









内容大概:
- 简单介绍python如何下载网页
- 发送post请求
- urllib/2模块的方法应用
- 分析网页的post请求
- cookie处理
- 利用BS分析网页
(由于并没有系统的学过http之类的,可能会有错误,希望大家可以指出)
urllib&cookielib:
urllib模块只用到了urlencode方法,目的是将原来的字典post数据转化成特定的字符串格式,只用到了下面的一行代码。
post_data = urllib.urlencode(post_data)urllib2用到的就多了,首先模拟登陆的话需要用到cookie处理。
主要用到以下代码,固定格式,拿来用就好了。
#安装cookie处理
cj = cookielib.CookieJar()
cookie_support = urllib2.HTTPCookieProcessor(cj)
opener = urllib2.build_opener(cookie_support)
urllib2.install_opener(opener)然后设置一下自己的hears,目的是把自己伪装成一个浏览器。
导入这里的各种参数可以设置成别的,这里只是例子,具体改成什么可以打开浏览器的开发者模式看一下。
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36',
'Referer': 'http://acm.sdut.edu.cn/onlinejudge2/index.php/Home/Login/login',
'Host': 'acm.sdut.edu.cn'}
然后设置打开网页时需要的request,需要用到url,post请求的数据,headers,当然这一步也可以跳过,单纯下载网页的话只用url就可以了。
request = urllib2.Request(url, post_data, headers)接下来就是重要的打开网页,用到了urllib2的urlopen方法,参数可以是只是网页,也可以是一个之前说到的request。
#以下两种都可以
response = urllib2.urlopen(request)
response = urllib2.urlopen(url)最后一点是response对象使用read方法就可以得到下载的html文本了。
response.read()post请求的分析:
这里拿登陆OJ来做下示范。
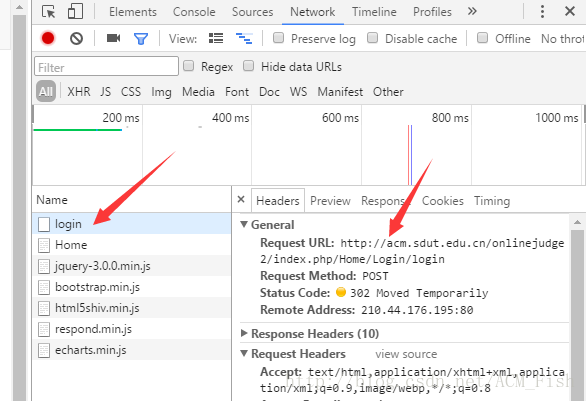
首先打开登陆页面自己打开F12登陆一次。
然后注意箭头上指的两处,点下login后,右边的Request URL就是接下来将要用python访问的页面。
然后继续往下滑,下面箭头的部分就是自己提交的数据,也是接下来post_data里要放的内容。
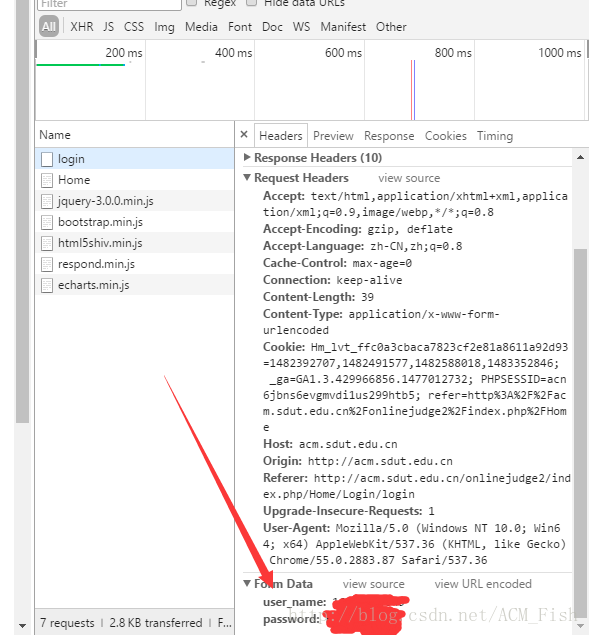
于是登陆的过程我就可以这样写了(假设安装了cookie处理,定义了headers)
url = 'http://acm.sdut.edu.cn/onlinejudge2/index.php/Home/Login/login'
post_data = {'user_name': user, 'password':password }
request = urllib2.Request(url, post_data, headers)
response = urllib2.urlopen(request)BeautifulSoup:
强烈推荐官方文档,有中文!有中文!!有中文!!!
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
首先明确一点,BS就是分析html的文本,按照一种树形的结构,每一个节点都可以拿来当一个bs对象使用。
首先创建一个bs对象先。
(这里用了html5lib解析器,具体可以百度去下载安装,另外python装好pip的话安装第三方库很方便的。当然这里也可以不要第二个参数,这样的话就会默认使用python自带的)
soup = BeautifulSoup(html, "html5lib")然后是bs对象的find_all和find方法,find方法返回的是第一个匹配到的节点(bs对象),find_all则是返回一个列表(包含bs对象的列表),里面包含所有匹配的节点,如果没用匹配的节点的话,分别是None和[](空列表)。
他们都有name, class_, text参数(其实还有很多,这里我只用了这些基本的)
分别代表是节点名字,节点的class内容,和节点的文本。
下面只是一个示例,当然可以多个参数放在一起。
soup.find(class_ = 'next')
soup.find_all('tr')
soup.find(text = "Fish")
bs对象还可以直接访问他的节点的属性,父节点和子节点,当前这个节点的文本。
(假设a是他的子节点的话)
soup['href']
soup.parent
soup.a
soup.text介绍了这些,然后以下就是一些综合应用的示例了,总之BS是非常好用,刚开始我以为得用到正则表达式…
#从ranklist找到自己的status
url = 'http://acm.sdut.edu.cn' + soup.find(text = "Fish").parent.parent.find_all('td')[2].a['href']
#找到页面的下一页的超链接
url = 'http://acm.sdut.edu.cn/' + soup.find(class_ = 'next')['href']
#找到每一个AC记录的代码链接
tr = tr.find_all('td')
if tr[3].text == "Accepted" and (tr[6].text == "g++" or tr[6].text == "gcc"):
temp = 'http://acm.sdut.edu.cn/' + tr[6].a['href'], tr[2].a['href'][-9:-5]













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









