






z值:实质是偏离均值标准差的个数。
不同分布的z值具有可比性,例如N(0,1)的数据1的z值是1,表示离均值0有一个标准差,另外N(100,10)的数据110的z值也是1,表示离均值100有一个标准差,这样的话可以将不同的分布的数据,通过z值,直接比较各自距离各自均值的距离远近。
一般来说,对于正态分布,三个标准差内几乎涵盖了所有的数据。
68%的数据落在一个标准差内
95%的数据落在两个标准差内
99.7%的数据落在三个标准差内
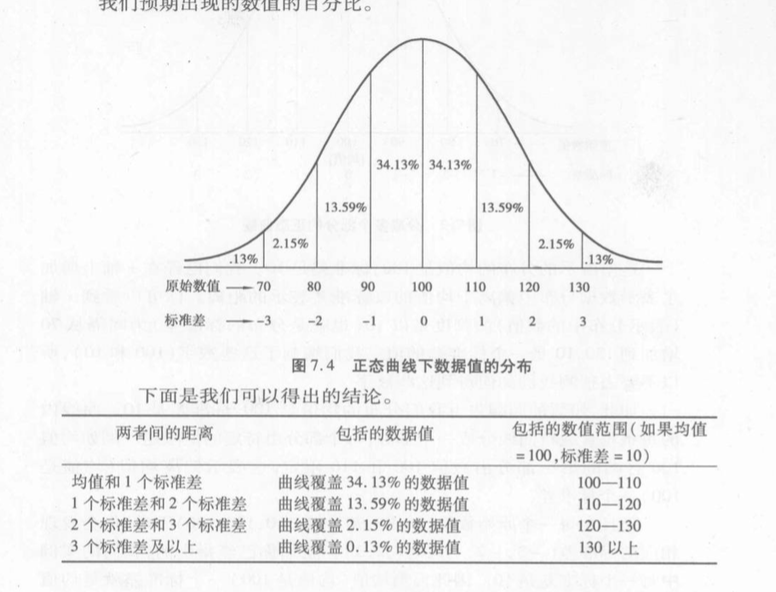
如果数据分布是正态的,那么曲线的不同面积可以用z值的不同数值来表示。
同时,不同的面积或者不同的z值,也可以表示特定数值出现的概率。
例如:N(100,10)中110以上数据出现的概率大致是16%。
标准值(例如z值)和标准差:标准值来源于预先确定正态分布群体的均值和标准差,进而得到该群体的数据分布。标准差是建立在样本上的分布参数的估计量度。
z值的真正作用:估计某件事情的概率。
首先,得到群体的预期概率水平,然后根据样本数据,判断所发生的事件是高于还是低于我们的预期概率水平。
研究假设提出了预期事件发生的命题,接着使用统计工具,在已知群体分布情况的基础上,计算相应的统计参数,估计事件发生的概率。
例如: 抛掷一枚硬币10次(做10次独立不重复试验,即这一次的实验结果不会影响下一次,independent identical),问题是出现多少次正面会认为这不是一块质地均匀的硬币?
答:
抛掷10次硬币正面的次数少于百分之5的范围被认为是造假的。5%是统计学家使用的标准。
如果一件事情发生的概率是极值(正面出现的次数,一次考试的成绩,两个数据组平均值的差异),那么被认为是不可能出现的结果。
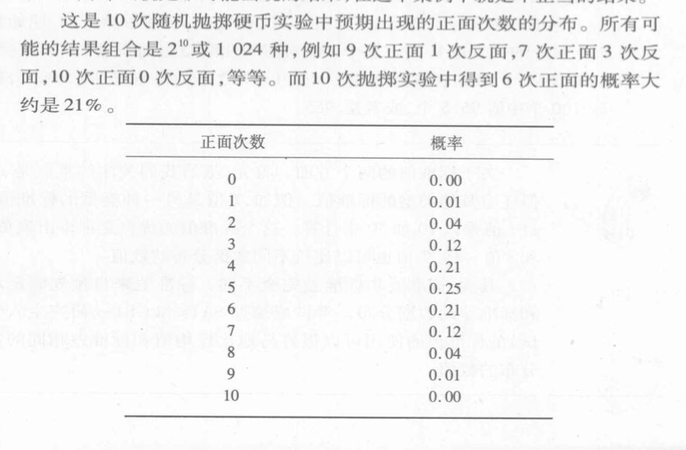
那么,正面次数多少判断硬币损坏故障或者伪造呢?
首先,选定我们的标准,低于5%的概率被认为是不可能事件。
所以,正面出现0、1、2、8、9、10被认为不可能事件。
同样地,对于z值。首先,确定群体的分布情况,然后确定要检验的概率范围,最后用基于样本的统计量与检验量对比,判断是否是不可能事件。
确立了零假设,然后努力检验出零假设中可能包含的错误。
换句话说,如果检验的z值是极值,那么该事件的发生并不是原有零假设的随机因素的结果,而是确确实实与某种关系或者某种处理方式有关。















 9178
9178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









