









2016年4月3日20:17:44
MapReduce程序开发中的FileInputFormat与TextInputFormat
作者:数据分析玩家
* which is then assigned to an individual {@link Mapper}.
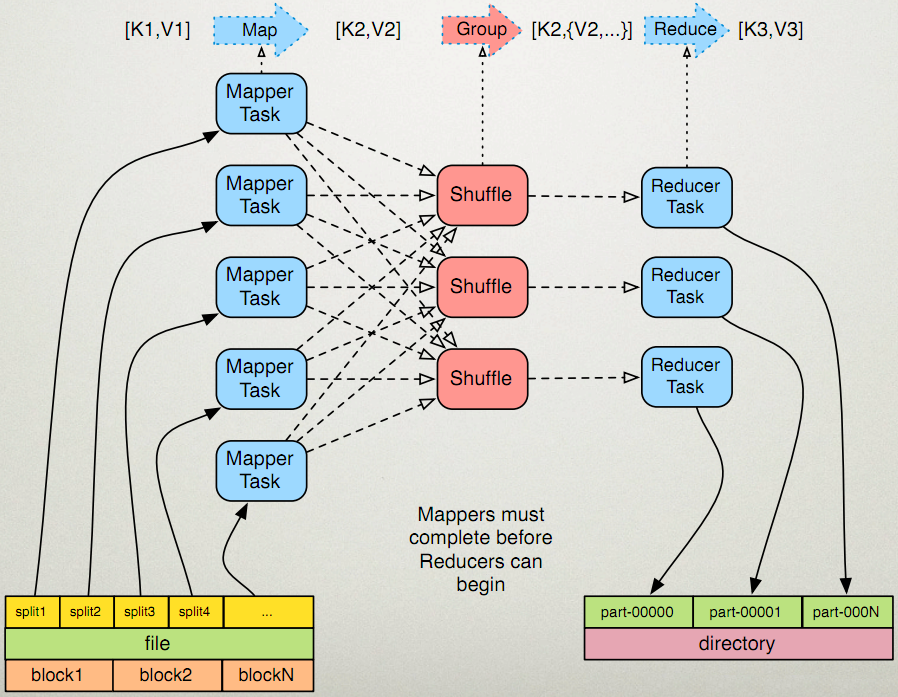
FileInputFormat这个类先对输入文件进行逻辑上的划分,以64M为单位,将原始数据从逻辑上分割成若干个split,每个split切片对应一个Mapper任务
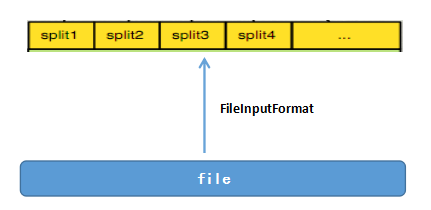
对于FileInputFormat这个类,我们需要注意:FileInputFormat这个类只划分比HDFS的block块大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.如果一个文件的大小比block块小,将不会被FileInputFormat这个类进行逻辑上的划分,此时每一个小文件都会当做一个split块并分配一个Mapper任务,导致效率低下.这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
当FileInputFormat这个类将文件file切分成block块之后,TextInputFormat这个类随后将每个split块中的每行记录解析成一个一个的键值对,即<k1,v1>.

综上:我们可以简单理解为FileInputFormat这个类是将文件file切分成split块,而TextInputFormat这个类是负责将每一行记录解析为键值对<k1,v1>.
2016年4月3日21:13:05















 9695
9695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











