







1.transformation和action介绍
1.Spark支持两种RDD操作:transformation和action。transformation操作会针对已有的RDD创建一个新的RDD;而action则主要是对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并可以返回结果给Driver程序。例如,map就是一种transformation操作,它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有的新元素组成一个新的RDD。而reduce就是一种action操作,它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。
2.transformation的特点就是lazy特性。lazy特性指的是,如果一个spark应用中只定义了transformation操作,那么即使你执行该应用,这些操作也不会执行。也就是说,transformation是不会触发spark程序的执行的,它们只是记录了对RDD所做的操作,但是不会自发的执行。只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。Spark通过这种lazy特性,来进行底层的spark应用执行的优化,避免产生过多中间结果。
3.action操作执行,会触发一个sparkjob的运行,从而触发这个action之前所有的transformation的执行。这是action的特性。
2.案例:统计文件字数
1通过案例“统计文件字数”,来讲解transformation和action:
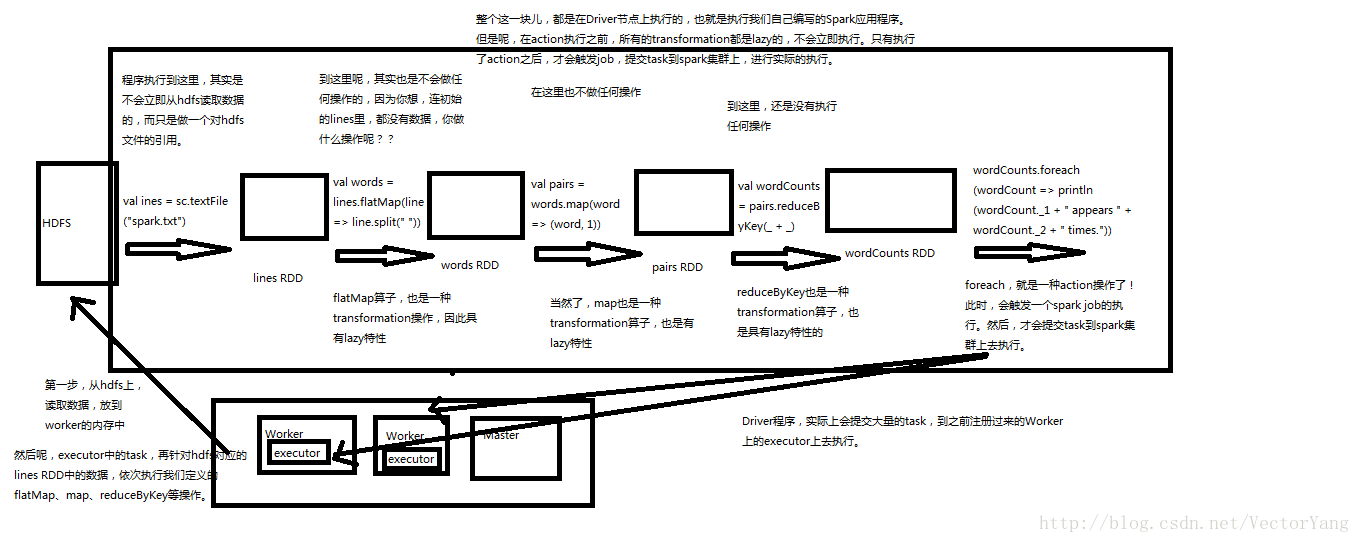
// 这里通过textFile()方法,针对外部文件创建了一个RDD,lines,但是实际上,程序执行到这里为止,spark.txt文件的数据是不会加载到内存中的。lines,只是代表了一个指向spark.txt文件的引用。
val lines = sc.textFile(“spark.txt”)
// 这里对lines RDD进行了map算子,获取了一个转换后的lineLengths RDD。但是这里连数据都没有,当然也不会做任何操作。lineLengths RDD也只是一个概念上的东西而已。
val lineLengths = lines.map(line => line.length)
// 之列,执行了一个action操作,reduce。此时就会触发之前所有transformation操作的执行,Spark会将操作拆分成多个task到多个机器上并行执行,每个task会在本地执行map操作,并且进行本地的reduce聚合。最后会进行一个全局的reduce聚合,然后将结果返回给Driver程序。
val totalLength = lineLengths.reduce(_ + _)
2.通过图片详解:
3.常用transformation介绍
1.map:将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD。
案例:将集合中每一个元素都乘以2
Java版:
// 构造集合
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers);
// 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(
new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L;
// 传入call()方法的,就是1,2,3,4,5
// 返回的就是2,4,6,8,10
@Override
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
});
// 打印新的RDD
multipleNumberRDD.foreach(new VoidFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
});
Scala版:
val numbers = Array(1, 2, 3, 4, 5)
val numberRDD = sc.parallelize(numbers, 1)
val multipleNumberRDD = numberRDD.map { num => num * 2 }
multipleNumberRDD.foreach { num => println(num) }
结果:

2.filter:对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除。
案例:过滤集合中的偶数
Java版:
// 模拟集合
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers);
// 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false
JavaRDD<Integer> evenNumberRDD = numberRDD.filter(
new Function<Integer, Boolean>() {
private static final long serialVersionUID = 1L;
// 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
// 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
});
Scala版:
val numbers = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val numberRDD = sc.parallelize(numbers, 1)
val evenNumberRDD = numberRDD.filter { num => num % 2 == 0 }
evenNumberRDD.foreach { num => println(num) }
结果:

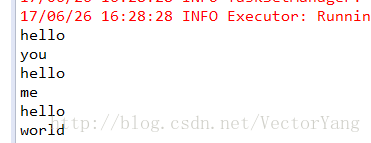
3.flatMap:与map类似,但是对每个元素都可以返回一个或多个新元素。
案例:将文本行拆分为多个单词
Java版:
// 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world");
// 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList);
// 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,返回可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
