







第5章:RDD 
5.1 RDD
5.1.1 什么是 RDD
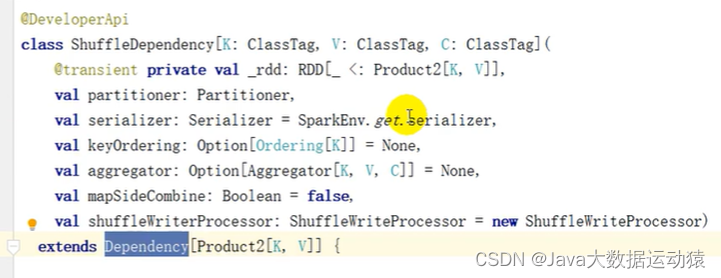
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据
处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行
计算的集合。
➢弹性
⚫存储的弹性:内存与磁盘的自动切换;
⚫容错的弹性:数据丢失可以自动恢复;
⚫计算的弹性:计算出错重试机制;
⚫分片的弹性:可根据需要重新分片。
➢分布式:数据存储在大数据集群不同节点上
➢数据集:RDD 封装了计算逻辑,并不保存数据
➢数据抽象:RDD 是一个抽象类,需要子类具体实现
➢不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢可分区、并行计算
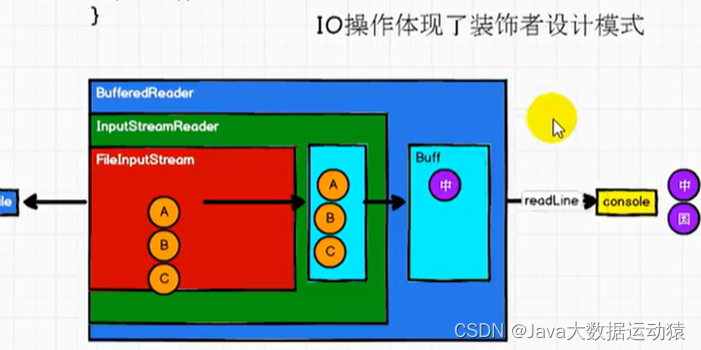
IO操作 VS RDD操作
RDD的数据处理方式类似于IO流,也有装饰者设计模式
总结:
RDD的数据处理方式类似于IO流,也有装饰者设计模式
RDD的数据只有在调用collect方法时,才会真正执行业务逻辑操作。之前的封装全都是功能的扩展。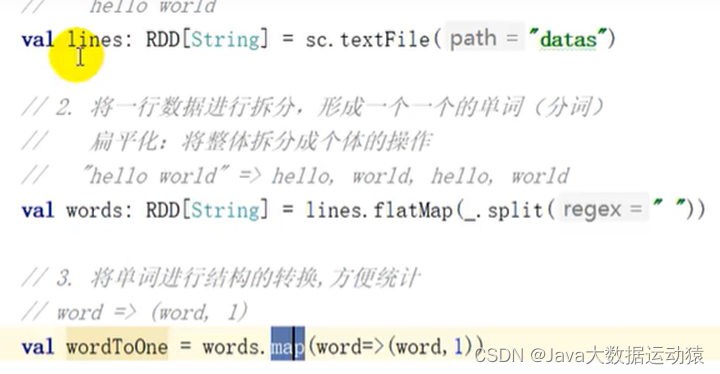

RDD是不保存数据的,但是IO可以临时保存一部分数据。

RDD算子有两种,一种转换算子,一种行动算子
转换算子是将旧的RDD包装成新的RDD,返回的结果是一个新的RDD,而行动算子会触发任务的调度和作业的执行,返回的直接是处理后的结果,而不是新的RDD。

完成比完美更重要!!!先能完成需求,再追求完美!!!



