







核心内容:
1、Spark中的pipline的再度思考
2、Spark中的窄依赖和宽依赖的物理执行内幕
3、Spark中的Job提交流程
今天又开始了我的Spark,好的,进入正题…….
回忆一下经典的WordCount程序:
package com.appache.spark.app
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hp on 2016/12/25.
*/
object WordCount
{
def main(args:Array[String]):Unit=
{
val conf:SparkConf = new SparkConf()
conf.setMaster("local") //指定Spark的运行模式为本地运行模式
conf.setAppName("WordCount")
val sc:SparkContext = new SparkContext(conf)
val lines:RDD[String] = sc.textFile("C:\\word.txt")
val words:RDD[String] = lines.flatMap(line => line.split(" "))
val pairs:RDD[(String,Int)] = words.map(word => (word,1))
val wordnums:RDD[(String, Int)] = pairs.reduceByKey((a, b)=>a+b)
wordnums.collect().foreach(line => println("单词是:"+line._1+"\t"+"数量是:"+line._2))
sc.stop()
}
}执行结果:
单词是:Spark 数量是:3
单词是:Hello 数量是:6
单词是:Java 数量是:1
单词是:Scala 数量是:1
单词是:Hbase 数量是:2
单词是:Hadoop 数量是:3spark-shell中产生的具体的RDD:
scala> wordnum.toDebugString
res5: String =
(1) ShuffledRDD[4] at reduceByKey at <console>:33 []
+-(2) MapPartitionsRDD[3] at map at <console>:31 []
| MapPartitionsRDD[2] at flatMap at <console>:29 []
| MapPartitionsRDD[1] at textFile at <console>:27 []
| /word.txt HadoopRDD[0] at textFile at <console>:27 []有向无环图:
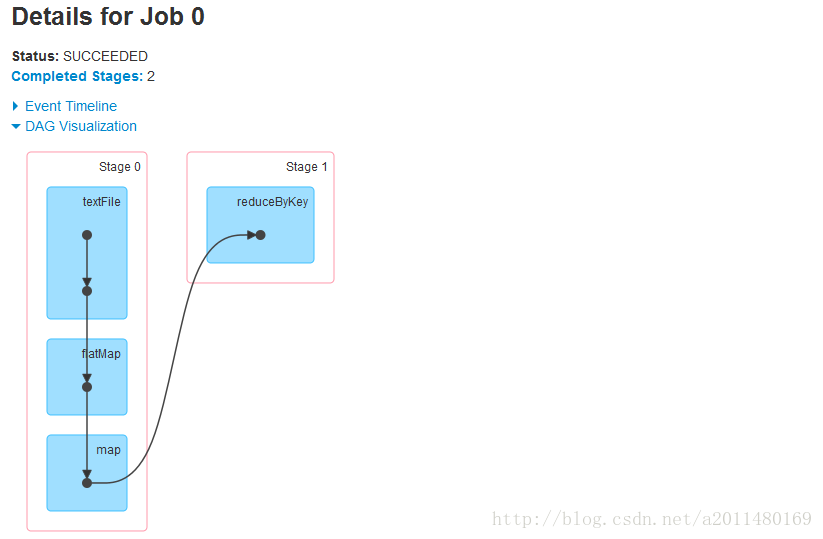
在Spark当中使用了pipeline的方式,函数f对依赖的RDD中的数据集合的操作也会有两种方式:
1、f(record) :即f这个函数作用于集合中的每一条记录,即每次只作用于一条记录。
2、f(records): 即f这个函数一次性作用于集合中的全部的数据。
Spark在实现的时候使用的是第一种方式,即Spark中的RDD在计算的时候每次计算的是一个Record记录。原因有以下几点:
1、无需等待,可以最大化的使用集群的计算资源。
2、减少OOM的发生,因为每次只算一个record。
3、最大化的有利于并发。
4、可以精准的控制每一个partition本身(Dependency)及其内部的计算(compute)。
5、基于lineage的算子流动式函数式编程,节省了中间结果的产生,并且可以最快的恢复(容错)。
其实根据我自己编程的感觉,Spark中的函数每次作用到的的确是RDD中的每一条记录,例如map函数:对RDD中的每一条记录进行指定的操作,并为每一条记录返回一个对象。其实我认为Spark这一点和Hadoop是相同的,因为MapReduce中的map函数的处理单位就是单行本文。