// 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
Scala版:
val lineArray = Array("hello you", "hello me", "hello world")
val lines = sc.parallelize(lineArray, 1)
val words = lines.flatMap { line => line.split(" ") }
words.foreach { word => println(word) }
结果:
4.gropuByKey:根据key进行分组,每个key对应一个Iterable。
案例:按照班级对成绩进行分组
Java版:
// 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", 80),
new Tuple2<String, Integer>("class2", 75),
new Tuple2<String, Integer>("class1", 90),
new Tuple2<String, Integer>("class2", 65));
// 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList);
// 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
// groupByKey算子,返回的还是JavaPairRDD
// 但是,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型
// 也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 那么接下来,我们是不是就可以通过groupedScores这种JavaPairRDD,很方便地处理某个分组内的数据
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey();
// 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Iterable<Integer>> t)
throws Exception {
System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
}
});
Scala版:
val scoreList = Array(Tuple2("class1", 80), Tuple2("class2", 75),
Tuple2("class1", 90), Tuple2("class2", 60))
val scores = sc.parallelize(scoreList, 1)
val groupedScores = scores.groupByKey()
groupedScores.foreach(score => {
println(score._1);
score._2.foreach { singleScore => println(singleScore) };
println("=============================")
})
结果:

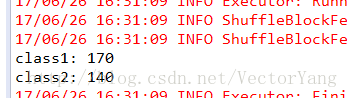
5.reduceByKey:对每个key对应的value进行reduce操作。
案例:统计每个班级的总分
Java版:
// 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", 80),
new Tuple2<String, Integer>("class2", 75),
new Tuple2<String, Integer>("class1", 90),
new Tuple2<String, Integer>("class2", 65));
// 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList);
// 针对scores RDD,执行reduceByKey算子
// reduceByKey,接收的参数是Function2类型,它有三个泛型参数,实际上代表了三个值
// 第一个泛型类型和第二个泛型类型,代表了原始RDD中的元素的value的类型
// 因此对每个key进行reduce,都会依次将第一个、第二个value传入,将值再与第三个value传入
// 因此此处,会自动定义两个泛型类型,代表call()方法的两个传入参数的类型
// 第三个泛型类型,代表了每次reduce操作返回的值的类型,默认也是与原始RDD的value类型相同的
// reduceByKey算法返回的RDD,还是JavaPairRDD<key, value>
JavaPairRDD<String, Integer> totalScores = scores.reduceByKey(
new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
// 对每个key,都会将其value,依次传入call方法
// 从而聚合出每个key对应的一个value
// 然后,将每个key对应的一个value,组合成一个Tuple2,作为新RDD的元素
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
// 打印totalScores RDD
totalScores.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
}
});
Scala版:
val scoreList = Array(Tuple2("class1", 80), Tuple2("class2", 75),
Tuple2("class1", 90), Tuple2("class2", 60))
val scores = sc.parallelize(scoreList, 1)
val totalScores = scores.reduceByKey(_ + _)
totalScores.foreach(classScore => println(classScore._1 + ": " + classScore._2))
结果:
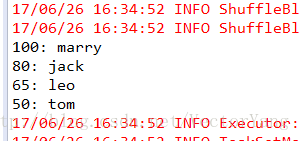
6.sortByKey:对每个key对应的value进行排序操作。
案例:按照学生分数进行排序
Java版:
// 模拟集合
List<Tuple2<Integer, String>> scoreList = Arrays.asList(
new Tuple2<Integer, String>(65, "leo"),
new Tuple2<Integer, String>(50, "tom"),
new Tuple2<Integer, String>(100, "marry"),