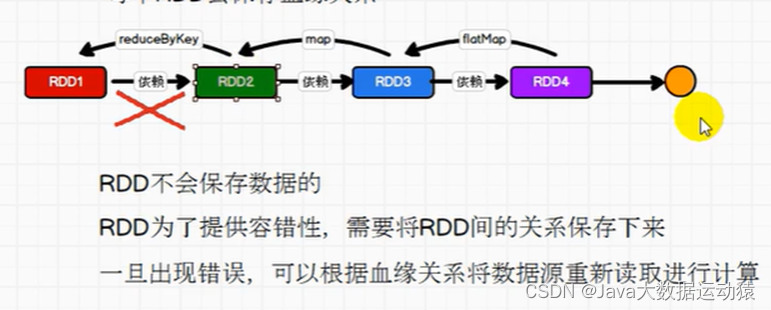
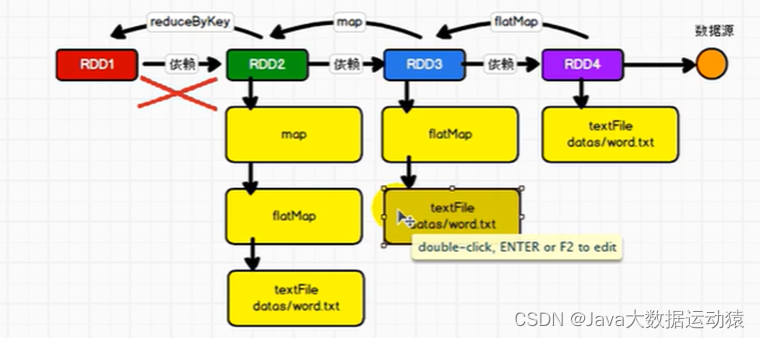
RDD是不会保存数据的,那么如果在图中的这几个操作中,最后一步reduceByKey出错的话,那么前面的操作都将失效吗?
答案是不会的,RDD提供了容错性,每一个RDD会将关系保存下来,出错了可以根据血缘关系直接将数据源重新读取进行计算。如下图:
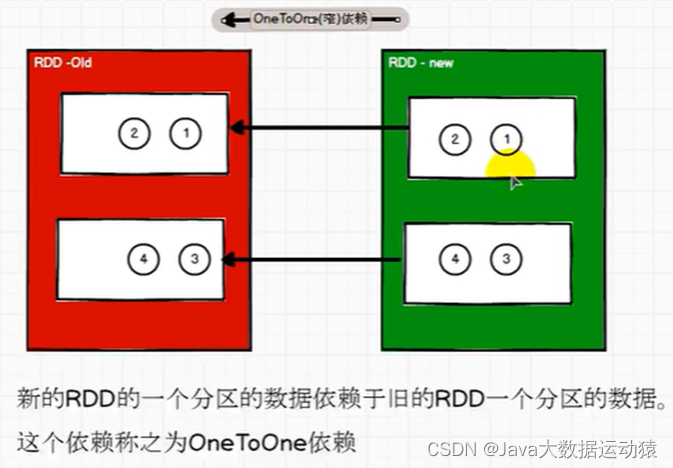

