









空间分析里面,最重要的一个概念就是距离,不同的距离会导致不同的结果。在研究的时候,有种叫做“空间尺度”的概念,这个有兴趣的话,请自行百度(老规矩:百度知道的东西别问我)。
所以,在研究聚类的时候,最重要的就是确定不同数据之间的距离,否则就会如下:
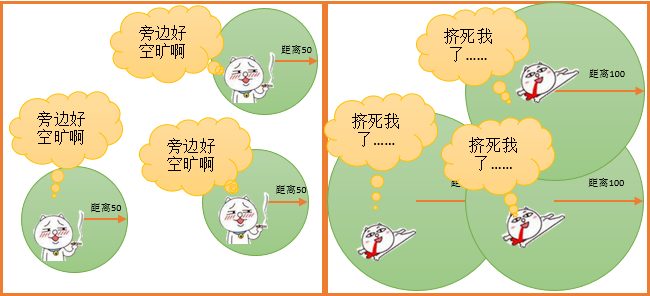
聚类分析中,要素之间的距离是个很重要的参数;也就是说两个要素相隔多远才算是聚成一类呢?在任何一种聚类算法中,探索一个合适的距离,都是比较纠结的事情。专家提出了各种算法,都想要优化这个距离探索的过程,以便有效的降低计算开销。
同样一份数据,在不同的距离上,表现出来的聚类效果肯定是不同的,所以我们今天来说一个灰常灰常神奇的工作,他不同于其他的分析工具的单一距离分析,他可以汇总在一定距离内所有数据的相关性进行汇总,以供我们选择适当的分析比例。
首先我们来看Ripley's K函数是个什么东西。Ripley's K方法是一种点数据模式的分析方法,它可以利用Ripley's K函数对点数据集进行不同距离的聚类程度分析,如下图所示:
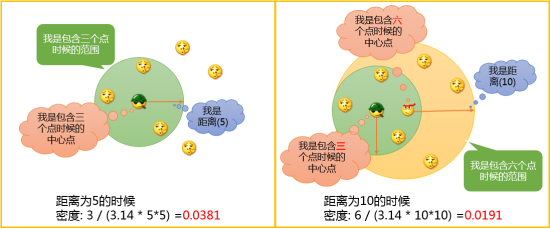
当距离为5的时候,要素的质心的位置和密度如左图所示,当距离扩大为10的时候,质心和包含的要素数量都会发生变化,那么数据的密度也会随之变化。
所以,Ripley's K函数就是用来表明这批要素的质心的空间聚集或空间扩散的程度,以及在邻域大小发生变化时是如何变化的。
我们来看看这个算法的基本原理。
首先我们要设定一个起算距离,当然,还可以指定最终距离或者增量步长,如开始为5,然后每次计算增加3这样的。计算的距离增加的时候,包含的相邻的要素自然就会原来越多,那么就可以针对不同的距离,去计算包含的数据的密度。
当全部算完之后,把每个距离的密度进行一下算数平均,并且用这个平均密度,作为用于比较的标准密度值。
然后用每个距离里面,包含的数据量的密度,来与标准密度值进行比较。大于标准密度,那么我们就认为这个距离上,数据处于聚类分布,而小于标准值的,我们就认为他处于离散分布。如下图所示:
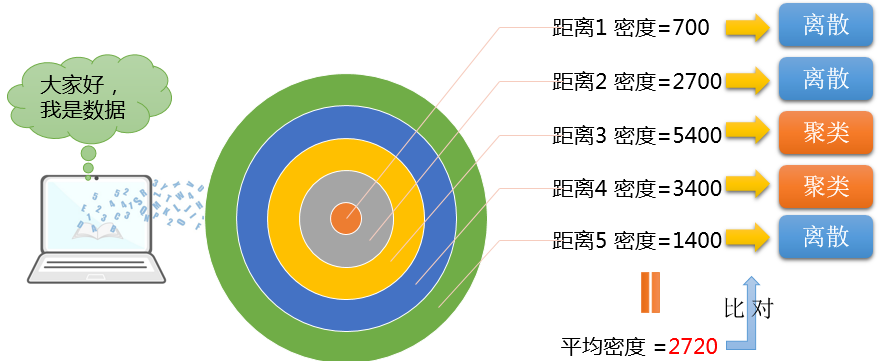
从上图可以看见,整个数据分布,其实不是线性,而这种所谓的离散或者距离,更多的是一种定性的说法,至于哪个距离上聚集效果好,哪个程度上离散程度大,一般是通过观察k值和预期k值进行比较得来的。
所谓的观察k值,指的是我们计算出来的实际密度值,而预期k值,指的是在随机分布的情况下,预期的分布情况。
有的同学就要问了,不是用的平均密度来进行比较么?这个预期K值和随机分布又是什么鬼?