new Tuple2<Integer, String>(80, "jack"));
// 并行化集合,创建RDD
JavaPairRDD<Integer, String> scores = sc.parallelizePairs(scoreList);
// 对scores RDD执行sortByKey算子
// sortByKey其实就是根据key进行排序,可以手动指定升序,或者降序
// 返回的,还是JavaPairRDD,其中的元素内容,都是和原始的RDD一模一样的
// 但是就是RDD中的元素的顺序,不同了
JavaPairRDD<Integer, String> sortedScores = scores.sortByKey(false);
// 打印sortedScored RDD
sortedScores.foreach(new VoidFunction<Tuple2<Integer,String>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<Integer, String> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
}
});
Scala版:
val scoreList = Array(Tuple2(65, "leo"), Tuple2(50, "tom"),
Tuple2(100, "marry"), Tuple2(85, "jack"))
val scores = sc.parallelize(scoreList, 1)
val sortedScores = scores.sortByKey(false)
sortedScores.foreach(studentScore => println(studentScore._1 + ": " + studentScore._2))
结果:
7.join:对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理。
案例:打印学生成绩
Java版:
// 模拟集合
List<Tuple2<Integer, String>> studentList = Arrays.asList(
new Tuple2<Integer, String>(1, "leo"),
new Tuple2<Integer, String>(2, "jack"),
new Tuple2<Integer, String>(3, "tom"));
List<Tuple2<Integer, Integer>> scoreList = Arrays.asList(
new Tuple2<Integer, Integer>(1, 100),
new Tuple2<Integer, Integer>(2, 90),
new Tuple2<Integer, Integer>(3, 60));
// 并行化两个RDD
JavaPairRDD<Integer, String> students = sc.parallelizePairs(studentList);
JavaPairRDD<Integer, Integer> scores = sc.parallelizePairs(scoreList);
// 使用join算子关联两个RDD
// join以后,还是会根据key进行join,并返回JavaPairRDD
// 但是JavaPairRDD的第一个泛型类型,之前两个JavaPairRDD的key的类型,因为是通过key进行join的
// 第二个泛型类型,是Tuple2<v1, v2>的类型,Tuple2的两个泛型分别为原始RDD的value的类型
// join,就返回的RDD的每一个元素,就是通过key join上的一个pair
// 什么意思呢?比如有(1, 1) (1, 2) (1, 3)的一个RDD
// 还有一个(1, 4) (2, 1) (2, 2)的一个RDD
// join以后,实际上会得到(1 (1, 4)) (1, (2, 4)) (1, (3, 4))
JavaPairRDD<Integer, Tuple2<String, Integer>> studentScores = students.join(scores);
// 打印studnetScores RDD
studentScores.foreach(
new VoidFunction<Tuple2<Integer,Tuple2<String,Integer>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> t)
throws Exception {
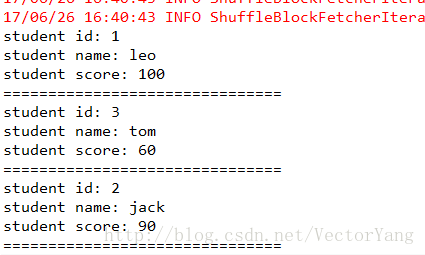
System.out.println("student id: " + t._1);
System.out.println("student name: " + t._2._1);
System.out.println("student score: " + t._2._2);
System.out.println("===============================");
}
});
Scala版:
val studentList = Array(
Tuple2(1, “leo”),
Tuple2(2, “jack”),
Tuple2(3, “tom”));
val scoreList = Array(
Tuple2(1, 100),
Tuple2(2, 90),
Tuple2(3, 60));
val students = sc.parallelize(studentList);
val scores = sc.parallelize(scoreList);
val studentScores = students.join(scores)
studentScores.foreach(studentScore => {
println("student id: " + studentScore._1);
println("student name: " + studentScore._2._1)
println("student socre: " + studentScore._2._2)
println("=======================================")
})
结果:
8.cogroup:同join,但是是每个key对应的Iterable都会传入自定义函数进行处理。
案例:打印学生成绩
Java版:
// 模拟集合
List<Tuple2<Integer, String>> studentList = Arrays.asList(
new Tuple2<Integer, String>(1, "leo"),
new Tuple2<Integer, String>(2, "jack"),
new Tuple2<Integer, String>(3, "tom"));