OneToOneDependency底层继承的是NarrowDependency,所以称为窄依赖
窄依赖的理解:
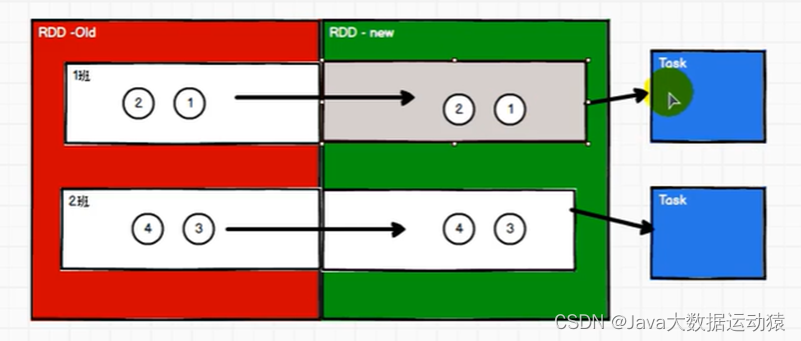
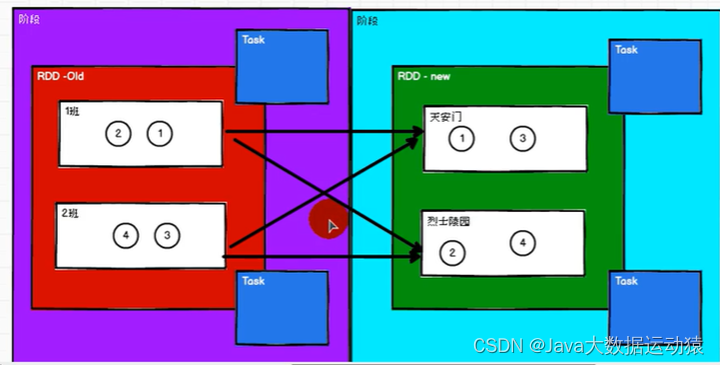
拿春游来举例,两个分区相当于两个班级,每个班级由一个老师带领,一个老师相当于一个task任务,窄依赖中,不需要涉及shuffle数据打乱混洗,所以一个旧的RDD各分区中的数据全部到了一个新的RDD对应分区中,而且分区之间任务执行不需要等待,各自执行各自的任务,最终只需要开启两个task就可以(task数=分区数)
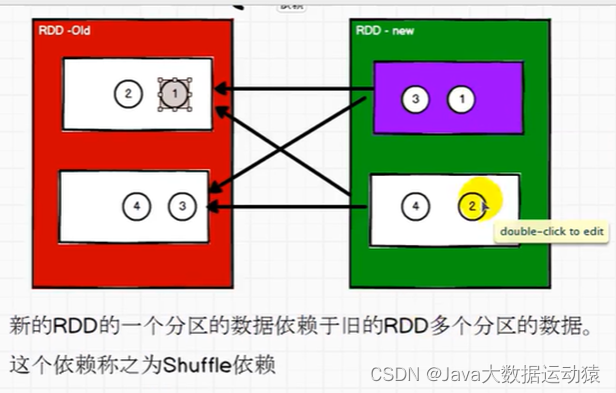

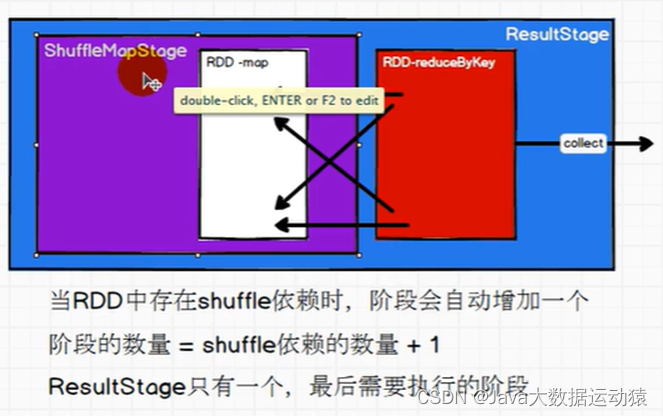
Shuffle依赖也叫宽依赖,但实际上没有宽依赖这个名词,shuffleDependency底层就是继承的Dependency,只是有了窄依赖,所以对应叫Shuffle依赖为宽依赖
宽依赖的理解:
同样拿春游来举例,两个班级对应的是另个分区,这两个班级的学生前期以班级为单位游玩,后面需要以景点为单位游玩,班级的同学有的去景点1有的去景点2,所以要重新打乱重组,而且是分阶段的,重组之前是一个阶段,重组之后是一个阶段,分区任务之间需要等待,那么之前以班级为单位的时候需要两个老师,后面打乱重组之后又需要两个老师带领,所以一共要有四个task

