







本文将主要解释coursera网站上斯坦福大学的机器学习公开课(吴文达老师)第六周Advice for Applying Machine Learning的课后习题的讲解,与同学们共同探讨学习。
1.第一题
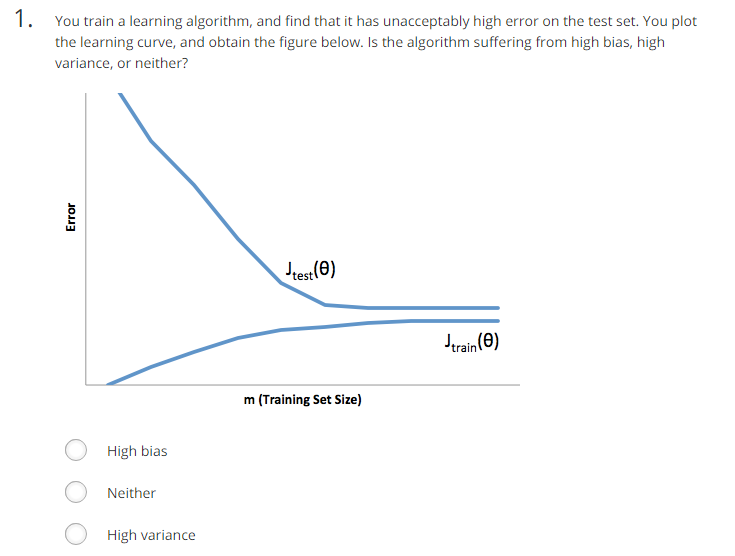
题意:你训练了算法,在用测试数据进行测试时有很大的错误,画出了如下图所示的学习曲线。请问它是高偏差,高方差还是两者都不是?
分析:吴老师在上课时候就明确说过,随着m增大,Jtest和Jtrain接近的是high bias问题,即欠拟合。若Jtest和Jtrain相差很大,为high variance,即过拟合。
答案:high bias
2.第二题

题意:假设你利用正则化后的逻辑回归来做图像识别。当你用一些新的图像测试你的假设函数,发现图像预测时出现不可接受的巨大的错误。但是你的假设模型对训练样本的效果良好。以下哪些操作可以解决?
添加更多多项式特征,如x1x2,x1x3…
使用更少的训练样本
添加更多的训练样本
使用更少的特征
分析:题目说对训练样本效果良好,但是对新样本的泛化能力不好,说明此模型过拟合。添加更多特征多项式可以解决欠拟合,不选。使用更少的训练样本无作用&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1289
1289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