List<Tuple2<Integer, Integer>> scoreList = Arrays.asList(
new Tuple2<Integer, Integer>(1, 100),
new Tuple2<Integer, Integer>(2, 90),
new Tuple2<Integer, Integer>(3, 60),
new Tuple2<Integer, Integer>(1, 70),
new Tuple2<Integer, Integer>(2, 80),
new Tuple2<Integer, Integer>(3, 50));
// 并行化两个RDD
JavaPairRDD<Integer, String> students = sc.parallelizePairs(studentList);
JavaPairRDD<Integer, Integer> scores = sc.parallelizePairs(scoreList);
// cogroup与join不同
// 相当于是,一个key join上的所有value,都给放到一个Iterable里面去了
// cogroup,不太好讲解,希望大家通过动手编写我们的案例,仔细体会其中的奥妙
JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> studentScores =
students.cogroup(scores);
// 打印studnetScores RDD
studentScores.foreach(
new VoidFunction<Tuple2<Integer,Tuple2<Iterable<String>,Iterable<Integer>>>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(
Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> t)
throws Exception {
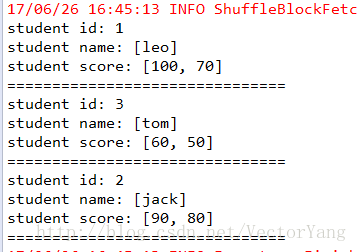
System.out.println("student id: " + t._1);
System.out.println("student name: " + t._2._1);
System.out.println("student score: " + t._2._2);
System.out.println("===============================");
}
});
Scala版:
val studentList = Array(
Tuple2(1, “leo”),
Tuple2(2, “jack”),
Tuple2(3, “tom”));
val scoreList = Array(
Tuple2(1, 100),
Tuple2(2, 90),
Tuple2(3, 60));
val students = sc.parallelize(studentList);
val scores = sc.parallelize(scoreList);
val studentScores = students.cogroup(scores)
studentScores.foreach(studentScore => {
println("student id: " + studentScore._1);
println("student name: " + studentScore._2._1)
println("student socre: " + studentScore._2._2)
println("=======================================")
})
结果:
4.常用action介绍
1.reduce:将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。
案例:10个数字进行累加
Java版:
// 有一个集合,里面有1到10,10个数字,现在要对10个数字进行累加
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD numbers = sc.parallelize(numberList);
// 使用reduce操作对集合中的数字进行累加
// reduce操作的原理:
// 首先将第一个和第二个元素,传入call()方法,进行计算,会获取一个结果,比如1 + 2 = 3
// 接着将该结果与下一个元素传入call()方法,进行计算,比如3 + 3 = 6
// 以此类推
// 所以reduce操作的本质,就是聚合,将多个元素聚合成一个元素
int sum = numbers.reduce(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
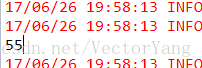
System.out.println(sum);
Scala版:
val numberArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val numbers = sc.parallelize(numberArray, 1)
val sum = numbers.reduce(_ + _)
结果:
2.collect:将RDD中所有元素获取到本地客户端。
案例:数字的两倍
Java版:
// 有一个集合,里面有1到10,10个数字,现在要对10个数字进行累加
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> numbers = sc.parallelize(numberList);
// 使用map操作将集合中所有数字乘以2
JavaRDD<Integer> doubleNumbers = numbers.map(
new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
});
// 不用foreach action操作,在远程集群上遍历rdd中的元素
// 而使用collect操作,将分布在远程集群上的doubleNumbers RDD的数据拉取到本地
// 这种方式,一般不建议使用,因为如果rdd中的数据量比较大的话,比如超过1万条
// 那么性能会比较差,因为要从远程走大量的网络传输,将数据获取到本地
// 此外,除了性能差,还可能在rdd中数据量特别大的情况下,发生oom异常,内存溢出
// 因此,通常,还是推荐使用foreach action操作,来对最终的rdd元素进行处理
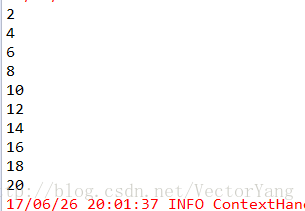
List<Integer> doubleNumberList = doubleNumbers.collect();
for(Integer num : doubleNumberList) {
System.out.println(num);