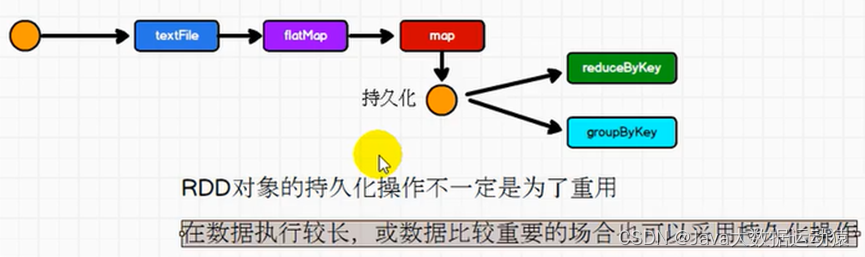
RDD的持久化
当我们对数据做了一定操作之后,我们想从map这里,做两个功能的实现,一个reduceByKey,一个groupByKey,但RDD是不存储数据的,所以一个RDD要重复使用,则要从头执行。
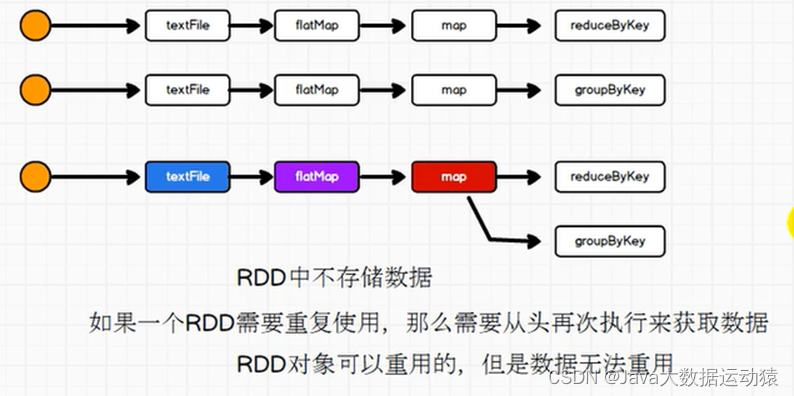
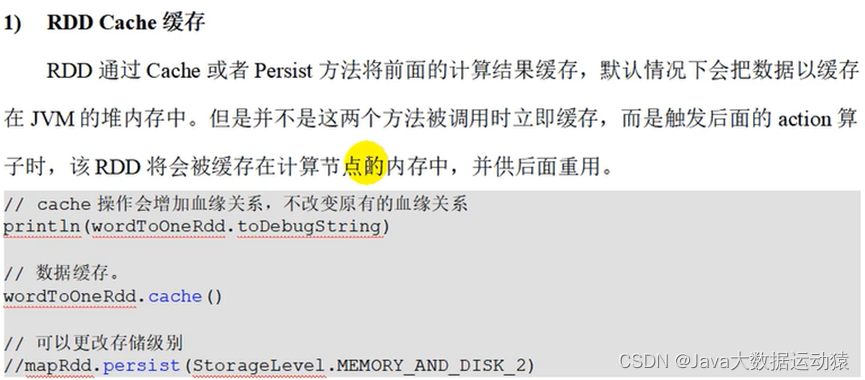
因此,RDD有持久化机制,持久化就是在一个RDD需要分叉的地方,将数据缓存到内存或者磁盘文件中。内存的话效率快但不安全,磁盘文件安全但效率低,所以要综合考虑选择。
代码中提供了Cache和Persist两个方法,Cache默认是放到内存,Persist方法里有很多固定参数选择,如何放到磁盘。
Checkpoint检查点:
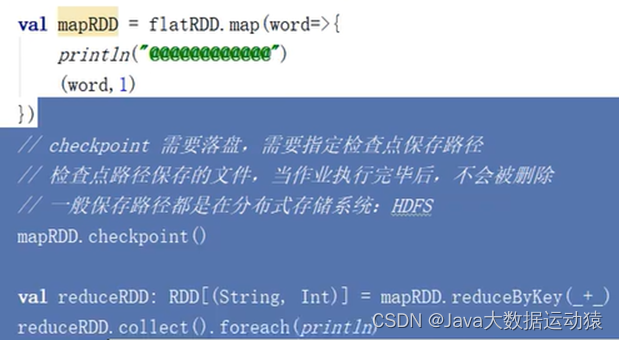
Cache、persist、checkpoint三个的区别:

RDD分区器:

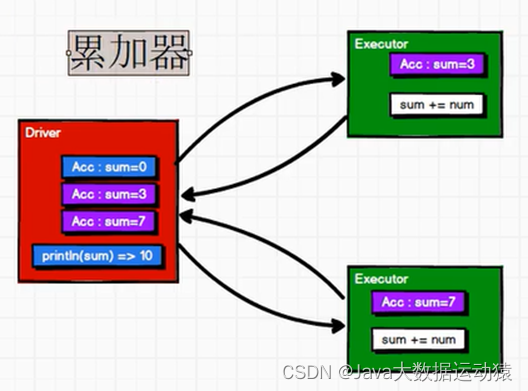
累加器:

