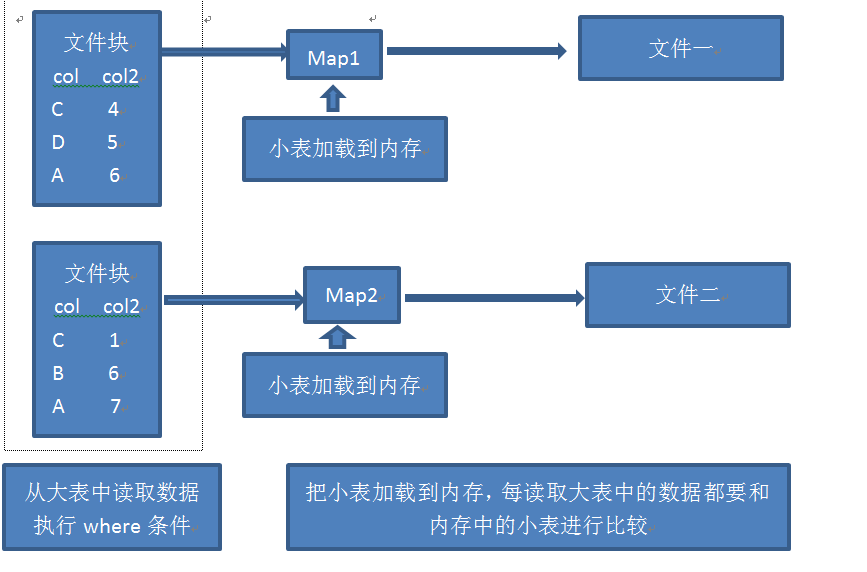
在map端把小表加载到内存中,然后读取大表,和内存中的小表完成连接操作
其中使用了分布式缓存技术
优缺点
不消耗集群的reduce资源(reduce相对紧缺)
减少了reduce操作,加快程序执行
降低网络负载
占用部分内存,所以加载到内存中的表不能过大,因为每个计算节点都会加载一次
生成较多的小文件
mapjoin 执行原理图:
配置以下参数,是hive自动根据sql,选择使用common join 或者 map join
set hive.auto.convert.join=true 如果设置它 他会把小于等于25mb的表加入内存
hive.mapjoin.smalltable.filesize 默认值是25mb
第二种方式,手动指定
select /*+mapjoin(n)*/ m.col,m.col2,n.col3 from m join n on m.col=n.col
简单总结一下,mapjoin的使用场景
1.关联操作中有一张表非常小
2.不等值的链接操作















 5185
5185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









