







第一讲:神经网络(Neural Network)的有关背景
对于一个非线性(non-linear)的分类问题,当特征数较少时,可以通过多项式拟合出决策边界(decision boundary)。然而对于一个现实问题,特征数往往很多,这时多项式项的个数就会变得很多,因为你想要去更好的拟合样本。此时会存在一些问题,比如运算量过大,容易出现会过拟合(over-fitting)的情况。
神经网络就是为了解决上述问题而存在的。神经网络在上个世纪80,90年代初期被广泛应用,90年代后期变得不再那么流行。而最近神经网络东山再起,一个原因是计算机的运算能力得到了增强。
第二讲:神经网络的模型
神经网络的灵感来自于人类大脑中的神经元,神经元的树突接受其它神经元的输入信息,通过细胞体进行计算,最后树突再将计算结果输出至其它神经元。对应的神经网络也就大致分成了三个部分,分别是输入层(input layer),隐藏层(hidden layer),输出层(output layer)。下面还是通过Ng课程上的PPT来进行复习吧。

这就是一个简单的三层神经网络,除了输出层之外,其它层都有一个偏置单位(Bias Unit),且值都等于1.我记得在前边几周讲线性回归的时候,也有一个类似于偏置单位的项存在。应该是a0 * x0,目的我有点忘了,等过几天总结前几周的时候再提吧。第二层的参数是通过第一层的权重矩阵和第一层的输入参数运算得到的。具体运算过程如下。
除了输出层每一层都有一个权重矩阵(weights matrix),维数是这样确定的:如何第j层有sj个单元,j+1层有s(j+1)个单元,第j层的权重矩阵的维数是s(j+1) * (sj + 1)。这里的+1是因为sj层的偏置单元,也就是说输出层不包含偏置单元(无需计算,等于1),而输入层是包含了偏置单元(因为要参与运算)。具体运算过程如下图,假设Theta是sj层的权重矩阵,X是sj层的列向量,sigmoid(Theta * X)就好了。
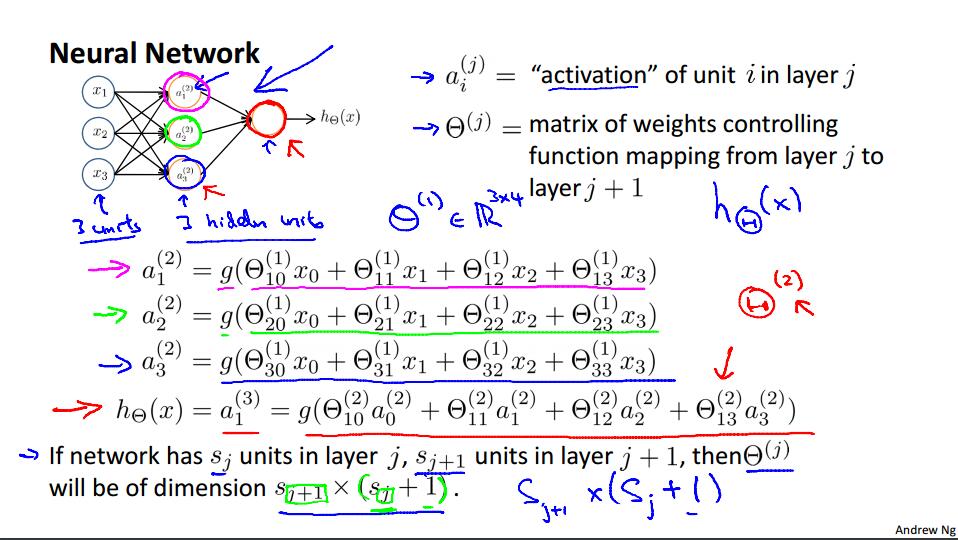
后面几张PPT没啥讲的,就是详细的说了一下上述的运算过程。还有通过神经网络模拟了一些逻辑运算符的运算过程,有一个直观的感受。最后讲了Multiclass Classification,还有一种方法叫One-vs-all。这种方法的期望效果就是令输出为一串0或者1,其中只有一个1,其它的都是零,值等于1的位置对应的分类结果就是最后的识别结果。
下面来说一下本周的编程作业。
本周作业分成两个部分,第一部分是完成三个文件 IrCostFunction.m oneVsAll.m predictOneVsAll.m
IrCostFunction是要计算一个正则化逻辑回归的代价函数值和梯度。这个的方法和上周作业基本是相同的。然而作业的guide ex3.pdf里面让你先实现非正则化的形式。在实现代价函数的时候根据guide我是这么写的:
hx = sigmoid(sum(X .* theta', 2));
hx = sigmoid(Theta * X);
J = (-1 / m) * sum(y .* log(hx) + (1 - y) .* log(1 - hx));
grad = (1 / m) * (X' * (hx - y));
temp = theta;
temp(1) = 0;
J += (lambda / 2 / m) * sum(temp .* temp);
grad += (lambda / m) * temp;
下面是oneVsAll.m
for c = 1:num_labels
% Set Initial theta
initial_theta = zeros(n + 1, 1);
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 50);
% Run fmincg to obtain the optimal theta
% This function will return theta and the cost
[theta] = ...
fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), ...
initial_theta, options);
all_theta(c,:) = theta';
end;这个文件就是用fmicg自动进行梯度下降算法的执行,上周作业有用过fminunc,使用方法类似,设置好参数就可以了。不过有一点需要注意,这里要用logical arrays来传参数。
predictOneVsAll.m
[x,p] = max(all_theta * X');这里也没多少说的,像我这个线代不好的,就把维数写在纸上,理解了过程,最后注意用max函数就好了。max函数也可以传一个维度的参数,对于矩阵默认累加列。max函数也可以返回第一个最大值的索引。这里p接收索引,具体的用help max来查看max函数的帮助。
predict.m
X = [ones(m, 1) X];
temp = sigmoid(Theta1 * X');
temp = [ones(1, size(X,1)); temp];
[x,p] = max(sigmoid(Theta2 * temp));















 4283
4283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









