







核心内容:
1、Spark集群搭建与测试
2、粗粒度与细粒度的相关概念
今天学习了Spark的集群搭建,并进行了相应的测试工作,现将具体的过程进行整理:
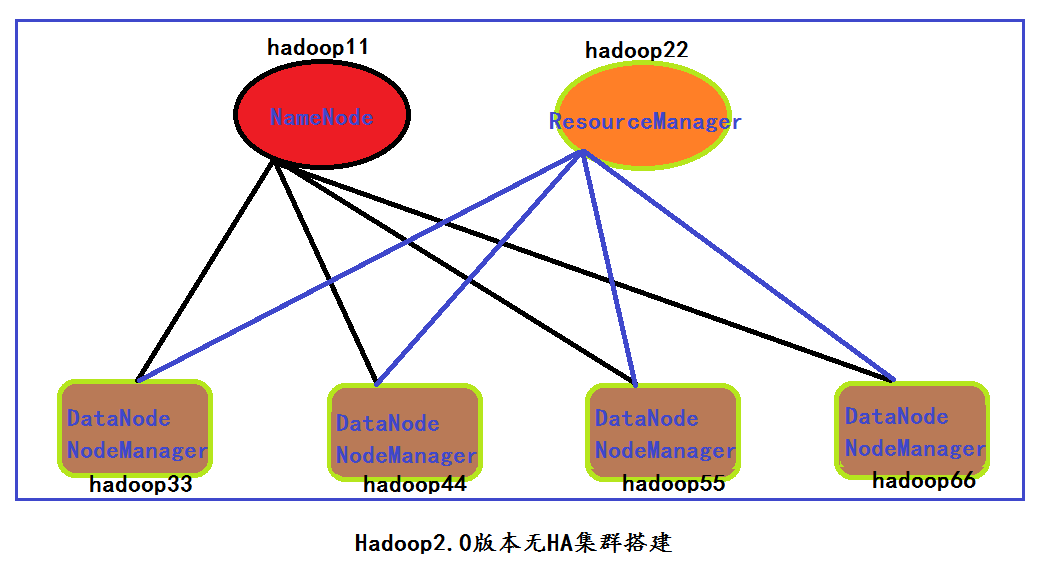
在搭建Spark集群之前,我在6台服务器上面已经将Hadoop集群搭建完成,集群角色分布如下所示:
集群DataNode情况:
Datanodes available: 4 (4 total, 0 dead)
Live datanodes:
Name: 10.187.84.53:50010 (hadoop44)
Hostname: hadoop44
Decommission Status : Normal
Configured Capacity: 52844687360 (49.22 GB)
DFS Used: 6135365632 (5.71 GB)
Non DFS Used: 7358754816 (6.85 GB)
DFS Remaining: 39350566912 (36.65 GB)
DFS Used%: 11.61%
DFS Remaining%: 74.46%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Tue Nov 15 21:33:16 CST 2016
Name: 10.187.84.55:50010 (hadoop66)
Hostname: hadoop66
Decommission Status : Normal
Configured Capacity: 52844687360 (49.22 GB)
DFS Used: 7938138112 (7.39 GB)
Non DFS Used: 9813864448 (9.14 GB)
DFS Remaining: 35092684800 (32.68 GB)
DFS Used%: 15.02%
DFS Remaining%: 66.41%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Tue Nov 15 21:33:15 CST 2016
Name: 10.187.84.54:50010 (hadoop55)
Hostname: hadoop55
Decommission Status : Normal
Configured Capacity: 52844687360 (49.22 GB)
DFS Used: 5711171584 (5.32 GB)
Non DFS Used: 7270424576 (6.77 GB)
DFS Remaining: 39863091200 (37.13 GB)
DFS Used%: 10.81%
DFS Remaining%: 75.43%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Tue Nov 15 21:33:16 CST 2016
Name: 10.187.84.52:50010 (hadoop33)
Hostname: hadoop33
Decommission Status : Normal
Configured Capacity: 52844687360 (49.22 GB)
DFS Used: 4032651264 (3.76 GB)
Non DFS Used: 7934386176 (7.39 GB)
DFS Remaining: 40877649920 (38.07 GB)
DFS Used%: 7.63%
DFS Remaining%: 77.35%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Last contact: Tue Nov 15 21:33:16 CST 2016
从上面中可以看出,Hadoop集群已经成功搭建完成,接下来介绍Spark软件的具体的下载过程:
Spark官网地址:http://spark.apache.org/
现在我已经下载好了,百度云盘地址:http://pan.baidu.com/s/1i5bkZGD
接下来具体介绍spark的在Linux上的安装过程:
1、解压缩、重命名、修改环境变量