在RDD中,Executor与Driver之间是无闭环的,只能Driver到Executor端发送数据,不能Executor端向Driver端发送数据,所以sum经过Executor端的计算之后不会返回到Driver端数据。然而,只有执行行动算子才会执行Executor,其他功能都在Driver端。
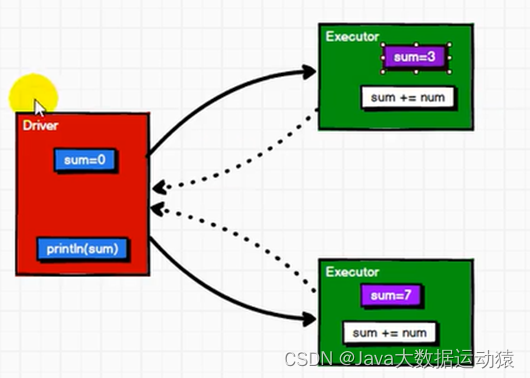
所以,累加器的作用就是,Driver将数据发送到Executor进行计算,Executor计算完之后可以返回给Driver端数据。
广播变量:

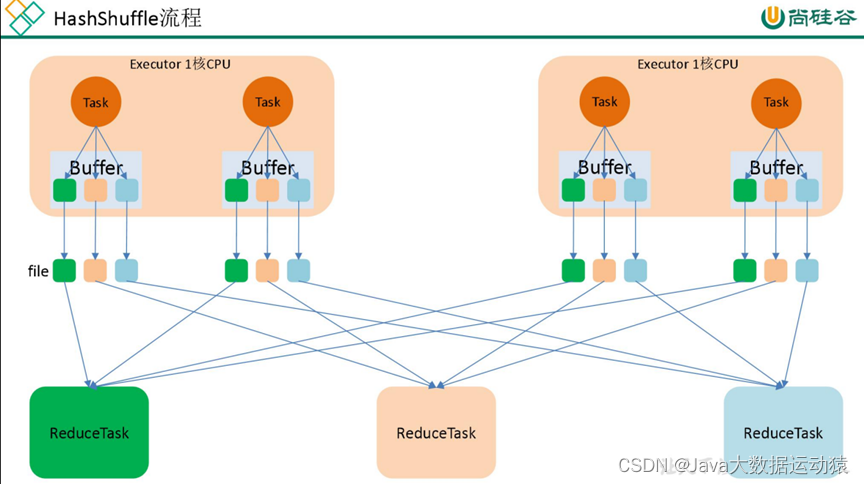
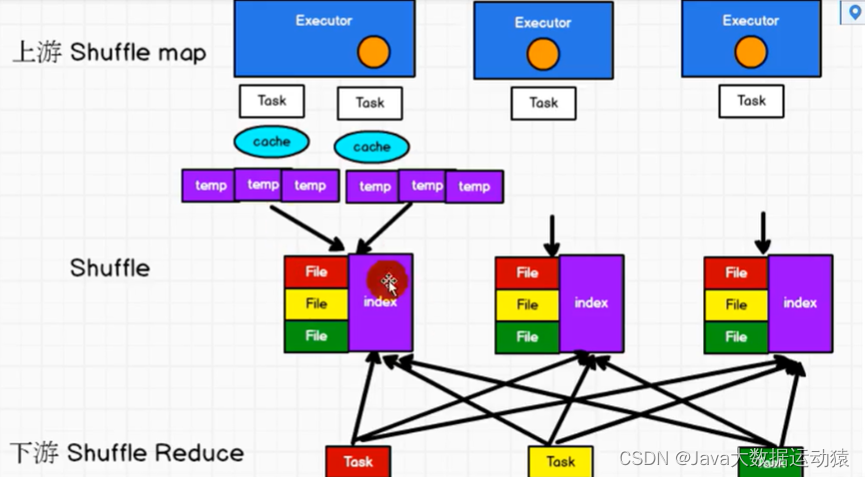
Spark shuffle:
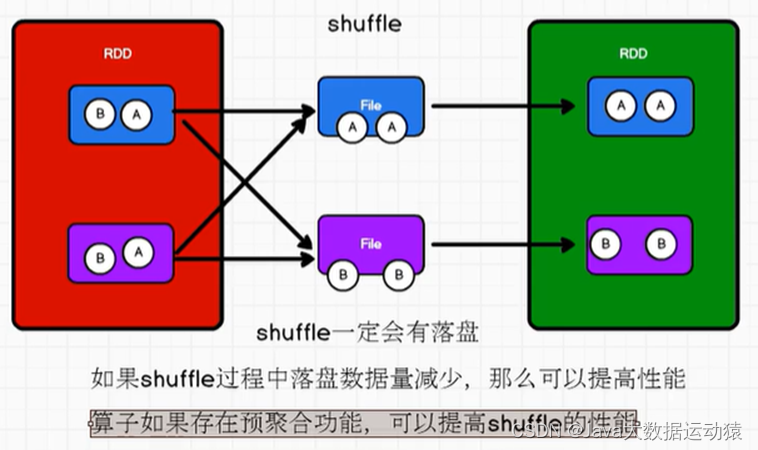
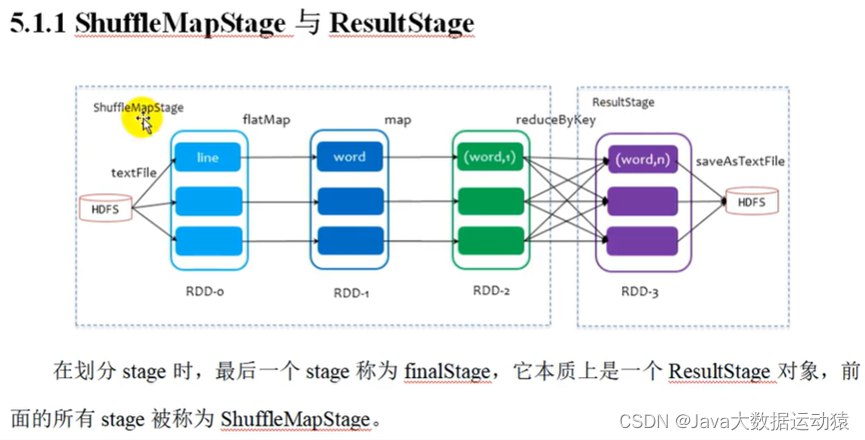