平均值的问题,前面我们已经一而再再而三的说过了,虽然他简单好用,但是他的优点和缺点一样的明显,在描述算法的时候,可以用平均值来进行描述,但是实际使用中,平均值暴露出来的各种问题,会让分析人员为之抓狂。特别是在空间分布研究的时候。如果仅仅用平均密度来研究具有空间分析的数据,会出现如下问题:
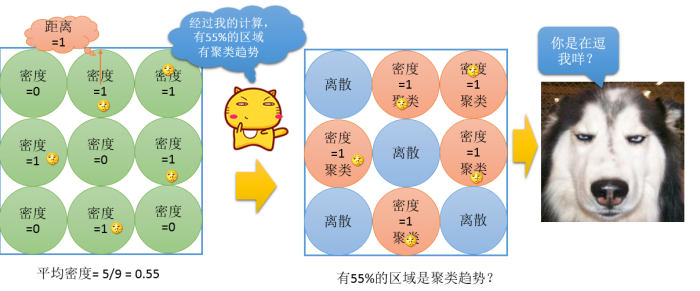
所以为了避免平均数带来的一些简单粗暴的计算,在研究空间分布的时候,更多是利用零假设的方式,来设定随机数进行分布,作为预期值。
实际上,研究的方式是这样的:
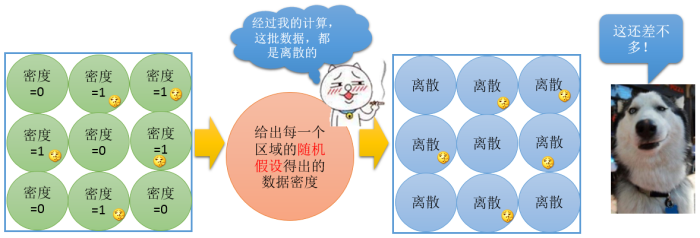
在每个研究区域内,都进行随机假设,也就是独立的将每个研究预期中都采用零假设的方式设定期望值,这样的话就可以避免上面那种整体平均数出现的错误了。
所以,整个算法,在计算完成之后,会生成两个数据,一个叫做“观测K值”,一个叫做“期望K值”,他们的特点如下:
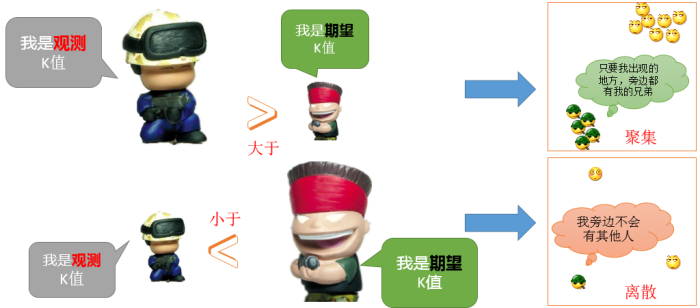
如果特定距离的 K 观测值大于 K 预期值,则与该距离(分析尺度)的随机分布相比,该分布的聚类程度更高。如果 K 观测值小于 K 预期值,则与该距离的随机分布相比,该分布的离散程度更高。
当然,前面我们在解释零假设的时候,说了任何的假设,最好需要设立一个置信度,就如同前面说的,进行验证的时候,首先就要决定我们来抛多少枚硬币,费希尔爵士也总结出了一个5%的规律。
当然,你也可以不设置置信度,这样的话,就表示怎么计算都行,只要得出结果就好了。
而效果比较好的,当然就是要设置一下执行度了。
在这个算法里面,确定期望K值时候,是要通过设立随机数来实现的,也就是说,你有100个数据,我就要生成100随机数,然后随机的分布在你的研究区域中,用这个随机分布的假设,来验证你的数据。
因为是随机数,所以放置这些随机数的时候,你也无法确定到底扔在那个地方,有可能都扔在一堆了……所以最好的方法,就是多设立几组随机数,多放置几次,以获得最佳效果。那么设立多少组随机数比较好呢?理论上来说,当然是越多越好,但是实际上不可能搞得非常多。在ArcGIS提供的多距离空间聚类分析 (Ripley's K 函数) 工具里面,给了“Compute_Confidence_Envelope”(计算置信区间)这样一个参数,一共给出了4个选项:
- 0_PERMUTATIONS_-_NO_CONFIDENCE_ENVELOPE —不创建置信区间。
- 9_PERMUTATIONS —随机放置了 9 组点/值。
- 99_PERMUTATIONS —随机放置了 99 组点/值。
- 999_PERMUTATIONS —随机放置了 999 组点/值。
其中:9 表示 90%,99 表示99%,999 表示 99.9%。
使用了这个参数之后,算法还会计算出LwConfEnv和 HiConfEnv这两个数据,他们分别表现每个迭代计算(由距离段数量参数指定)的置信区间信息。
如果观测K值大于 HiConfEnv 值,则该距离的空间聚类具有统计显著性。如果观测K值小于 LwConfEnv值,则该距离的空间离散具有统计显著性。
具体这个算法进行计算以及其得出的结果和具体解读,我们在下篇文章继续。
待续未完。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











