







数据驱动(总结)
RIDE提供的库:
自定义库:DataCenter.py
一、数据驱动测试
注重于测试软件的功能性需求,也即数据驱动测试执行程序所有功能需求的输入条件。
二、总结:根据数据源,灵活地实现KISS。
- 数据较少
数据比较少的时候,可以使用 Create List, Get File & Import Variables。
创建 List 最快捷、最简单,但是处理多维列表就比较麻烦。如何创建多维列表,请查看齐道长的博客。

从 File 获取数据需要自己封装关键字,把原始数据处理并存储为列表。可以处理稍微复杂的数据,不过 File 存储的数据本身格式并不直观。
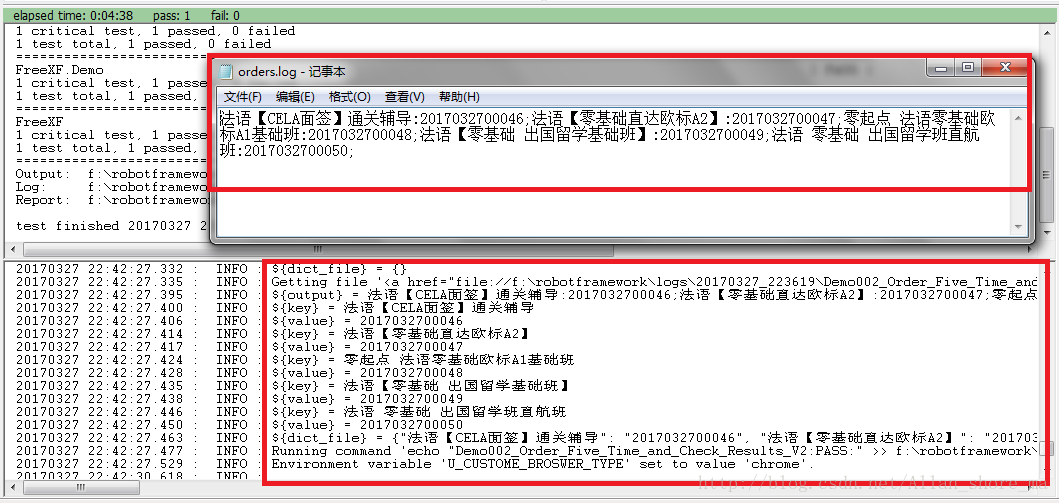
Import Variables 和 Create List 类似。相比 Create List,Import Variables 较灵活。因为 Import Variables 可以直接创建多维列表。
list1 = [[['grade1'], [5, 2, 3, 4], [6, 1, 7, 8]], [['grade2'], [1, 2, 3, 4], [5, 6, 7, 8]]]如果数据较少,比 Get Sheet Values From Excel 跟灵活。例如,在 Get Sheet Values From Excel 方法中的实例就需要把三维列表转换为二维列表。三维列表是从网页上获取并存储的数据。
def Reorgnize_List(self, alsit):
newList = []
for element in alsit:
if isinstance(element, list):
for el in element:
newList.append(natsort.natsorted(el))
OrderedData = natsort.natsorted(newList)
return OrderedData
if __name__ == '__main__':
obj = main()
list1 = [[['grade1'], [5, 2, 3, 4], [6, 1, 7, 8]], [['grade2'], [1, 2, 3, 4], [5, 6, 7, 8]]]
list2 = obj.Reorgnize_List(list1)
print list2测试新的二维列表与 Excel 中读取的数据保持一致。
list1 = [[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1431
1431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