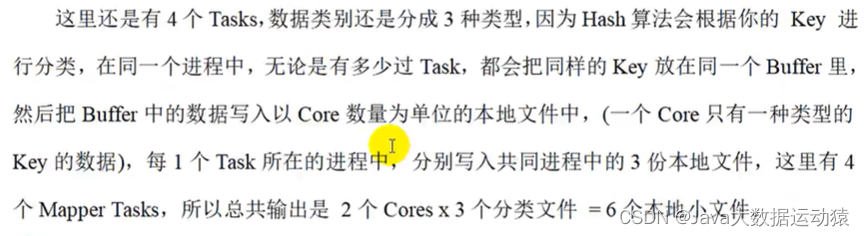
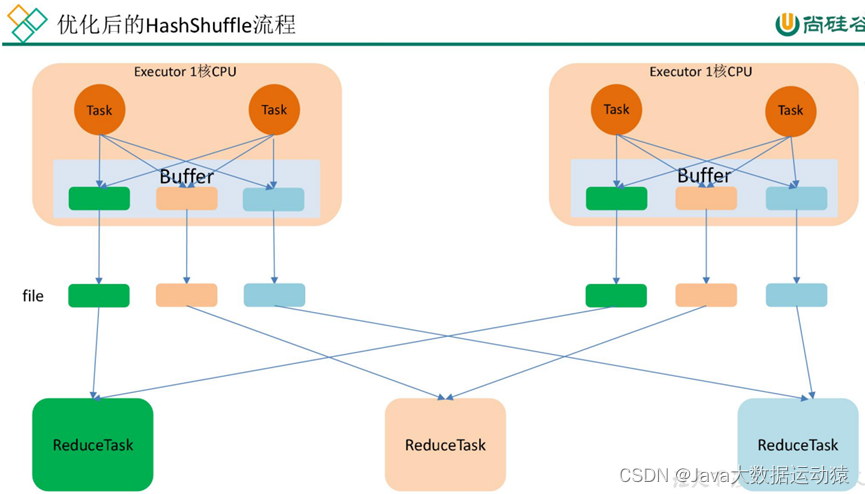
未优化的Hash shuffle




