






词向量综述
one-hot
一个词的meaning指的是:the idea that is represented by a word, phase, etc.
计算机表达一个词的meaning,是通过把词性、词义相同的词构成一个集合来实现的。典型的例子是WordNet。
通过集合表达词性有如下缺点:
- 同义词区分不明显:adept、expert、good、prooficient虽然大致含义相同,但是使用的上下文是不同的,不可以把它们当成完全一样的。
- 过时性:新的词不可以及时更新
- 主观性
- 需要人力去创造词典集合
- 较难计算词之间的相似度
具体地,词在计算机中是以[0,1,0,0…]的向量表示的,该词对应的index的值为1,其他为0。这样做简单方便,可是缺点也很明显:
- 占用空间大
- 两个相近词的交集为0,距离很远
by neighbor
You shall know a world by the company it keeps.
Similar words appear in similar contexts.
这个方法的核心是认为相近的词的上下文也是相近的。识别词的上下文又有两种做法:
- 基于全文档:词-文档的
co-occurrence matrix可以把词划分为不同的主题,延伸的有Latent Semantic Analysis。 - 基于window:基于全文档的只可以反映语义信息,基于window的可以反映语义和语法信息,例如
CBOW和Skip-Gram。
基于全文档的词向量
- word count matrix
- tf-idf matrix
- LSA
基于window的词向量
一般来说,基于window的词向量有以下特点:
- window长为5-10
- 对称性,不区分左边右边
- 一些功能词(the,he,she)出现的太频繁,影响较大。解决办法一是设定max_count,二是把这些词忽略掉
- window的时候考虑远近,加以不同的权重
- 使用pearson相关系数代替count
选择window为1,例子如下:
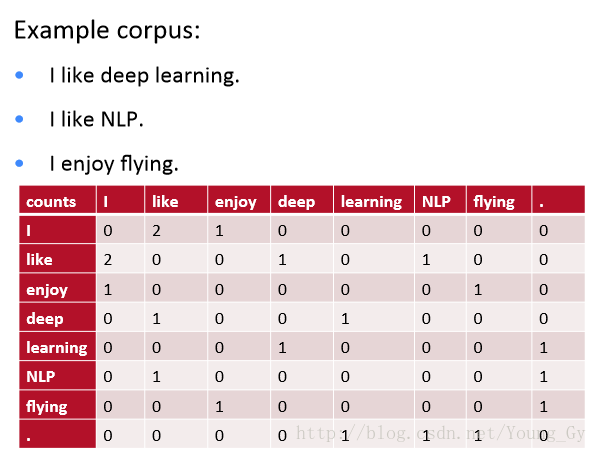
上图中,like和enjoy的相似度就很高,通过co-occurrence matrix确实可以构建反映词语义的词向量。
SVD
上面的co-occurrence matrix词向量的维度是词汇库的维度,向量太长。可以通过SVD降维得到维度较低的词向量。
SVD的缺点如下:
- 计算复杂度太高
- 新的词或者文档来的时候还要重新计算
Skip-Gram
与其计算co-occurrence matrix,不如直接学习词向量。这样学的更快,而且当新的句子或者文档来的时候也能适应。
结构
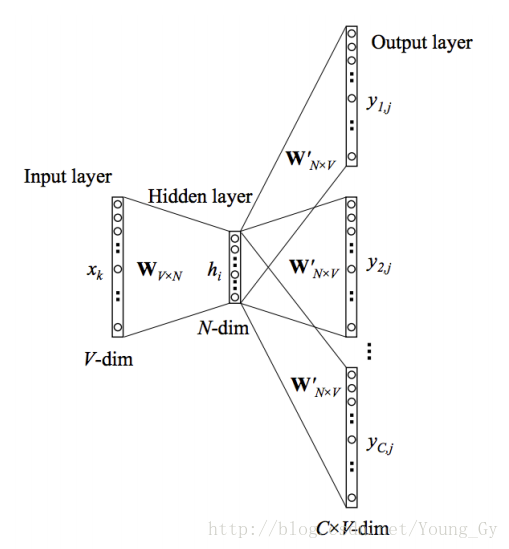
- 输出层接了softmax的激活函数
-
uc,j
的值相当于
W
中输入数据对应的词向量乘以
W′ 中第 j 个数据对应的词向量 uc,j 为softmax前的值, yc,j 为softmax后的值
输入输出
- 输入:单词 wI
- 输出:单词 wI window内的单词序列 {wO,1,wO,2,...,wO,C}
单词都是ont-hot编码,单词长度为 V 。
学习算法
损失函数如下:
优化角度
改进
针对skip-gram有以下改进策略:
- Treating common word pairs or phrases as single “words” in their model.
- Subsampling frequent words to decrease the number of training examples.
- Modifying the optimization objective with a technique they called “Negative Sampling”, which causes each training sample to update only a small percentage of the model’s weights.
word pair
常见的词语Boston Globe与单个词语Boston 和Globe有着不同的含义,所以应该额外认为是一个词。
sub-sampling frequent words
对于常出现的单词the,有下面两个问题:
- 当看一个单词对 (fox,the)的时候,这个单词对并没有告诉我们太多关于fox的信息,因为the出现的频率太高了。
- 学习the的词向量,需要的样本远低于实际的样本。
通过subsampling可以解决上面的问题,其思路是:对于文档中遇到的每一个词,都有一定的概率把这个词从文档中删除。删除的概率和词频成正比。
negative sampling
在神经网络的训练中,通过输入训练样本,计算损失函数,反馈梯度更新网络的所有权重。也就是说,每一次训练都更改了网络的所有权重。
在skip-gram模型中,网络参数是很大的,训练数据也很大,每一次训练更新的都很多,速度较慢。
negative sampling,使每个训练样本只更新网络的一部分参数。
- 随机挑选部分negative words进行训练(挑选的概率与词频成正比),对于小的数据集5-20即可;大的数据集2-5即可。
- 更新隐含层到输出层的权重时,只更新positive word和negative word连接的权值即可。更新输入层到隐含层的权重时,只有输入数据对应的权重被更新(用不用negative sampling都这样)。
Continuous BOW
结构
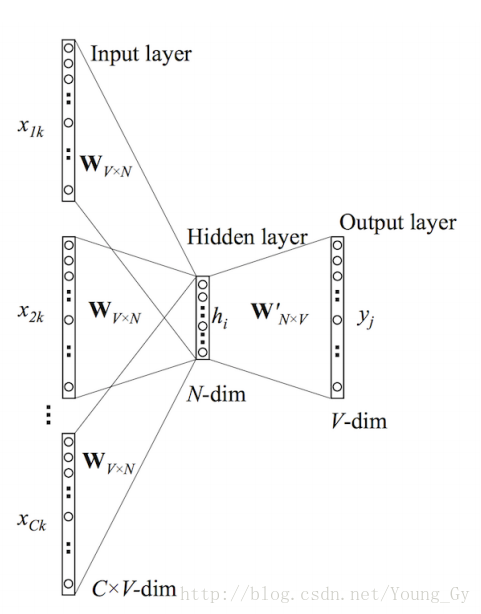
输入输出
- 输入:单词
y
window内的单词序列
{x1,x2,...,xC} - 输出:单词 y
单词都是ont-hot编码,单词长度为
算法
计算forward pass的时候,隐含层的计算方法如下:














 9168
9168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









