







雅可比迭代
jacobi迭代的主体部分可以如下图所示,来源高性能计算之并行编程技术。

MPI并行处理思路
把要处理的数据按照行或者列均摊给每个进程,书中迟老师讲的是按照列均摊,因为书中用的fortran,其二维数组是有限按照列存储的,而本文中使用C++数据是按照行存储的。因此这里我们按照行划分。
需要注意的是,有一些边界行的计算需要相邻进程发送数据,因此这里我们统一给每一个进程划分的数组大小为 (M+2) * N,因为我们在上下行各添加了额外的一行。如下图所示:
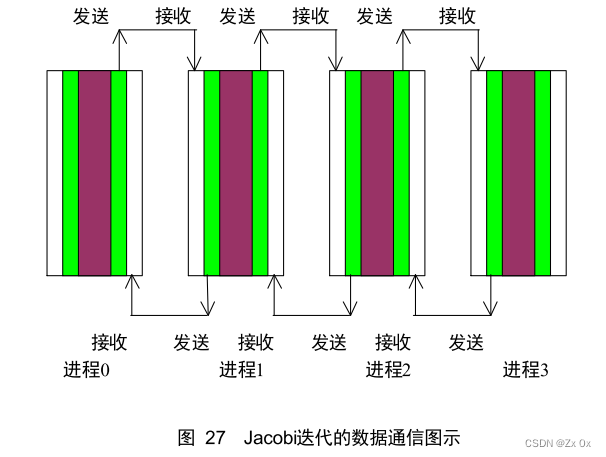 图中是按照列划分的,按照行划分同理。
图中是按照列划分的,按照行划分同理。
朴素版代码
#include "mpi.h"
#include<iostream>
#include<stdio.h>
#include<math.h>
#include <cstring>
#include <ctime>
using namespace std;
const int N = 16; // 需要处理的矩阵的阶数
// 打印矩阵
void disp(double *X,int rows,int cols){
for(int i=0;i<rows;i++){
for(int j=0;j<cols;j++){
printf("%6.1f",*(X+i*cols+j));
}
puts("");
}
}
int main(int argc,char*argv[]){
int rank,numprocs;
MPI_Status status;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
cout<<rank<<" is alive!"<<endl;
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
int M = N/numprocs ; //将矩阵按照行平均划分,每个进程获得M行数据
double C[M+2][N],D[M+2][N]; //但是要在每一个子矩阵的上面和下面添加一行,否则无法计算边缘的值
double A[N][N],B[N][N]={
0};
double start,end; //计算时间
// 0号进程计算,并分发任务给其他进程
if(rank==0){
srand(time(NULL));
//initialize
for(int i=0;i<N;i++){
for(int j=0;j<N;j++){
A[i][j] = rand()%10;
}
}
puts("before:");
disp(&A[0][0],N,N);
// 0 号进程先给其他进程分配任务
if(numprocs<1){
fprintf(stderr,"error!");
exit< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