Spark SQL:


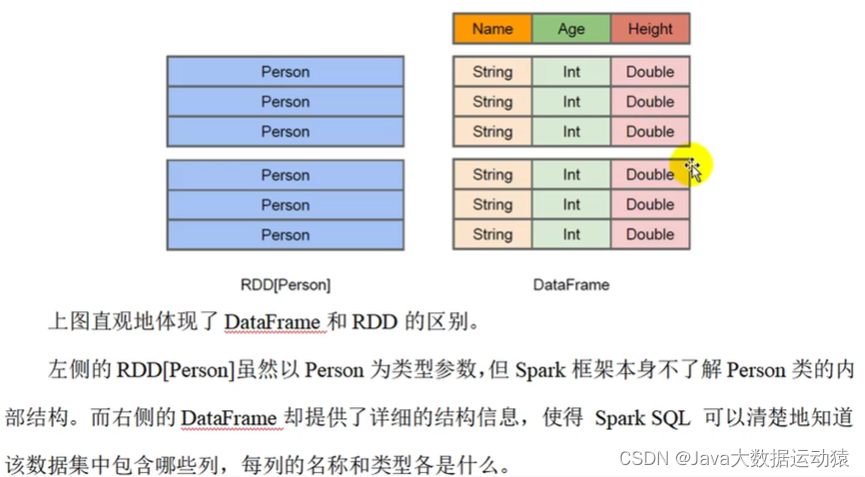

type DataFrame = Dataset[Row] ;DataFrame其实是特定泛型的Dataset,可以理解为DataSet是DataFrame的升级版本。
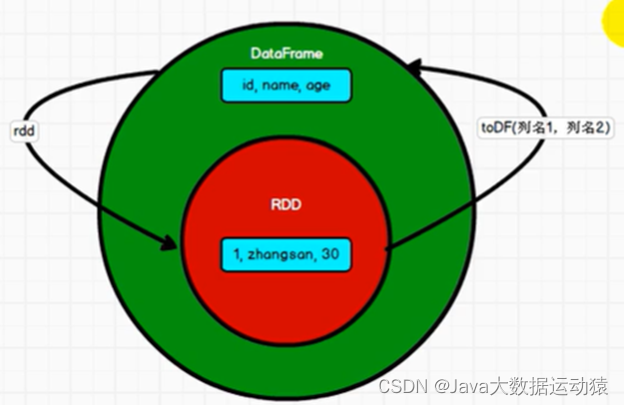
RDD、DataFrame、DataSet三者之间的转换:

package com.atguigu.bigdata.spark.sql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object Spark01_SparkSQL_Basic {
def main(args: Array[String]): Unit = {
//TODO 创建SparkSQL的运行环境
val sparkSQL: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sparkSQL")
val spark = SparkSession.builder().config(sparkSQL).getOrCreate()
import spark.implicits._//启用隐式转换
//TODO 执行逻辑操作
//DataFrame
val df: DataFrame = spark.read.json("datas/user.json")
// df.show()
//DataFrame =>SQL
df.createOrReplaceTempView("user")
spark.sql("select * from user").show
spark.sql("select age,username from user").show
spark.sql("select avg(age) from user").show
//DataFrame =>DSL
//在使用DataFrame时,如果涉及到转换操作,需要引入转换规则
//转换规则:(1)在涉及转换列的前面加$,(2)在涉及转换列的前面加' 涉及到转换的话,要声明隐式转换
df.select("age","username").show
df.select($"age" + 1).show
df.select('age +1).show
//DataSet
//type DataFrame = Dataset[Row] DataFrame其实是特定泛型的Dataset,
// 所以DataFrame中的那些方法DataSet都可以用
val seq = Seq(1, 2, 3, 4)
val ds: Dataset[Int] = seq.toDS()
ds.show()
//RDD <=> DataFrame
//RDD => DataFrame
val rdd: Any = spark.sparkContext.makeRDD(List((1, "zhangsan", 30), (2, "lisi", 40)))
val df1: DataFrame = rdd.toDF("id", "name", "age")
//DataFrame => RDD
val rowRDD: RDD[Row] = df1.rdd
//DataFrame <=> DataSet
val ds: Dataset[User] = df1.as[User]
val df2: DataFrame = ds.toDF()
//RDD <=> DataSet
val ds1:Dataset[User]= rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
val userRDD: RDD[User] = ds1.rdd
//TODO 关闭环境
spark.close()
}
case class User(id:Int,name:String,age:Int)
}