2、修改配置文件
spark-env.sh
export SCALA_HOME=/usr/local/scala
export JAVA_HOME=/home/hadoop/jdk1.7.0_25x64
export HADOOP_HOME=/usr/local/hadoop
export SPARK_MASTER_IP=10.187.84.50
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
相应说明:
JAVA_HOME 指定 Java 安装目录;
SCALA_HOME 指定 Scala 安装目录;
HADOOP_HOME指定Hadoop的安装目录;
SPARK_MASTER_IP 指定 Spark 集群中 Master 节点的 IP 地址;
SPARK_WORKER_MEMORY 指定的是 Worker 节点能够分配给 Executors 的最大内存大小;
HADOOP_CONF_DIR 指定 Hadoop 集群配置文件目录(Spark运行在YARN集群上必须)
slaves
hadoop33
hadoop44
hadoop55
hadoop66spark-defaults.conf 该配置文件可以记录程序运行时的相关信息
spark.master spark://hadoop11:7077
spark.eventLog.enabled true
# Namenode
spark.eventLog.dir hdfs://hadoop11:9000/sparkHistoryLogs
# Master
spark.history.fs.logDirectory hdfs://hadoop11:9000/sparkHistoryLogs
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
到此,Spark集群配置完成,是不是非常简单,接下来启动Spark集群:
[root@hadoop11 ~]# start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop11.out
hadoop66: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop66.out
hadoop33: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop33.out
hadoop55: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop55.out
hadoop44: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop44.out
接下来启动start-history-server.sh 在主节点上面启动就可以
[root@hadoop11 conf]# jps
36094 HistoryServer
19114 SecondaryNameNode
35706 Master
18928 NameNode
36244 Jps
可以看出,集群已经正常启动。
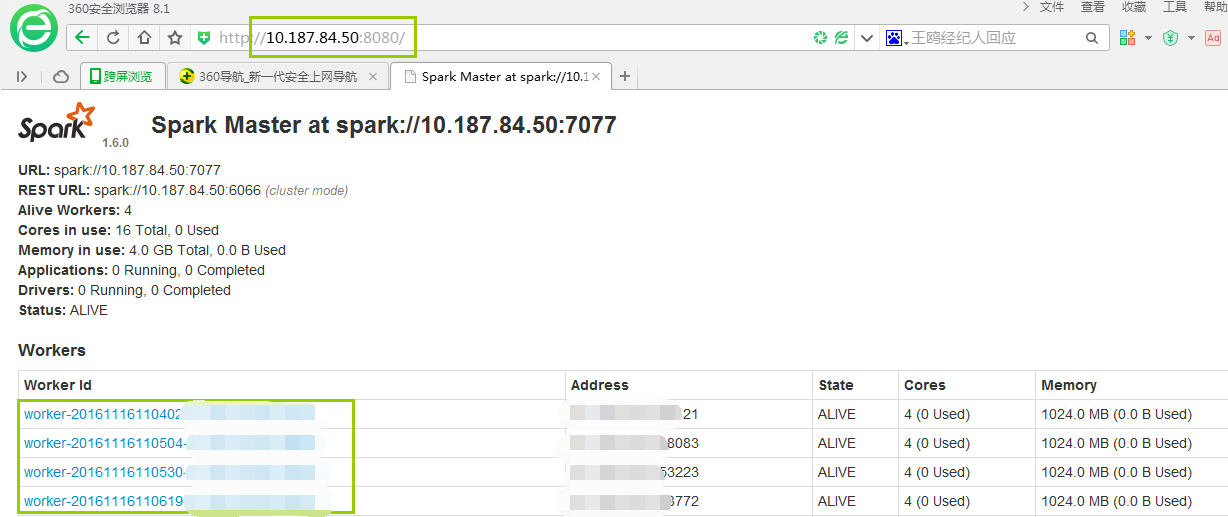
通过8080端口查看集群启动情况:
通过18080查看spark日记记录:
接下来进行集群功能测试:
先查看HDFS中的文件:
[root@hadoop11 mydata]# hadoop fs -cat /word.txt
hello you
spark hadoop
java scala
java hello
启动spark-shell:
运行命令:
scala> sc.textFile("hdfs://hadoop11:9000/word.txt").flatMap(_.split(" ")).map(word =>(word,1)).reduceByKey(_+_).map(pair => (pair._2,pair._1)).sortByKey(false,1).map(pair=>(pair._2,pair._1)).saveAsTextFile("hdfs://hadoop11:9000/dirout/")
查看运行结果:
[root@hadoop11 mydata]# hadoop fs -lsr /dirout/
lsr: DEPRECATED: Please use 'ls -R' instead.
-rw-r--r-- 3 root supergroup 0 2016-11-15 21:55 /dirout/_SUCCESS
-rw-r--r-- 3 root supergroup 58 2016-11-15 21:55 /dirout/part-00000
[root@hadoop11 mydata]# hadoop fs -cat /dirout/part-00000
(hello,2)
(java,2)
(scala,1)
(spark,1)
(you,1)
(hadoop,1)
接下来我们通过spark-shell提交程序:
[root@hadoop11 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop11:7077 spark-examples-1.6.0-hadoop2.4.0.jar
运行结果:

接下来谈一下粗粒度和细粒度的相关概念:
粗粒度:在任务启动初始化的那一刻就分配好资源了,后续程度启动的时候直接使用资源计算就可以了,而不用每次任务计算的时候在分配资源。
细粒度:就是任务在计算的那一刻需要资源的时候在给你分配,然后计算完成后在将给你的资源进行回收。
简单来说,粗粒度就是先分配资源,而细粒度就是在计算的时候在分配资源。
粗粒度的好处与缺点:如果作业特别多,并且要进行资源复用的话,此时就特别适合粗粒度,坏处是计算资源的浪费。
细粒度不存在资源浪费的问题,但启动会有麻烦。
OK,明天继续努力!
















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











