







本文内容属于 Andrew Ng的《机器学习》公开课笔记,大部分截图均来自Andrew Ng的课件
对于本节所讲的算法,Andrew Ng称为 Collaborative filtering(协同过滤),或者low rank matrix factorization(xx矩阵分解),项亮博士《推荐系统实践》那本书里叫做 LFM(隐语义模型)
上一篇博客说道
基于内容的推荐 ,但是内容矩阵怎么来?一种方法就是用大量的人力去填。而Collaborative filtering 正是这样一种代替人工的方式。
回顾一下,基于内容的推荐,是已知y和X,求theta。如果我们已知y和theta,就可以求X。

于是,如果给theta一个初始化很小的值,可以来回利用上面两个式子,对X和theta进行求解。
我们伟大的前辈发现了一种更好的方法,就是把两个 linear regression合并,如下图

合并后,我们的最优化目标就从
J(theta) 和 J(X)变成了 J(theta,X)
算法描述如下

在这里,我们不需要 k = 0的特殊情况了,因为我们不需要手动添加 x=1这个元素。如果需要x=1,协同过滤算法会自己算出一个 x=1。算法描述到此为止。
1,为什么该算法也叫做 矩阵分解算法呢。见下图
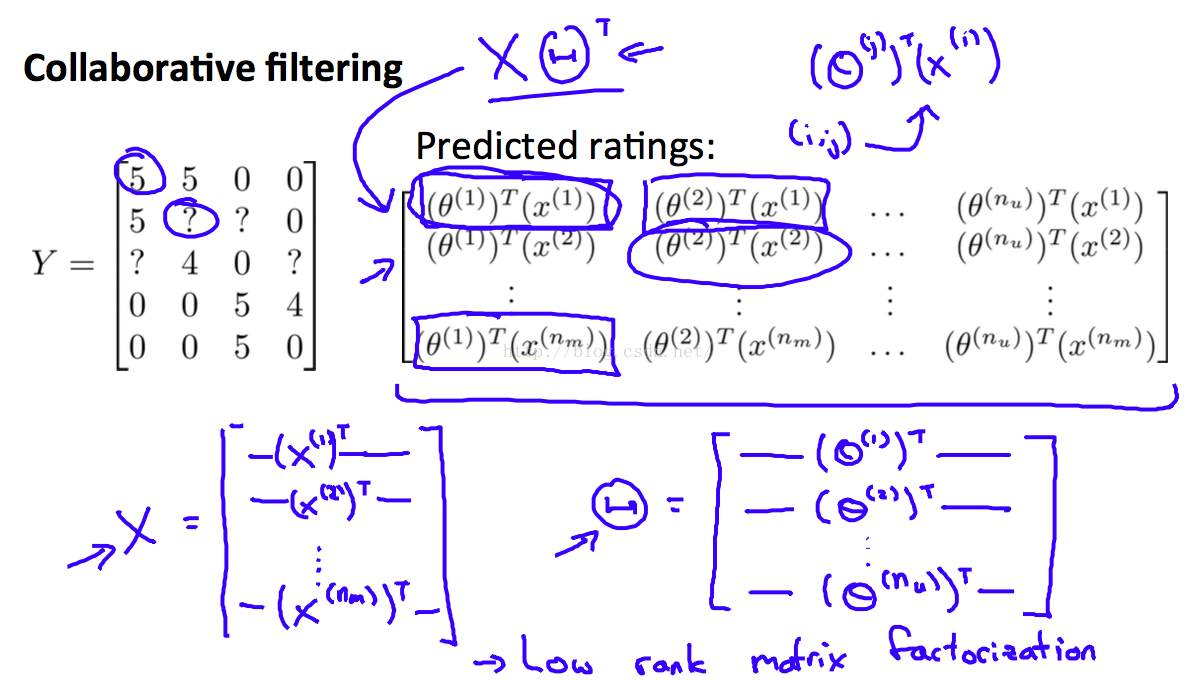