Spark Streaming:

流式数据处理:来一条处理一条
批量数据处理:囤一批后再处理
数据处理延迟长短,如计算去年一年的流水,毫秒级别内处理完的叫实时数据处理,小时或者天级别处理完的,说明已经是之前的数据了,叫离线数据处理。
SparkStreaming用于流式数据的处理,是一个准实时(延迟:秒,分钟级别),微批次(时间)的数据处理框架。
因为来一条处理一条太浪费资源,所以sparkStreaming做不到流式,但批量的话,又成了离线,所以sparkStreaming介于流式和批量之间,做微批次,就是屯几秒的数据再进行处理。

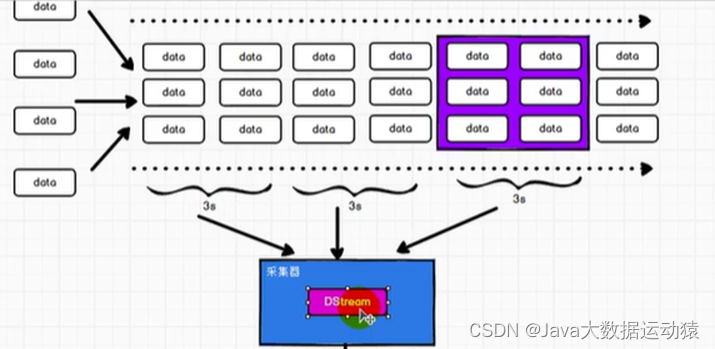
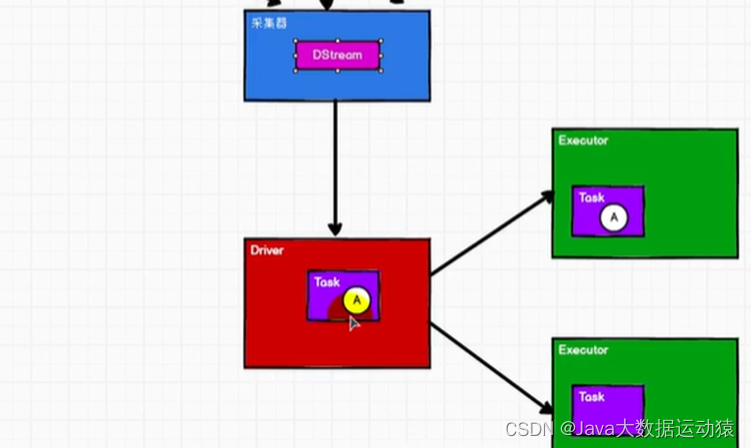





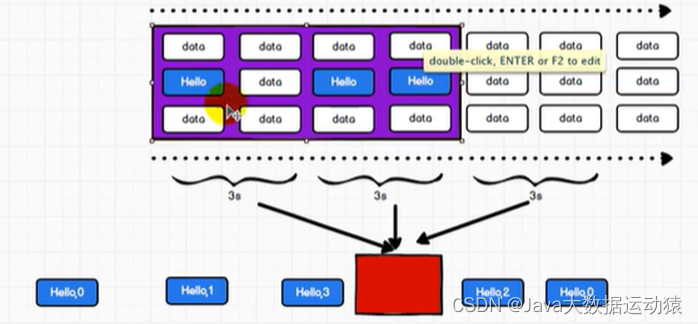



所谓的有状态和无状态,
无状态转化操作指:每一次操作都是针对一个批次进行计算,批次间各计算各的。
有状态转换操作指:在一个时间区间内,批次间的计算会累加,如第一个批次计算出(hello,3),第二个批次有(hello,4),那么在第二批次计算出的值是(hello,7),也就是跟第一批次进行累加。




优雅关闭的意思是,不再接收新的数据,将已接收的数据处理完,而不是强制关闭。















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