Spark的应用程序Application相当于一个资源申请的一个单位,我们在提交程序进行注册的时候,框架就已经为我们分配好了资源。(当然这里指的是StandAlone模式的粗粒度的资源分配方式,Mesos就是细粒度的,但是我们大多数考虑的都是粗粒度的资源分配方式)。
Spark的应用程序Application里面可以(不是一定)产生一个或者多个Job,例如Spark-shell默认启动的时候内部就没有Job,只是作为资源的分配的程序而已,可以在Spark-shell里面写代码产生若干个Job,普通程序中一般而言可以有不同的Action,每一个Action一般会触发一个Job。
Spark是MapReduce思想的一种更加精致和高效的实现,MapReduce思想有很多具体的不同的实现,例如Hadoop中的MapReduce包含两个阶段:Mapper阶段和Reducer阶段,用户只需要实现map函数和reduce函数即可实现分布式计算,非常简单。
Hadoop中的MapReduce虽然编程简单,但是存在很多问题:虽然MapReduce的编程过程非常简单,即Mapper+Shuffle+Reducer。但是随之带来的就是过程的死板,导致的问题是:Hadoop中的MapReduce在构造复杂多步骤迭代算法的时候会非常的麻烦,且执行效率即为低下。
Spark没有采用Hadoop中的MapReduce的这种方式,Spark最基本的思想是尽可能最大化的进行pipeline(因为pipeline越多的话,数据复用就越好,pipeline会最大化的基于内存,当然如果内存不够的话,pipeline也会部分基于磁盘)所以此时速度回非常的快。
正因为Spark是基于Pipeline的编程思想,所以在Spark当中,数据只有被使用的时候才开始计算。
在Spark当中,从数据流动的视角来说,是数据流动到计算的位置,从逻辑的角度来说,是算子在数据上流动。
但是从真正本质上来讲,肯定是数据在流动的,即数据从一个位置流动到另外一个位置(这个位置指的就是所谓计算节点,即算子的计算节点,当然都是在内存中的)。
上面这句话的理解方式:从算法构建的角度而言,肯定是算子作用于数据,所以是算子在数据上流动(例如我们平时编程的时候,考虑的就是将算法作用于数据),这种思考方式方便算法的构建。从物理执行的角度而言,是数据流动到计算的位置,这种方式方便系统最为高效的运行!
在Spark当中,对于Pipeline而言,数据计算的位置就是每个Stage中最后的RDD。即每个Stage中除了最后一个RDD算子是真实的以外,前面的算子都是假的,假的,假的!
举一个例子而言:假如有5000个步骤要计算的话,只有第5000个步骤要结果,为什么第5000个步骤要结果呢?因为第5000个步骤要计算一下,把它放在磁盘上供下一个Stage使用。所以此时就会进行算子合并,从后
往前推,多以就将5000个步骤的算子变成了一个步骤的算子,
注意:从本质上而言,Jvm根本不知道什么是RDD,RDD只不过是Spark搞的一套逻辑。在Spark当中,我们为了构建算法抽象出了RDD,我们基于RDD写算法、高阶函数编程、链式编程的方式等等。
由于计算的lazy特性导致计算从后往前回溯,形成Computing Chai即计算链条。导致的结果就是需要先计算Stage内部最左侧RDD中的需要的partition,当然,计算的过程中我们可以自己Cash一下。
深度思考:在Spark当中,一个Stage的一个partition都是在一个节点上执行的吗?是的,因为一个Stage的一个partition是由一个任务负责的,而一个Stage内部有很多的partition。
上面这些知识点我们可以概括为:
1、Spark中的RDD在计算的时候每次计算的是一个Record记录,即Spark中的函数每次只作用于RDD中的一条记录。
2、Spark是基于Pipeline的编程思想,所以在Spark当中,数据只有被使用的时候才开始计算,对于Pipeline而言,数据计算的位置就是每个Stage中最后的RDD。即每个Stage中除了最后一个RDD算子是真实的以外,前面的算子都是假的,假的,假的!