我们把 Y矩阵,转换成了 Theta和X两个矩阵的乘积
2,怎么找到与 movie i最相似的5个movie呢?
计算距离
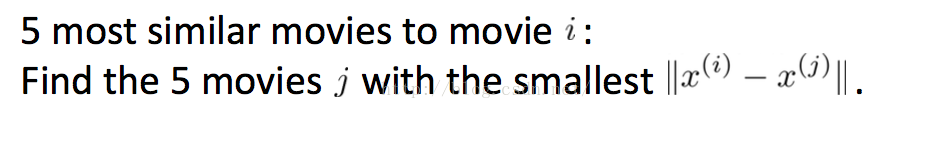
这个距离可能很大。更好的计算距离或者说相似的的方法有 皮尔逊相似度,余弦相似度,欧拉距离相似度等等,这些相似度的取值范围都在 -1~1之间
3,如果一个用户是新来的,没有任何评分记录,怎么给他推荐?
Andrew Ng推荐 mean normalization 方法
如果一个用户没有评分记录,那么用 CF方法算出来的评分都是0。没什么价值,还不如给他一个平均值。具体实现见下图
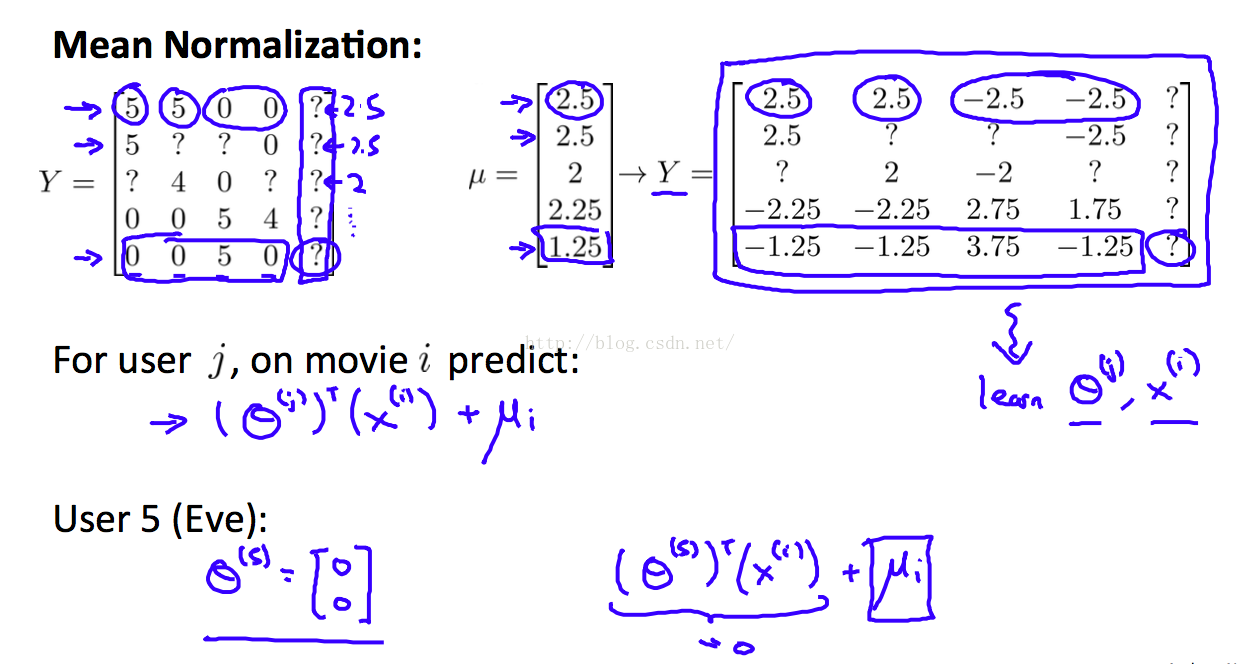
计算出每部电影的评分平均值。然后把所有的评分都减去平均值进行计算。算出来的结果再加上平均值。
这样做其实对有评分记录的用户是多余的。但是却可以把没有评分记录的用户给 统一 进来!
-------------割-------------
节目预告:下一节要讲 logistic regression 和 regulization。因为是复习,所以没按大纲走















 1132
1132

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