}
Scala版:
val numberArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val numbers = sc.parallelize(numberArray, 1)
val doubleNumbers = numbers.map { num => num * 2 }
val doubleNumberArray = doubleNumbers.collect()
for(num <- doubleNumberArray) {
println(num)
}
结果:
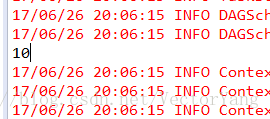
3.count:获取RDD元素总数。
案例:一串数字的个数。
Java版:
// 有一个集合,里面有1到10,10个数字,现在要对10个数字进行累加
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> numbers = sc.parallelize(numberList);
// 对rdd使用count操作,统计它有多少个元素
long count = numbers.count();
System.out.println(count);
Scala版:
val numberArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val numbers = sc.parallelize(numberArray, 1)
val count = numbers.count()
结果:
4.saveAsTextFile:将RDD元素保存到文件中,对每个元素调用toString方法。
案例:把数据保存到HDFS中
Java版:
// 有一个集合,里面有1到10,10个数字,现在要对10个数字进行累加
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> numbers = sc.parallelize(numberList);
// 使用map操作将集合中所有数字乘以2
JavaRDD<Integer> doubleNumbers = numbers.map(
new Function<Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
});
// 直接将rdd中的数据,保存在HFDS文件中
// 但是要注意,我们这里只能指定文件夹,也就是目录
// 那么实际上,会保存为目录中的/double_number.txt/part-00000文件
doubleNumbers.saveAsTextFile("hdfs://spark1:9000/double_number.txt");
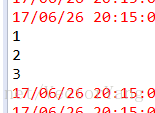
5.take:获取RDD中前n个元素。
案例:获取一个RDD的前三个元素
Java版:
// 有一个集合,里面有1到10,10个数字,现在要对10个数字进行累加
List<Integer> numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD<Integer> numbers = sc.parallelize(numberList);
// 对rdd使用count操作,统计它有多少个元素
// take操作,与collect类似,也是从远程集群上,获取rdd的数据
// 但是collect是获取rdd的所有数据,take只是获取前n个数据
List<Integer> top3Numbers = numbers.take(3);
for(Integer num : top3Numbers) {
System.out.println(num);
}
Scala版:
val numberArray = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val numbers = sc.parallelize(numberArray, 1)
val top3Numbers = numbers.take(3)
for(num <- top3Numbers) {
println(num)
}
结果:
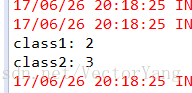
6.countByKey:对每个key对应的值进行count计数。
案例:统计每个班级的学生人数
Java版:
// 模拟集合
List<Tuple2<String, String>> scoreList = Arrays.asList(
new Tuple2<String, String>("class1", "leo"),
new Tuple2<String, String>("class2", "jack"),
new Tuple2<String, String>("class1", "marry"),
new Tuple2<String, String>("class2", "tom"),
new Tuple2<String, String>("class2", "david"));
// 并行化集合,创建JavaPairRDD
JavaPairRDD<String, String> students = sc.parallelizePairs(scoreList);
// 对rdd应用countByKey操作,统计每个班级的学生人数,也就是统计每个key对应的元素个数
// 这就是countByKey的作用
// countByKey返回的类型,直接就是Map<String, Object>
Map<String, Object> studentCounts = students.countByKey();
for(Map.Entry<String, Object> studentCount : studentCounts.entrySet()) {
System.out.println(studentCount.getKey() + ": " + studentCount.getValue());
}
Scala版:
val studentList = Array(Tuple2("class1", "leo"), Tuple2("class2", "jack"),
Tuple2("class1", "tom"), Tuple2("class2", "jen"), Tuple2("class2", "marry"))
val students = sc.parallelize(studentList, 1)
val studentCounts = students.countByKey()
结果:
7.foreach:遍历RDD中的每个元素。(最常用的action)














 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