假设有1万个计算步骤:前面5000个步骤是一个stage,中间3000个步骤是一个Stage,最后2000个步骤是一个Stage。以第一个Stage为例,前面4999个步骤都是假的,因为如果没有第5000个步骤,前面4999个步骤都不会计算。而前面那么多步骤都是被最后一个函数通过函数这种编程的方式进行展开的,即5000个函数从从本质上讲就是一个函数。
好的,接下来我们讨论Spark中的窄依赖和宽依赖的物理执行内幕。
一个Stage内部的RDD之间都是窄依赖,从逻辑上看,窄依赖计算本身是从Stage内部最左侧的RDD开始立即计算的,根据计算链条,数据从一个计算步骤流动到下一个计算步骤,以此类推,直到计算到Stage内部的最后一个RDD来产生计算结果。
在Spark当中,计算链条的构建方向是从后往前回溯构建而成的,而实际的物理计算则是数据从前往后在算子上流动,直到数据流动到不能在流动的位置(即直到这个数据分片计算完了,才开始计算下一个计算分片)。这样就导致一个的结果:在Spark的窄依赖当中,后面的RDD对前面的RDD的依赖虽然是Partition级别的数据集合的依赖,但是并不需要父RDD把partition中所有的Recoreds计算完毕之后才整体往前向后流动数据进行计算,而是一个Recored一个Recored级别的进行计算,这就极大的提高了计算效率。
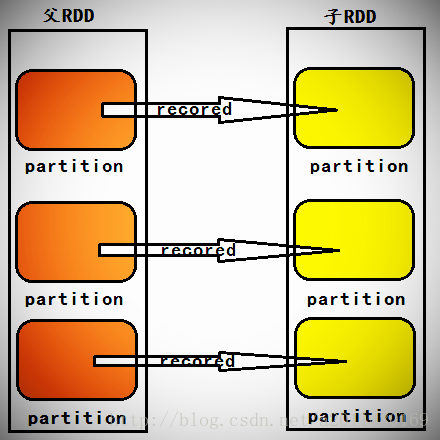
问题:所有的RDD的compute计算的时候是怎么做的?我们看一下源码:
/**
* An RDD that applies the provided function to every partition of the parent RDD.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
}
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
computeOrReadCheckpoint(split, context)
}
}从源码中我们可以看出是利用的iterator。
在Spark当中,宽依赖是非常简单的,即当前的Stage依赖于前面的Stage。宽依赖之间要进行shuffle操作,而且所依赖的父Stage中的数据必须全部计算完之后才能拿到数据。即必须等到依赖的父Stage中的最后一个RDD将全部数据彻底计算完毕之后,才能够经过Shuffle来计算当前的Stage!即父Stage中的所有数据必须首先计算完成。
写代码的时候要尽量减少宽依赖。
问题:在Spark当中,依赖的所有父Stage计算完成之后,是把全部的结果都拿过来之后在进行计算呢,还是拿一部分就进行计算呢?
一部分,其实这个答案同我们的MapReduce是一样的,在MapReduce的Reducer阶段,数据通过网络拷贝的时候,就是一边拷贝,一边对多个Mapper任务的输出进行合并的。
好的,接下来我们用一段话总结宽依赖和窄依赖:
在Spark当中,计算链条的构建方向是从后往前回溯构建而成的,遇到Shuffle级别的依赖的时候就会形成Stage,而实际的物理计算则是数据从前往后在算子上流动的。每个Stage内部每个RDD中的Compute通过调用具体的iterator然后将我们依赖的父RDD中的Recored一个一个的拿过来进行计算,如果有Shuffle的话,必须等到父Stage的所有内容都计算完之后才能拿过来数据。















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











