







字符编码一般是导致文件乱码的主要原因。
每次记不太清楚这些各种各样的字符编码名称,现在还是整理一下。
主要查阅资料来自于:Ansi,UTF8,Unicode,ASCII编码的区别
总的来说,字符编码主要分这两大类:
1.ANSI
2.UNICODE
其他大部分字符编码都能归并到这两类里面,为其子类。
总结下网上查到的资料,说说由来:
ASCII:
一开始,大家用的都是ASCII码字符集(没错,就是每次C语言课程讲来讲去的那个,另外“大家”指的是米国人,恩)。
一个ASCII码占用1字节(8位)。
ASCII码支持包括英文、控制符号等一共127个字符(最高位为0)。
而最高位为1的另128个字符被成为“扩展ASCII”,一般用来存放英文的制表符、部分音标字符等等的一些其他符号。(在标准ASCII码中最高位是用来做奇偶校验位的)
其他语言比如中文和阿拉伯文,并没有足够的位置可以放。(就算占用了最高位,多了128~255这128个字符,对于中文几万个字符还是明显不够用)。
ANSI:
方法总是得想的,毕竟大家都学英语也遭不住(文字可是一个文明的象征啊喂)。
1.存储空间不够大的问题:
单字节的位数保持8位不能乱变,不过可以增加单个文字占用的字节个数,例如让一个中文占两个字节的位置。两个字节能存储的字符数为65536个,能够满足存储大部分汉字的要求。
2.兼容原ASCII码格式:
为了不覆盖原来的ASCII码(保持兼容),怎么让计算机区分是应该一个一个字节的读呢,还是两个两个字节的读文件?
方法就是看当前字节值是否大于127,即最高位是否为1。如果是1,那就按两个字节的读,如果是0,代表普通的ASCII码,读取一个字节即可。
虽说字节值大于127应当属于"扩展ASCII"的范围,但因为其并未真正标准化,所以各国将其位置拿来先搞自己的文字编码规范(比如中文的“GB2312-80”,"Big5")。
这种方法一开始是OK的,但后来冲突就越来越多:一些使用"扩展ASCII"画表格的软件,在中文环境下会把表格符号翻译成中文。在统计中英文混合的文本字数时也会比较麻烦,另外各国之间的扩展ASCII码也会冲突。
对此ANSI(美国国家标准学会)为编码规范制定了一个标准,当最高位为1时,为扩展ASCII码和双字节文字划分对应的范围。整合各国文件编码规范后,将其改成代码页的形式(就像一本书,一页代表一种规范),在对应的环境下就用对应的一页,所以两种不同规范的文字是不能存在一起的。知道为啥简体中文环境下玩日文版/繁体中文版游戏乱码了吧,用错翻译的编码规范了。
UNICODE:
因为ANSI的代码页实在太多,在国际交流中频繁切换字符集很麻烦。所以人们决定提出UNICODE字符集。
相比起ANSI的分页,UNICODE就是大杂烩了,它为每个文字都分配了一个单独编码,这样就不存在不同的规范了。
UNICODE目前主要分UTF-8、UCS2、UTF-16三种编码格式。
其中UTF-8和UTF-16一开始是作数据传输的格式使用的,但后来因为网页上大量的使用UTF-8,结果浏览器也支持直接使用UTF-8编码了。
UTF-8对ASCII码是兼容的,但其一个字符的字节数不一定,从一个字节到三个字节都有可能(理论上最大是六个子节,不过没那么多字符就是了)。
而UCS2固定是一个字符占两个字节的位置,固定的字符长度在处理字符速度上会更快一点。
UTF-16类似于UTF-8,不过是以2个字节或者4个字节为单位进行编码的,跟UCS2没啥差别,但因为其是作传输用,所以要考虑两个字节序:
字节序解决方法:BOM(Byte Order Mark),采用一个无实际意义的字符作为传输起始符(就像是c字符串中的'\0',不过是做起始用)。其在UCS中编码为'FEFF',如果接收到'FEFF',则说明这个字节流是Big-Endian的;如果收到'FFFE',就表明这个字节流是Little-Endian的。比如下图中Notepad中的编码设置以及文本文档中另存为的编码选择:
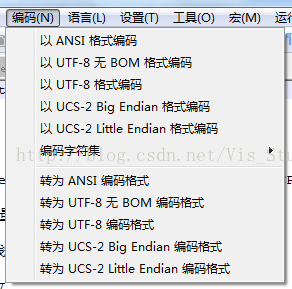
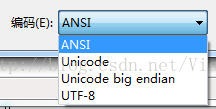
像文本文档中,没有说明Unicode是Big Endian的就默认是Little Endian格式了。
UTF-8中也是存在BOM的,其编码格式为EF BB BF。
另外还存在UCS4,不过貌似还没真正推出规范?兼容UCS2,暂且理解为UCS2的升级版好了。
实际应用中,需要一说的是:Windows的命令行环境下(比如你用cfree或者vs跑起来的那个黑框窗口),输入的中文都为ANSI编码格式,除非是从Unicode编码的文件中读取了中文,因为编码的不同,此时可能会导致乱码的出现。(之所以发现这个问题是因为写一个合并文件的小程序时,发现两种不同编码的文件合并在一起会导致乱码2333)
总的来说,记住两大编码类,然后好好把其他编码规范划分到对应项下,一般就不会记混了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









