







/*
对等模式的MPI程序:test_8_1_2.c
Jacobi迭代:迭代数据按列进行分割,
并假设一共有4个进程同时并行计算。
时间:15.7.27
Jason Zhou
热爱你所写下的程序,他是你的伙伴,而不是工具.
*/
#include "mpi.h"
#include <stdio.h>
#define totalsize 8
#define mysize totalsize/4 //分成四块,每块大小
#define steps 10
int main(int argc,char* argv[])
{
int myid,numprocs,n,i,j,rc;
float a[totalsize][mysize+2],b[totalsize][mysize+2],tmp[mysize][totalsize],c[totalsize][totalsize]; //除分块大小外,还包括左右两边各一列
float temp[totalsize]; /* 临时数组 */
int begin_col,end_col,ierr;
MPI_Status status;
//初始化c数组
for(i=0;i<totalsize;i++)
{
for(j=0;j<=totalsize;j++)
c[i][j]=0;
}
for(int j=0;j<mysize;j++)
for(int i=0;i<totalsize;i++)
tmp[j][i]=8;
MPI_Init(&argc,&argv);
/* 得到当前进程标识和总的进程个数 */
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
fprintf(stderr,"Process %d of %d is alive.\n",myid,numprocs);
/* 数组初始化 */
//NOTE: 整个数组置值为0, 行数为 totalsize, 列数为 mysize+2
for(j=0;j<mysize+2;j++)
for(i=0;i<totalsize;i++)
a[i][j]=0.0;
if(myid==0)
for(i=0;i<totalsize;i++)
a[i][1]=8.0;
if(myid==3)
for(i=0;i<totalsize;i++)
a[i][mysize]=8.0;
for(i=1;i<mysize+1;i++){
a[0][i]=8.0;
a[totalsize-1][i]=8.0;
}
/* Jacobi迭代部分 */
for(n=1;n<=steps;n++)
{
//这里从两边分别"获取数据"和"发送数据",每次获取或发送数据时先判断是否会越界
/* 从右侧的邻居得到数据 */
if(myid<3)
{
MPI_Recv(&temp[0],totalsize,MPI_FLOAT,myid+1,10,MPI_COMM_WORLD,&status);
for(i=0;i<totalsize;i++)
a[i][mysize+1]=temp[i];
//a[i][mysize+1]为块最右一列,表示相邻右侧一块最左边一列
}
/* 向左侧的邻居发送数据 */
if(myid>0)
{
for(i=0;i<totalsize;i++)
temp[i]=a[i][1];
MPI_Send(&temp[0],totalsize,MPI_FLOAT,myid-1,10,MPI_COMM_WORLD);
}
/* 向右侧的邻居发送数据 */
if(myid<3)
{
for(i=0;i<totalsize;i++)
temp[i]=a[i][mysize];
MPI_Send(&temp[0],totalsize,MPI_FLOAT,myid+1,10,MPI_COMM_WORLD);
}
/* 从左侧的邻居得到数据 */
if(myid>3)
{
MPI_Recv(&temp[0],totalsize,MPI_FLOAT,myid-1,10,MPI_COMM_WORLD,&status);
for(i=0;i<totalsize;i++)
a[i][0]=temp[i];
//a[i][0] 为块最左一列,表示相邻左侧一块最右一列
}
begin_col=1;
end_col=mysize;
if(myid==0)
begin_col=2;
if(myid==3)
end_col=mysize-1;
for(j=begin_col;j<=end_col;j++)
for(i=1;i<totalsize-1;i++)
b[i][j]=0.25*(a[i][j+1]+a[i][j-1]+a[i+1][j]+a[i-1][j]);
for(i=1;i<totalsize-1;i++)
for(j=begin_col;j<=end_col;j++)
{
a[i][j]=b[i][j];
}
}/* 迭代结束 */
int loc=begin_col;
if(0==myid)
loc--;
for(i=1;i<totalsize-1;i++)
for(j=begin_col;j<=end_col;j++)
{
tmp[j-loc][i]=a[i][j];
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Gather(tmp,16,MPI_FLOAT,c,16,MPI_FLOAT,0,MPI_COMM_WORLD);//需要单独在外面
/* 输出结果 */
if(0==myid)
{
fprintf(stderr,"\nProcess %d :\n",myid);
for(int j=0;j<mysize;j++)
{
for(int i=0;i<totalsize;i++)
fprintf(stderr,"%.2f\t",tmp[j][i]);
fprintf(stderr,"\n");
}
fprintf(stderr,"\n");
fprintf(stderr,"\n收集后结果\n");
for(int i=0;i<totalsize;i++)
{
for(int j=0;j<totalsize;j++)
fprintf(stderr,"%.2f\t",c[i][j]);
fprintf(stderr,"\n");
}
fprintf(stderr,"\n");
}
MPI_Finalize();
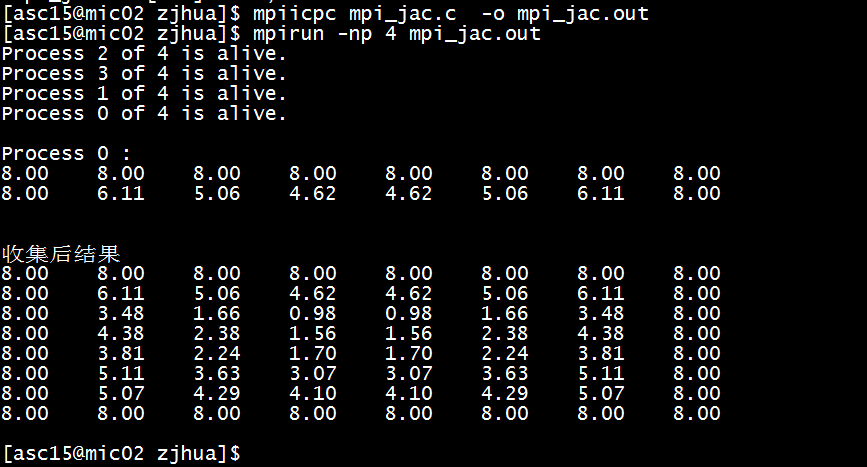
}输出结果如下图














 7153
7153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









